nodeJS搭建免费代理IP池爬取贴吧图片实战
之前用python写过爬虫,这次想试试nodeJS爬虫爬取贴吧图片,话不多说代码如下,爬取制定吧的前十页所有帖子里的图片
爬取贴吧图片脚本
你得提前创建一个images文件夹
const axios = require("axios");
const cheerio = require("cheerio");
const sanitize = require("sanitize-filename");
const fs = require("fs");
const path = require("path");// 定义要爬取的贴吧URL
const baseUrl = "https://tieba.baidu.com/f?kw=%CB%EF%D0%A6%B4%A8&fr=ala0&tpl=5&dyTabStr=MCwxLDMsMiw2LDQsNSw4LDcsOQ%3D%3D";// 发送HTTP请求获取页面内容
async function getTitlesByPage(pageNum) {const url = baseUrl + pageNum * 50;try {const response = await axios.get(url);if (response.status === 200) {// 使用cheerio解析页面const $ = cheerio.load(response.data);$(".threadlist_title a.j_th_tit").each((index, element) => {// 定义要下载的帖子URLconst url = "https://jump2.bdimg.com" + $(element).attr("href");// 发送HTTP请求获取页面内容axios.get(url).then((response) => {if (response.status === 200) {// 使用cheerio解析页面const $ = cheerio.load(response.data);// 获取帖子中的所有图片链接const imgUrls = [];$("img.BDE_Image").each((index, element) => {imgUrls.push($(element).attr("src"));});// 下载所有图片imgUrls.forEach((imgUrl, index) => {axios({method: "get",url: imgUrl,responseType: "stream",headers: {Referer: url,},}).then((response) => {const filename = sanitize(path.basename(imgUrl));const filePath = path.resolve(__dirname,`./images/${filename}.jpg`);response.data.pipe(fs.createWriteStream(filePath));console.log(`第 ${index + 1} 张图片下载完成`);}).catch((error) => {console.log(`第 ${index + 1} 张图片下载失败`, error);});});} else {console.log("请求失败");}}).catch((error) => {console.log("请求出错", error);});});} else {console.log(`请求第 ${pageNum + 1} 页失败`);}} catch (error) {console.log(`请求第 ${pageNum + 1} 页出错`, error);}
}async function getTitles() {for (let i = 0; i < 10; i++) {await getTitlesByPage(i);}
}getTitles();这里有个弊端,IP会被马上封掉,那么通过爬取免费代理IP网站的IP去创建本地代理IP池txt文件
找了一个勉强可用的免费代理IP网站免费代理IP_免费HTTP代理IP_SOCKS5代理服务器_优质IP代理_89免费代理IP
里面的有效IP很少,那么得自己去大量爬取筛选可用IP
这个是
爬取建立免费代理IP池的脚本
你得提前创建一个proxy.txt文件
const fs = require('fs');
const axios = require('axios');
const cheerio = require('cheerio');const headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
};async function get89IP(filePath) {for (let i = 1; i <= 10; i++) { // 循环采集前10页的数据const url = `https://www.89ip.cn/index_${i}.html`;try {const response = await axios.get(url, { headers });const $ = cheerio.load(response.data);const trs = $('table tbody tr');trs.each((index, element) => {const ip = $(element).find('td:nth-child(1)').text().trim();const port = $(element).find('td:nth-child(2)').text().trim();const proxyIP = `${ip}:${port}`;fs.appendFileSync(filePath, proxyIP + '\n');});console.log(`第${i}页采集完成`);} catch (error) {console.error('出错了:', error);}await new Promise((resolve) => setTimeout(resolve, 1000));}
}async function main() {const filePath = './proxy.txt';while (true) {try {await get89IP(filePath);console.log('采集完成');} catch (error) {console.error('出错了:', error);}await new Promise((resolve) => setTimeout(resolve, 60000));}
}main();
采集完成后的筛选IP代码
一个一个筛选太慢,这里使用到了Promise.all
你得提前创建一个KyProxy.txt文件
const fs = require('fs');
const axios = require('axios');const proxyList = fs.readFileSync('proxy.txt', 'utf-8').split('\n').filter(Boolean);async function testProxy(ip) {try {const response = await axios.get('https://tieba.baidu.com/', {proxy: {host: ip.split(':')[0],port: ip.split(':')[1]},timeout: 5000});if (response.status === 200 || response.status === 302) {return true;}} catch (error) {console.error(error);}return false;
