亿万级海量数据去重软方法
文章目录
- 原理
- 案例一
- 需求:
- 方法
- 案例二
- 需求:
- 方法:
- 参考
原理
在大数据分布式计算框架生态下,提升计算效率的方法是尽可能的把计算分布式话、并行化,避免单节点计算过载,把计算分摊到各个节点。这样解释小白能够听懂:比如你有5个桶,怎样轻松地把A池子的水倒入B池子里?
- 最大并行化,5个桶同时利用,避免count distinct只用一个桶的方法
- 重复利用化,一次提不动那么多水,不要打肿脸充胖子,一不小心oom,为什么不分几次呢
- 数据均衡化,5个桶的水不要一个多一个少的,第一个提水的次数变多,第二个某些桶扛不住,俗称数据倾斜
案例一
需求:
计算day_num维度下的uv,自己脑补出海量数据,这里为方便说明,只列举了day_num,一个维度用桶来描绘计算模型,假设数据都是按字典顺序分桶
> select * from event;
+----------------+------------+
| event.day_num | event.uid |
+----------------+------------+
| day1 | a |
| day1 | a |
| day1 | a |
| day1 | a |
| day1 | bb |
| day1 | bb |
| day1 | bbb |
| day1 | ccc |
| day1 | ccc |
| day1 | dddd |
| day1 | eeee |
| day1 | eeeee |
| day1 | eeeee |
| day1 | eeeee |
+----------------+------------+
方法
- 原始方法:count(distinct)
select count(distinct(uid))as uv from event group by day_num;

可以看到所有数据装到一个桶里面,桶已经快装不下了,明显最差
- 优化一
select size(collect_set(uid)) as uv
from (select day_num,uid from event group by day_num,uid) tmp
group by day_num;

充分利用了桶,最大的实现了并行化,执行虽然分为了两部,但是大大减轻了第一步的负担,面向海量数据的场景去重方面拥有绝对的优势,假如第二步的结果集还是太大了呢?一样会oom扛不住
- 优化二(推荐👍)
简单说就是转化计算,在一个jvm里面,硬去重的方法都逃不开把所有字符或字符的映射放一个对象里面,通过一定的逻辑获取去重集合,对于分布式海量数据的场景下,这种硬去重的计算仍然会花大量的时间在上图的最后单点去重的步骤,我们可以把去重的逻辑按照一定的规则分桶计算完成,每个桶之间分的数据都不重复,所有桶计算完桶内数据去重的集合大小,最后一步再相加。
创建临时表,其中length(uid) as len_uid是映射字段,uid的长度create table event_tmp as select *,length(uid) as len_uid from event;
select sum(uv_tmp) as uv
from(select day_num,size(collect_set(uid)) as uv_tmp from event_tmp group by len_uid,day_num) tmp group by day_num
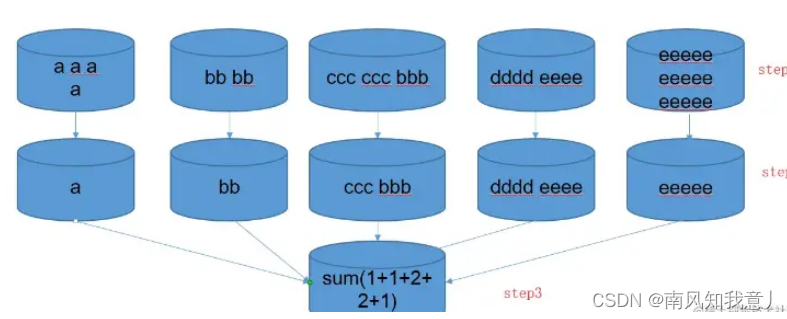
这里使用uid长度映射字段,实际开发中,你也可以选择首字母、末字母或者其它能想到的属性作为映射字段,分桶分步预聚合的方法,巧妙的把一个集合去重问题最终转化为相加问题,避开了单个jvm去重承受的压力,在海量数据的场景下,这个方法最为使用,推荐用在生产上。
案例二
需求:
商品 product 每日总销售记录量级亿 级别起,去重 product 量大概 万 级别。每个商品有一个 state 标识其状态,该状态共3个值,分别为 “0”, “1”,“2”。
统计:
(1) 三个 state 下 product 的总量 pv
(2) 对应 state 下 product 去重后的量 uv
第二个统计每个 state 下有亿级别的 value ,去重时有严重的数据倾斜且数据去重规模很大,亿级别去重至万亿级别
方法:
- GroupBy + RandomIndex + ToSet
val re = sc.textFile(input).map(line => {val info = line.split("\t")val state = info(0)val productId = info(1)// 全局计数countMap(state).add(1L)// 构建 state + randomIndex + product 的 PairRDD(state + "_" + random.nextInt(100) , productId)}).groupBy(_._1).map(info => {val state = info._1.split("_")(0)// 分治val productSet = info._2.map(kv => {val productId = kv._2productId}).toArray.toSet(state, productSet)}).groupBy(_._1).map(info => {val state = info._1val tmpSet = mutable.HashSet[String]()// 合并info._2.foreach(kv => {tmpSet ++= kv._2})state + ":" + tmpSet.size}).collect()
因为 state 只有 0,1,2 三种可能,所以最后全部压力分摊在 3 个节点上,构造 PairRDD 时可以给 state 加上随机索引,从而将任务分散,获得多个小的 Set 再合并成大 Set 。相当于分治,该方法会将原始数据分为 3 x 100 份,缩减了每个 key 要处理的 productId 的量,最后再去除随机索引再 groupBy 一次,汇总得到结果,执行时间 5 min,优化效果显著。
