linux常用命令介绍 05 篇——实际应用篇(用 cut、uniq等统计文档里每个关键词出现的次数)
linux常用命令介绍 05 篇——实际应用篇(用 cut、uniq等统计文档里每个关键词出现的次数)
- 1. 先导文章——关于行过滤 和 列截取
- 2. 关于单个统计单词个数
- 2.1 grep
- 2.2 wc
- 3. 统计文档中每个关键词出现的次数
- 3.1 先看文档内容 + 需求
- 3.1.1 文档内容
- 3.1.2 需求
- 3.2 分析并实现需求
1. 先导文章——关于行过滤 和 列截取
-
前几天被问到一个问题,之前没用过,感觉挺尴尬的,束手无策,今天抽空去了解一下,其实就两三个命令的事,不过感觉也挺有意思的,顺便记录下来,供大家参考。
-
看这篇文章之前用到了其他工具,如果需要的话,可以看看下面的文章:
linux常用命令介绍 03 篇——常用的文本处理工具之grep和cut(以及部分正则使用).
2. 关于单个统计单词个数
2.1 grep
- 上篇文章里有介绍,可以使用
grep -c的命令进行统计,如下:grep -c 'www.google.com' http.txt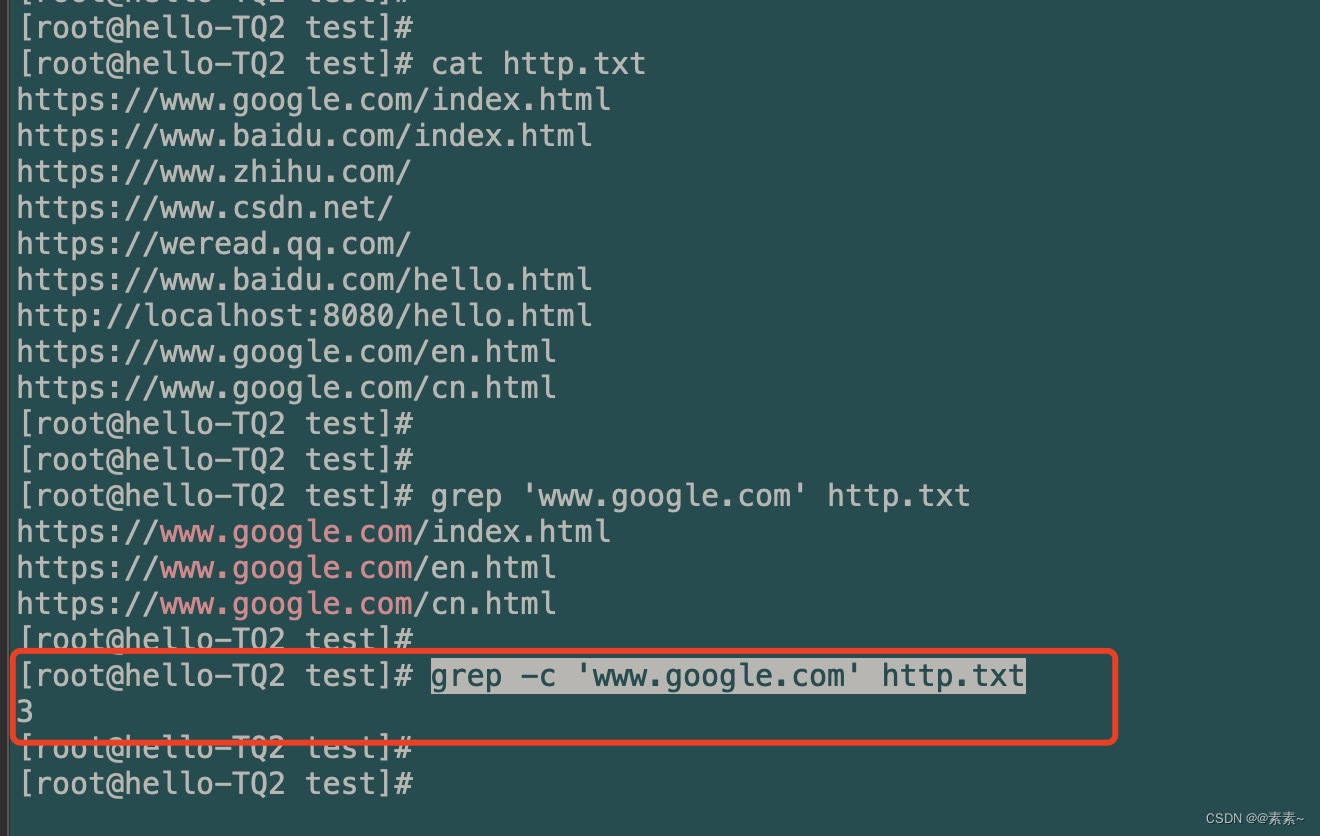
2.2 wc
- wc 统计使用选项如下:
wc -l:统计单词出现的行次数wc -w:统计单词出现的次数
- 使用例子如下:
grep 'www.google.com' http2.txt | wc -w grep 'www.google.com' http2.txt | wc -l cat http2.txt | grep '8080' | wc -w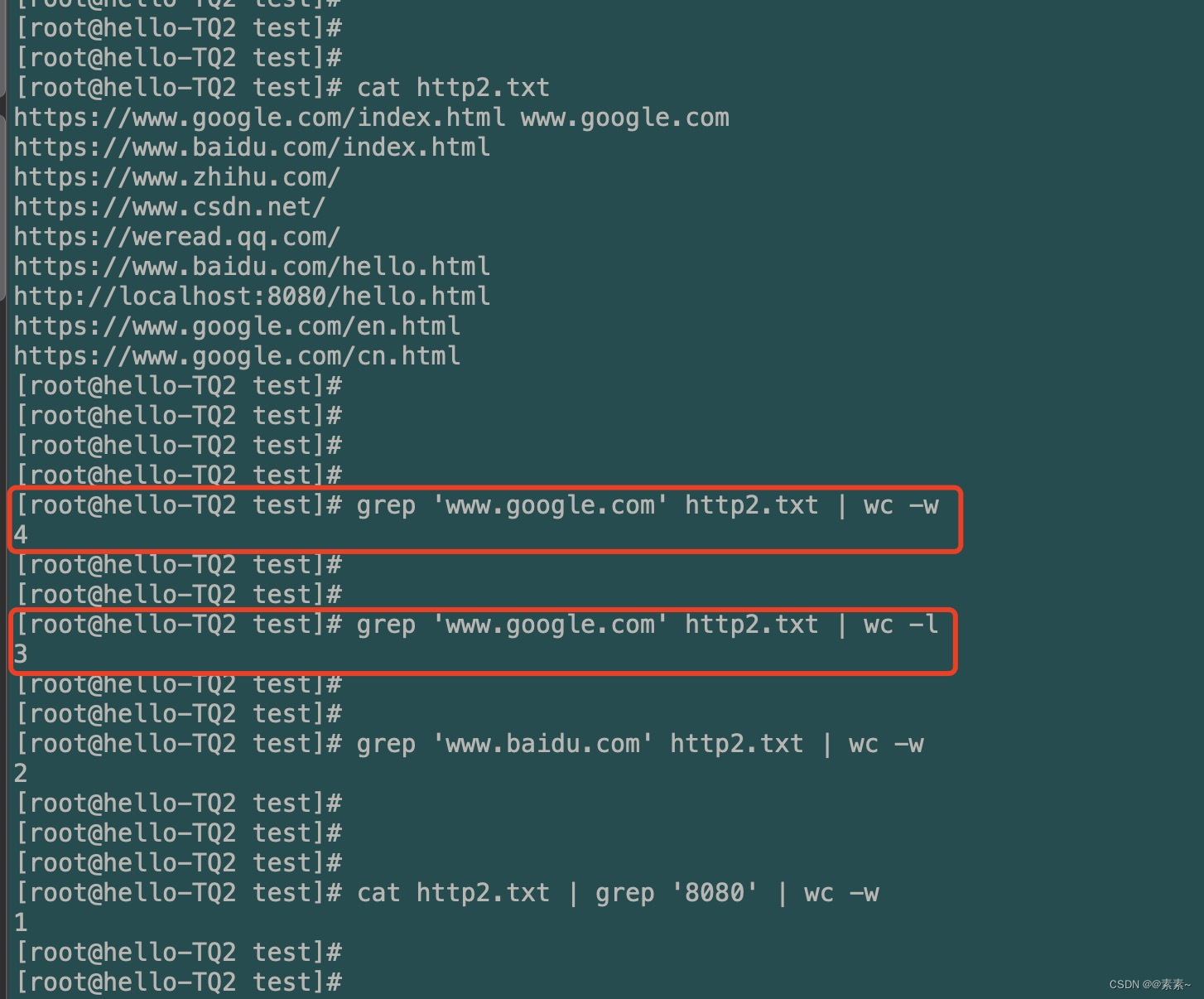
