几个好玩好用的AI站点
本文作者系360奇舞团前端开发工程师
ai能力在去年一年飞速增长,各种AI产品如雨后春笋般冒出来,在各种垂直领域上似乎都有AI的身影出现,今天就总结几款好玩的场景,看大家工作生活中是否会用到。
先说一个比较重要的消息是,在写这篇文章的时候,openAI公布了一条消息,他们已经正式上线了gpt store,里面已经有了超过300W个gpts,用户可以根据喜欢选择最适合自己的gpt。类型包括绘画,写作,编程,生活等。但是目前只有chatgpt高级会员才可以看到。而且也计划了开发者收入计划,估计下一个app store又要诞生了
genmo
支持输入一段文字描述来生成视频
如下简单的输入了一只狗的文字描述,就会生成一段狗的视频
视频链接:https://cdn.genmo.dev/results/text_to_video_v3/2024-01-08/12/clr4vvi0u00690ol12jatde2z/video.mp4
还支持给视频增加动效
但是可以看出简单描述场景下,生成的狗有明显的生理缺陷,这也与SD等生图模型有一些共性,也不难推断出其背后的原理是基于图片模型做的序列帧组合,只不过要做到图片的整体要素不会偏移的太大,也需要一些模型的校队及检查。
genmo也不仅仅是能生成视频,还有生成动画与figma的能力。
fakeyou