- Distinct + GroupBy (推荐👍 )
上一步方案通过 randomIndex 将数据量分治,减少的百分比和 random 的数值成正比,但是在数据量很大的情况下,分治的每个 key 对应的 value 量还是很大,所以简单的去重执行 5min +,这次将 groupBy 改为 distinct,先去重得到 万 级别数据量,再 GroupBy,此时的数据量本机也可轻松完成
def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getSimpleName)val sc: SparkContext = SparkContext.getOrCreate(conf)val rdd1: RDD[String] = sc.parallelize(List("1,spark","0,flink","1,kafka","1,spark","0,hadoop",), 4)val myAccumulator = new MyAccumulatorsc.register(myAccumulator, "myAcc")val rdd2 = rdd1.map(str => {val info: Array[String] = str.split(",")val state: String = info(0)val productId: String = info(1)//累加器 求pvmyAccumulator.add(state)state + "_" + productId}).distinct().map(info => {val str: Array[String] = info.split("_")val state: String = str(0)val productId: String = str(1)(state, productId)}).groupBy(_._1) //(1,CompactBuffer((1,kafka), (1,spark))).map(f => {val state: String = f._1val num: Int = f._2.map(_._2).toSet.size(state, num)})rdd2.foreach(println(_))//输出累加器值(注意在action后)val sentMap: mutable.HashMap[String, Long] = myAccumulator.valueprintln(sentMap.toString())}
}//自定义累加器
class MyAccumulator extends AccumulatorV2[String, mutable.HashMap[String, Long]] {private val hashMap = new mutable.HashMap[String, Long]()override def isZero: Boolean = hashMap.isEmptyoverride def copy(): AccumulatorV2[String, mutable.HashMap[String, Long]] = new MyAccumulatoroverride def reset(): Unit = hashMap.clear()override def add(v: String): Unit = {val l: Long = hashMap.getOrElse(v, 0L)hashMap.update(v, l + 1)}override def merge(other: AccumulatorV2[String, mutable.HashMap[String, Long]]): Unit = {val hashMap1: mutable.HashMap[String, Long] = this.hashMapval hashMap2: mutable.HashMap[String, Long] = other.valuehashMap2.foreach {case (k, v) => {val l: Long = hashMap1.getOrElse(k, 0L)hashMap1.update(k, l + v)}}}override def value: mutable.HashMap[String, Long] = this.hashMap
}
输出:(1,2)(0,2)Map(1 -> 3, 0 -> 2)
- distinct源码
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {def removeDuplicatesInPartition(partition: Iterator[T]) .......partitioner match {case Some(_) if numPartitions == partitions.length =>mapPartitions(removeDuplicatesInPartition, preservesPartitioning = true)case _ => map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)}}
partitioner源码是这样声明的:val partitioner: Option[Partitioner] = None
case Some(_) //这句是匹配partitioner不为None
所以最终执行的代码是:
case _ => map(x => (x, null)).reduceByKey((x, ) => x, numPartitions).map(._1)
case _ => map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
主要是用到了 reduceByKey ,这个算子会在MapSide进行预聚合的操作。将聚合后的结果传递到reduce端。
参考
https://www.jianshu.com/p/1cdc943bb649
https://blog.csdn.net/BIT_666/article/details/121672715
reduceByKey详见
累加器详见