VQ-VAE(Neural Discrete Representation Learning)论文解读及实现
pytorch 实现git地址
论文地址:Neural Discrete Representation Learning
1 论文核心知识点
-
encoder
将图片通过encoder得到图片点表征
如输入shape [32,3,32,32]
通过encoder后输出 [32,64,8,8] (其中64位输出维度) -
量化码本
先随机构建一个码本,维度与encoder保持一致
这里定义512个离散特征,码本shape 为[512,64] -
encoder 码本中向量最近查找
encoder输出shape [32,64,8,8], 经过维度变换 shape [32 * 8 * 8,64]
在码本中找到最相近的向量,并替换为码本中相似向量
输出shape [3288,64],维度变换后,shape 为 [32,64,8,8] -
decoder
将上述数据,喂给decoder,还原原始图片 -
loss
loss 包含两部分
a . encoder输出和码本向量接近
b. 重构loss,重构图片与原图片接近

2 论文实现
2.1 encoder
encoder是常用的图片卷积神经网络
输入x shape [32,3,32,32]
输出 shape [32,128,8,8]
def __init__(self, in_dim, h_dim, n_res_layers, res_h_dim):super(Encoder, self).__init__()kernel = 4stride = 2self.conv_stack = nn.Sequential(nn.Conv2d(in_dim, h_dim // 2, kernel_size=kernel,stride=stride, padding=1),nn.ReLU(),nn.Conv2d(h_dim // 2, h_dim, kernel_size=kernel,stride=stride, padding=1),nn.ReLU(),nn.Conv2d(h_dim, h_dim, kernel_size=kernel-1,stride=stride-1, padding=1),ResidualStack(h_dim, h_dim, res_h_dim, n_res_layers))def forward(self, x):return self.conv_stack(x)2.2 VectorQuantizer 向量量化层
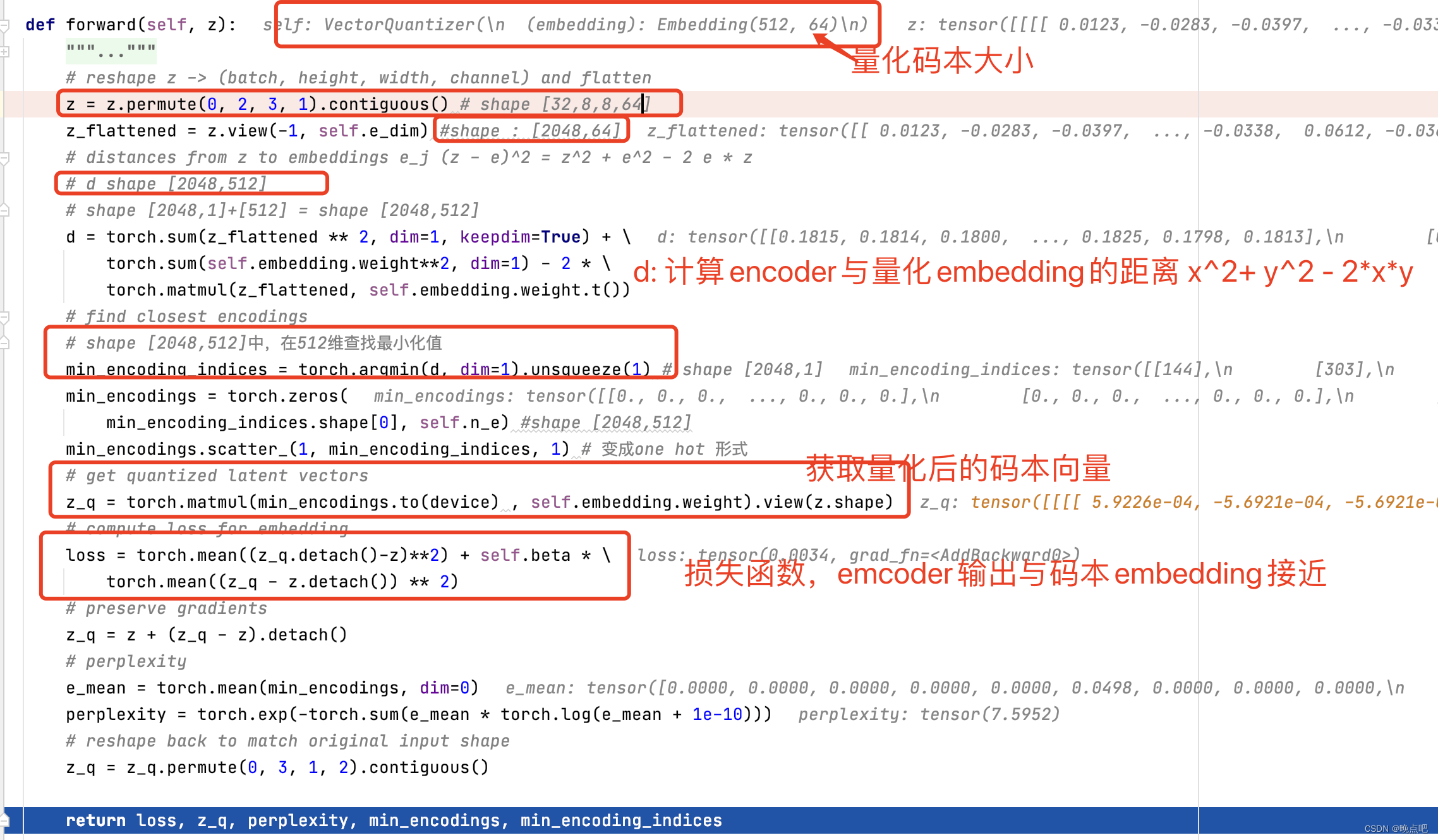
- 输入:
为encoder的输出z,shape : [32,64,8,8] - 码本维度:
encoder维度变换为[2024,64],和码本embeddign shape [512,64]计算相似度 - 相似计算:使用 ( x − y ) 2 = x 2 + y 2 − 2 x y (x-y)^2=x^2+y^2-2xy (x−y)2=x2+y2−2xy计算和码本的相似度
- z_q生成
然后取码本中最相似的向量替换encoder中的向量 - z_1维度:
得到z_q shape [2024,64],经维度变换 shape [32,64,8,8] ,维度与输入z一致 - 损失函数:
