Mysql InnoDB 存储引擎笔记
1 存储引擎 简介
Mysql 存储引擎有多种:包括 MyISAM、InnoDB 和 Memory。
其中MyISAM 和 INNODB 的区别:
- 事务安全(MyISAM不支持事务,INNODB支持事务);
- 外键 MyISAM 不支持外键, INNODB支持外键;
- 锁机制(MyISAM时表锁,innodb是行锁);
- 查询和添加速度(MyISAM批量插入速度快);
- 支持全文索引(MyISAM支持全文索引,INNODB不支持全文索引);
- MyISAM内存空间使用率比InnoDB低。
InnoDB是是最常用的存储引擎。
2 InnoDB 简介
存储引擎:是底层物理结构和实际文件读写的实现。
InnoDB 是一个将表中的数据存储到磁盘上的存储引擎。
InnoDB 的内存结构图如下:
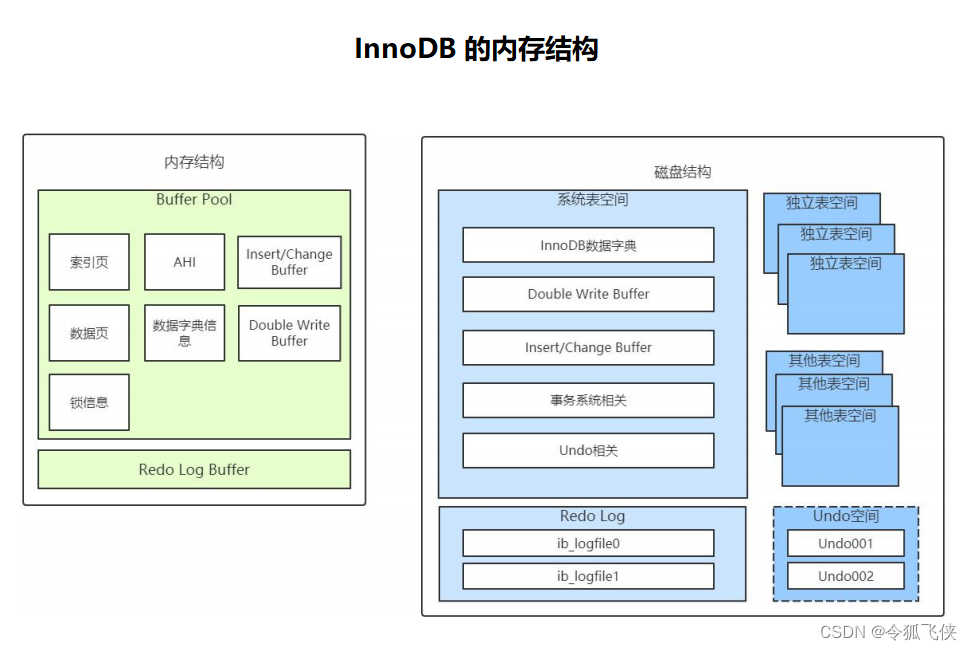
3 InnoDB 三大特性
三大特性:
-
双写缓冲区
Doublewrite buffer,
作用:在把页写到数据文件之前,InnoDB 先把它们写到一个叫 doublewrite buffer(双写缓冲区)的连续区域内,在写 doublewrite buffer 完成后,InnoDB 才会把页写到数据文件的适当的位置。 -
Buffer Pool
处理客户端的请求时,当需要访问某个页的数据时,就会把完整的页的数据全部加载到内存中,将整个页加载到内存中后就可以进行读写访问了,在进行完读写访问之后并不着急把该页对应的内存空间释放掉,而是将其缓存起来,这样将来有请求再次访问该页面时,就可以省去磁盘 IO 的开销了。 -
自适应 Hash 索引
InnoDB 去监控索引表,如果监控到某个索引经常用,那么就认为是热数据,然后内部自己创建一个 hash 索引,称之为自适应哈希索引(Adaptive Hash Index,AHI)。
如果没有自适应 Hash 索引,需通过B+tree 索引中查询节点。
三大特性场景:
双写缓冲区:写磁盘;
Buffer Pool:读写缓存;
自适应 Hash 索引:查询数据。
小结:
利用内存、磁盘(文件),应用不同数据结构(数组、链表、hash表、B+tree),处理读写数据的策略实现。