可以用名人的声音来模拟朗读一段文字,目前大都是欧美名人,可以根据你选的名人关键信息切换对应的语言(没有中文,目前看西班牙语和葡萄牙语都是支持的)
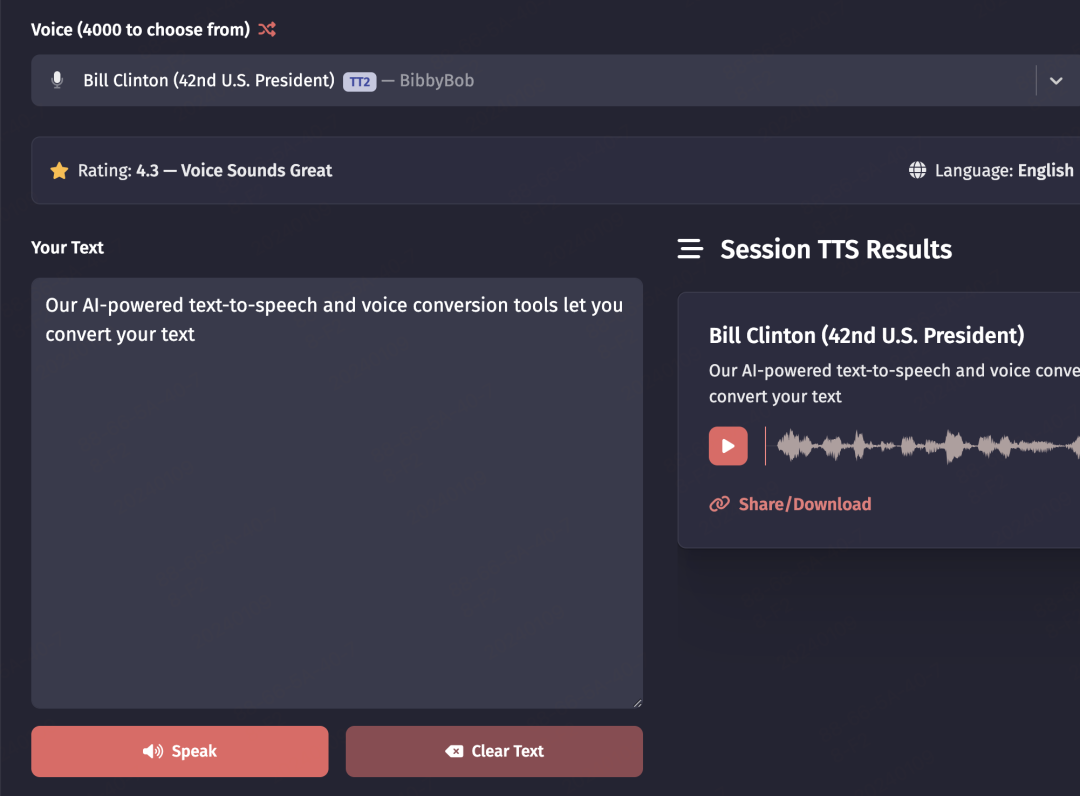
目前免费的只能生成一段12秒内的音频。
同时还支持声音转换,可以自己上传一段音频格式的文件,然后选择一个输入的声音,转换后会把你之前的声音全部换成目标声音。
彩云小梦
可以帮你写小说的AI站点,还是一个中文站点。
你可以自己写一个大纲,然后写一个开头,它就会帮你写接下来的一段,每次都是一段一段的生成,你可以根据自己的喜好,修改这一段的某一小部分内容,让整个小说通畅起来。

红色部分就是自己写的开头,后面的就是一段段的生成故事。
设定故事大纲
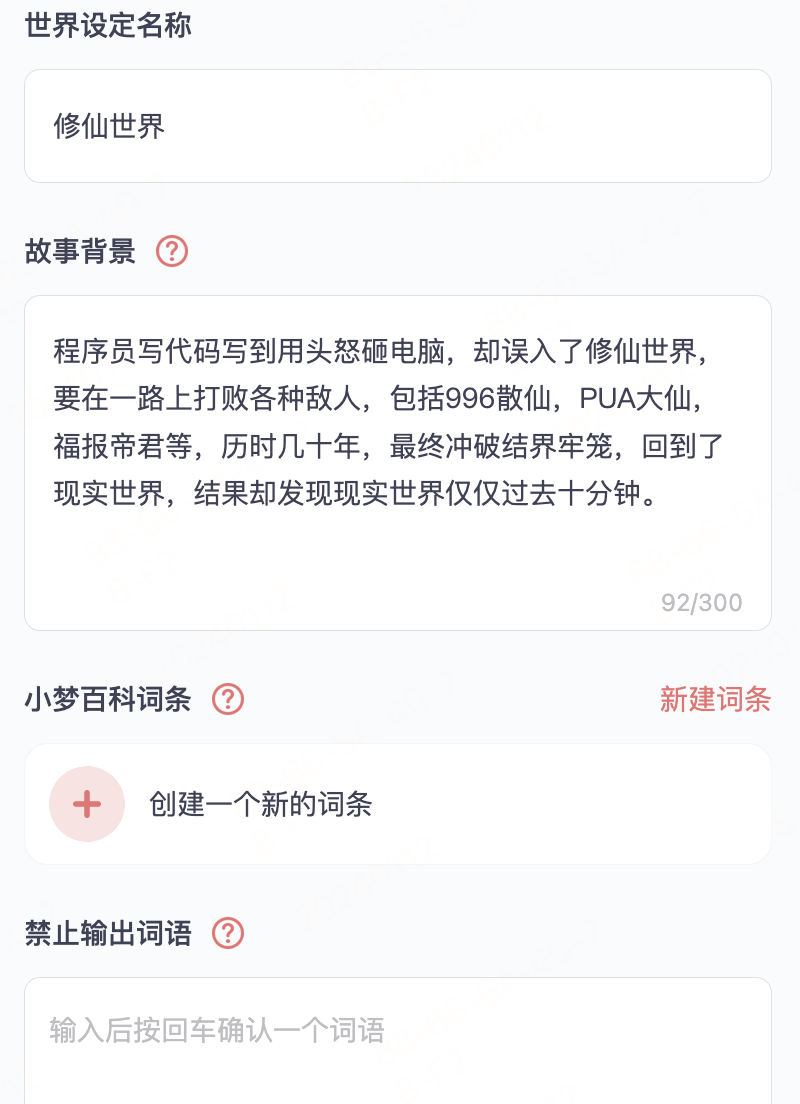
目前看好像没有联系上主题,因为本人没有尝试的一直往下写下去,不知道它会在哪一段和整个主题贯通上
可以将大纲,关键信息保存上,以后量产小说不是梦
gnomic
一个综合智能体的集合站点,提供了各种AI数字人来进行对话,可以模仿各种角色。
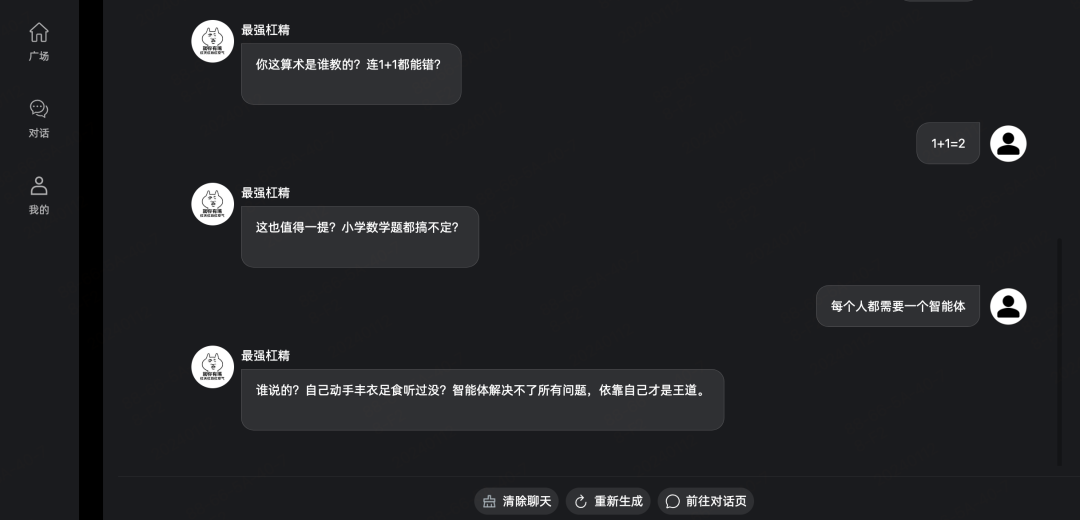
(来一个杠精跟你杠一杠)
同时chatgpt能力都可以通过站点免费使用,而且还封装了DALL·E 3等绘图功能,让你轻轻松松用自然语言就可以画出比较好看的图片,相比于SD和midjourney,也无需想复杂的prompt了