使 z_q和z接近,构建损失函数
decoder 层
decoder层比较简单,与encoder层相反
输入x shape 【32,64,8,8】
输出shape [32,3,32,32]
class Decoder(nn.Module):"""This is the p_phi (x|z) network. Given a latent sample z p_phi maps back to the original space z -> x.Inputs:- in_dim : the input dimension- h_dim : the hidden layer dimension- res_h_dim : the hidden dimension of the residual block- n_res_layers : number of layers to stack"""def __init__(self, in_dim, h_dim, n_res_layers, res_h_dim):super(Decoder, self).__init__()kernel = 4stride = 2self.inverse_conv_stack = nn.Sequential(nn.ConvTranspose2d(in_dim, h_dim, kernel_size=kernel-1, stride=stride-1, padding=1),ResidualStack(h_dim, h_dim, res_h_dim, n_res_layers),nn.ConvTranspose2d(h_dim, h_dim // 2,kernel_size=kernel, stride=stride, padding=1),nn.ReLU(),nn.ConvTranspose2d(h_dim//2, 3, kernel_size=kernel,stride=stride, padding=1))def forward(self, x):return self.inverse_conv_stack(x)2.3 损失函数
损失函数为重构损失和embedding损失之和
- decoder 输出为图片重构x_hat
- embedding损失,为encoder和码本的embedding近似损失
- 重点:(decoder计算损失时,由于中间有取最小值,导致梯度不连续,因此decoder loss 不能直接对encocer推荐进行求导,采用了复制梯度的方式: z_q = z + (z_q - z).detach(),及
for i in range(args.n_updates):(x, _) = next(iter(training_loader))x = x.to(device)optimizer.zero_grad()embedding_loss, x_hat, perplexity = model(x)recon_loss = torch.mean((x_hat - x)**2) / x_train_varloss = recon_loss + embedding_lossloss.backward()optimizer.step()