}async function main() {const promiseArr = [];for (const proxy of proxyList) {promiseArr.push(testProxy(proxy));}const resultArr = await Promise.all(promiseArr);const validProxies = resultArr.reduce((acc, curr, index) => {if (curr) {acc.push(proxyList[index]);console.log(`代理IP ${proxyList[index]} 可用`);} else {console.log(`代理IP ${proxyList[index]} 不可用`);}return acc;}, []);fs.writeFileSync('kyProxy.txt', validProxies.join('\n'));console.log('可用代理IP已写入 kyProxy.txt');
}main().catch((error) => console.error(error));
到这一步kyProxy.txt里面的IP基本是稳定可用的了,最后一步就是使用kyProxy.txt里的代理I去爬取图片
通过代理IP爬取贴吧图片
const axios = require("axios");
const cheerio = require("cheerio");
const sanitize = require("sanitize-filename");
const fs = require("fs");
const path = require("path");// 定义要爬取的贴吧URL
const baseUrl ="https://tieba.baidu.com/f?kw=%CB%EF%D0%A6%B4%A8&fr=ala0&tpl=5&dyTabStr=MCwxLDMsMiw2LDQsNSw4LDcsOQ%3D%3D";// 获取代理IP池
async function getProxyList() {const fileContent = await fs.promises.readFile(path.resolve(__dirname, "./kyProxy.txt"),"utf8");return fileContent.trim().split("\n");
}// 发送HTTP请求获取页面内容
async function getTitlesByPage(pageNum, proxyList) {const url = baseUrl + pageNum * 50;try {let success = false;for (let i = 0; i < proxyList.length; i++) {const proxy = `${proxyList[i]}`;console.log(`使用代理IP:${proxy}`);try {const response = await axios.get(url, {proxy: {host: proxyList[i].split(":")[0],port: proxyList[i].split(":")[1],},});if (response.status === 200) {// 使用cheerio解析页面const $ = cheerio.load(response.data);$(".threadlist_title a.j_th_tit").each(async (index, element) => {// 定义要下载的帖子URLconst url = "https://jump2.bdimg.com" + $(element).attr("href");// 发送HTTP请求获取页面内容const imgUrls = await getImgUrls(url, proxy);// 下载所有图片for (let j = 0; j < imgUrls.length; j++) {await downloadImg(imgUrls[j], j, url, proxy);}});success = true;break;} else {console.log(`代理IP ${proxy} 请求失败`);}} catch (error) {console.log(`代理IP ${proxy} 请求出错`, error);}}if (!success) {console.log(`请求第 ${pageNum + 1} 页失败,跳过`);}} catch (error) {console.log(`请求第 ${pageNum + 1} 页出错`, error);}
}// 获取帖子中的所有图片链接
async function getImgUrls(url, proxy) {try {const response = await axios.get(url, {proxy: {host: proxy.split(":")[0],port: proxy.split(":")[1],},headers: {Referer: url,},});if (response.status === 200) {const $ = cheerio.load(response.data);const imgUrls = [];$("img.BDE_Image").each((index, element) => {imgUrls.push($(element).attr("src"));});return imgUrls;} else {console.log(`请求 ${url} 失败`);return [];}} catch (error) {console.log(`请求 ${url} 出错`, error);return [];}
}// 下载单张图片
async function downloadImg(imgUrl, index, url, proxy) {try {const response = await axios({method: "get",url: imgUrl,responseType: "stream",proxy: {host: proxy.split(":")[0],port: proxy.split(":")[1],},headers: {Referer: url,},});if (response.status === 200) {const filename = sanitize(path.basename(imgUrl));const filePath = path.resolve(__dirname, `./images/${filename}.jpg`);response.data.pipe(fs.createWriteStream(filePath));console.log(`第 ${index + 1} 张图片下载完成`);} else {console.log(`第 ${index + 1} 张图片下载失败`);}} catch (error) {console.log(`第 ${index + 1} 张图片下载出错`, error);}
}async function getTitles() {const proxyList = await getProxyList();for (let i = 0; i < 10; i++) {await getTitlesByPage(i, proxyList);}
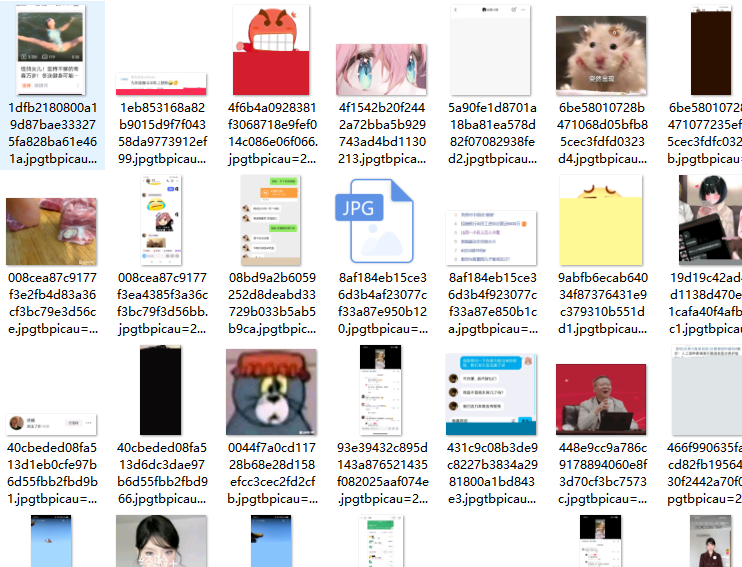
}getTitles();爬取效果
效果还可以