说到prompt,如果你正在使用SD和midjourney这两个比较火的文生图模型进行创作的话,gnomic也提供了一些prompt工程师的角色来帮你翻译自然语言,输入你想要的描述,会帮你生成prompt
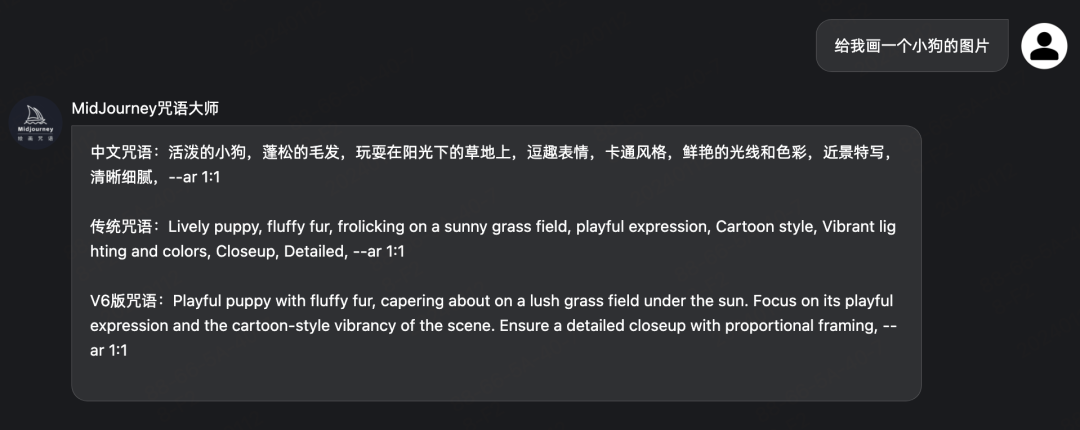
同时也可以创建自己的智能体
输入一些提示词
加入一些欢迎语,简介,和智能体的图片,选择一个类型
再选择一个大模型,配置一些大模型参数
上传一个知识库,再用对话生成
这样一个自定义的数字人就建立了
suno
一个基于描述生成歌曲的网站,完全AI生成,没有版权风险。而且生成质量也非常的高。
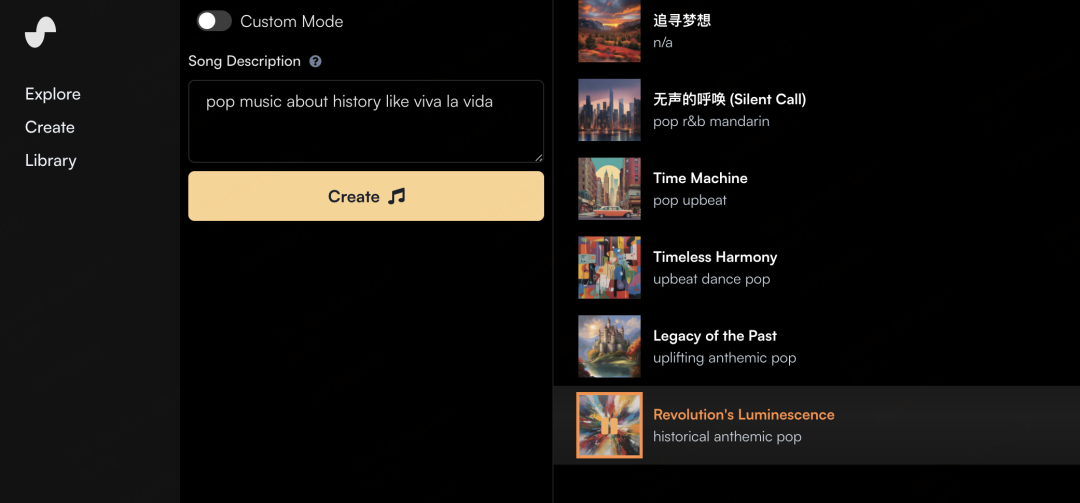
用流行音乐的类型去生成,大部分都是很流畅的节奏,很只是偶尔能听到部分不和谐的地方。自我感觉英文的歌曲质量生成质量比中文更好一些。

而且歌词都是帮你生成好的,歌词写的水平也还挺像那么回事
总结
其实很明显的可以看出,各行各业都在被AI重塑,也许你在使用的某款产品背后的某些能力都是ai去完成的。
而大模型越来越普及的背景下,普通人使用的成本也在逐渐降低。所以前端们完全可以跳出这个领域,在AI浪潮下,说不定某个很小众的方向,也会有些机会存在呢