【学习】focal loss 损失函数
focal loss用于解决正负样本的不均衡情况
通常我们需要预测的正样本要少于负样本,正负样本分布不均衡会带来什么影响?主要是两个方面。
- 样本不均衡的话,训练是低效不充分的。因为困难的正样本数量较少,大部分时间都在学习没有用的负样本。
- 简单的负样本可能会压倒训练,导致训练退化。比如10000个人里面只有10个人为正义发声,其余的人都为邪恶发声,那么正义的声音就会被邪恶的声音淹没。
比如假如一张图片上有10个正样本,每个正样本的损失值是3,那么这些正样本的总损失是10x3=30。而假如该图片上有10000个简单易分负样本,尽管每个负样本的损失值很小,假设是0.1,那么这些简单易分负样本的总损失是10000x0.1=1000,那么损失值要远远高于正样本的损失值。所以如果在训练的过程中使用全部的正负样本,那么它的训练效果会很差。
focal loss的公式
首先看交叉熵损失函数:
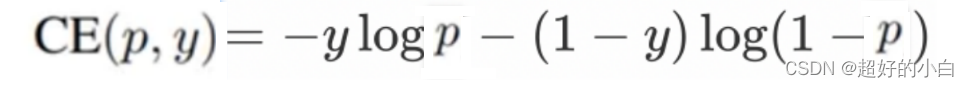
其中,y是样本的标签值,而p是模型预测某一个样本为正样本的概率,对于真实标签为正样本的样本,它的概率p越大说明模型预测的越准确,对于真实标签为负样本的样本,它的概率p越小说明模型预测的越准确,
上面公式可以变化如下:
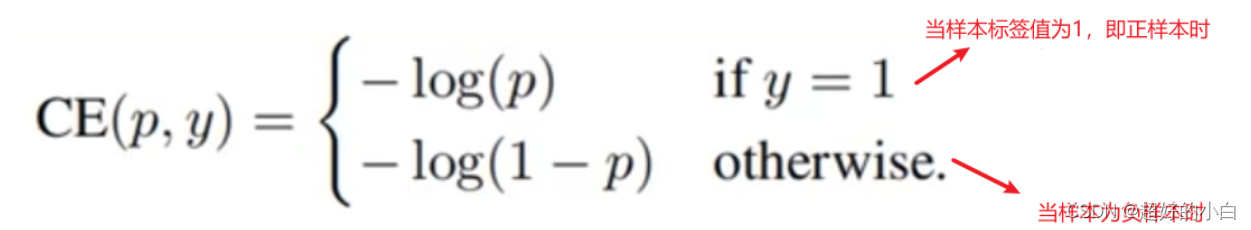
注意:这里的log(x)其实就是ln(x)
如果我们定义Pt 为如下形式:
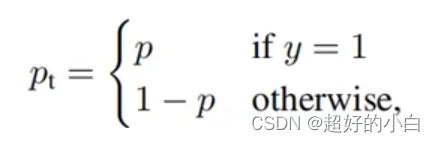
那么公式可以继续转化为:
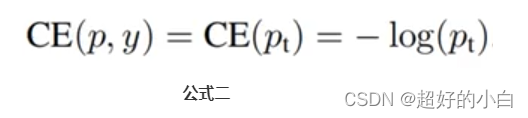
而对于focal loss来讲,就是要解决正负样本的权重问题。
focal loss 公式:
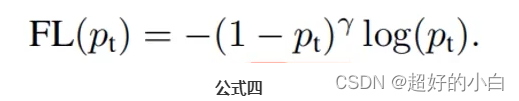
focal loss为什么起作用

参考b站:https://www.bilibili.com/video/BV1YX4y1J7Te/?spm_id_from=333.788&vd_source=4564794c2a933ffdf65d980ee25648f1