项目应用多级缓存示例
前不久做的一个项目,需要在前端实时展示硬件设备的数据。设备很多,并且每个设备的数据也很多,总之就是数据很多。同时,设备的刷新频率很快,需要每2秒读取一遍数据。
问题来了,我们如何读取数据,并且在前端展示?
我的想法是利用多级缓存:
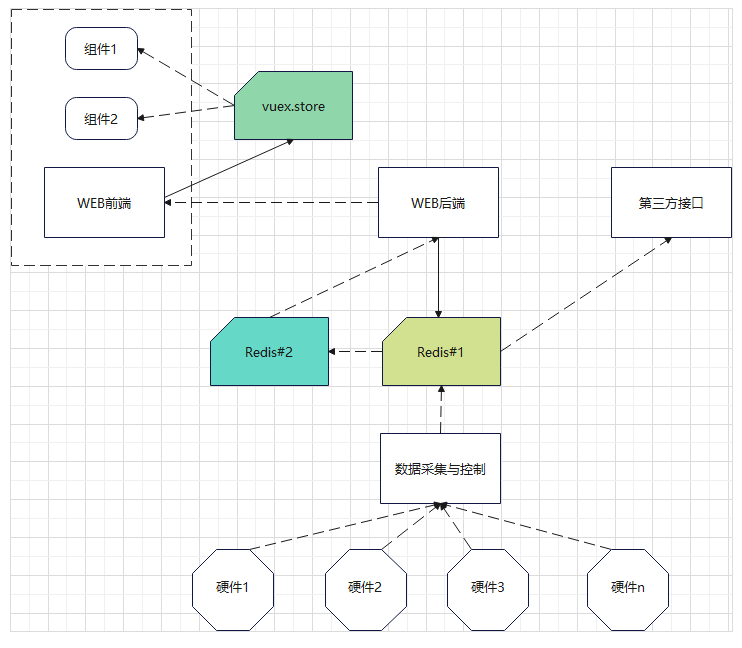
1)首先是有个数据采集程序,不停地采集设备的数据。采集到数据以后,写入redis的1号库;
2)WEB后端设置一个定时器,每2秒读一次redids的1号库,处理后写入redis的2号库。之所以要处理一下,是因为1号库的数据比较原始,处理后才适合前端处理
3)前端也设置一个程序,每2秒向后端请求一次数据,后端将redis#2数据返回;前端收到数据后写入前端缓存。我们前端是用vue搞的,所以存入store。
4)前端由很多个组件构成,每个组件都从store中读取数据,然后展示。
系统结构如图所示:
优点:
1)数据采集程序与WEB前后端解耦,职责单一,除了采集数据,啥都不用管。简单的往往就是最好的,不容易出错
2)后端定期处理原始数据,将结果缓存,当前端请求时,返回缓存中的该结果,减少重复劳动,提高了性能
3)前端虽有多个组件,但不是每一个组件都向后端请求,而是统一请求一次,存入前端缓存,然后全部组件都从前端缓存中读取,对性能是一个保障。
事实证明,这种多级缓存机制下,前端展示数据非常迅速,及时。虽然前端和WEB后端之间没有使用websocket进行数据传输,而是使用了最笨的定期获取,但丝毫没有影响前端的用户体验。