3. 统计文档中每个关键词出现的次数
3.1 先看文档内容 + 需求
3.1.1 文档内容
- 文档内容如下:
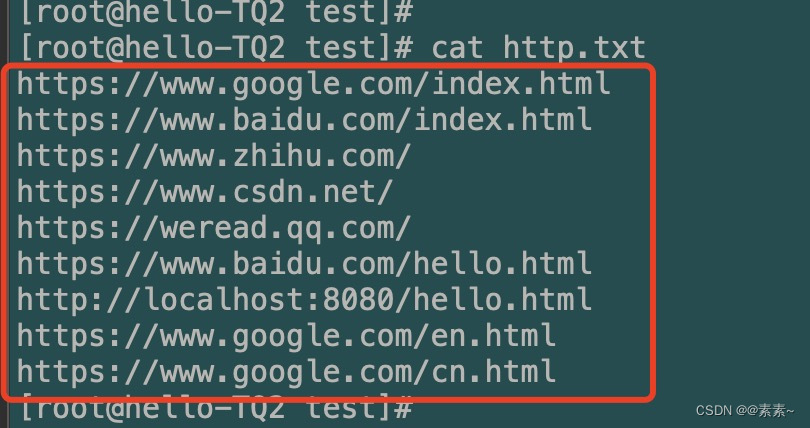
https://www.google.com/index.html https://www.baidu.com/index.html https://www.zhihu.com/ https://www.csdn.net/ https://weread.qq.com/ https://www.baidu.com/hello.html http://localhost:8080/hello.html https://www.google.com/en.html https://www.google.com/cn.html
3.1.2 需求
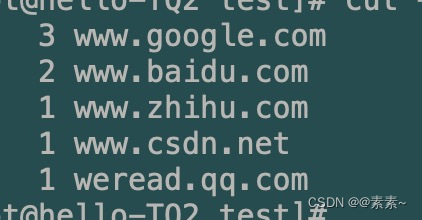
- 想实现的需求就是,把上面文档里的所有域名进行统计,并排序打印,要实现如下的效果(前面是域名出现的次数,后面是域名):
3.2 分析并实现需求
- 观察文档里的内容,分析如下:
- 第一步:列截取域名
- 首先,我们提取的有规律,是域名,所以根据文档里内容的规律,考虑使用列截取方法,使用 cut 工具。此处不熟悉的可以点进去上面的链接。
- 二话不说,执行命令,先看第一步效果:
cut -d'/' -f3 http.txt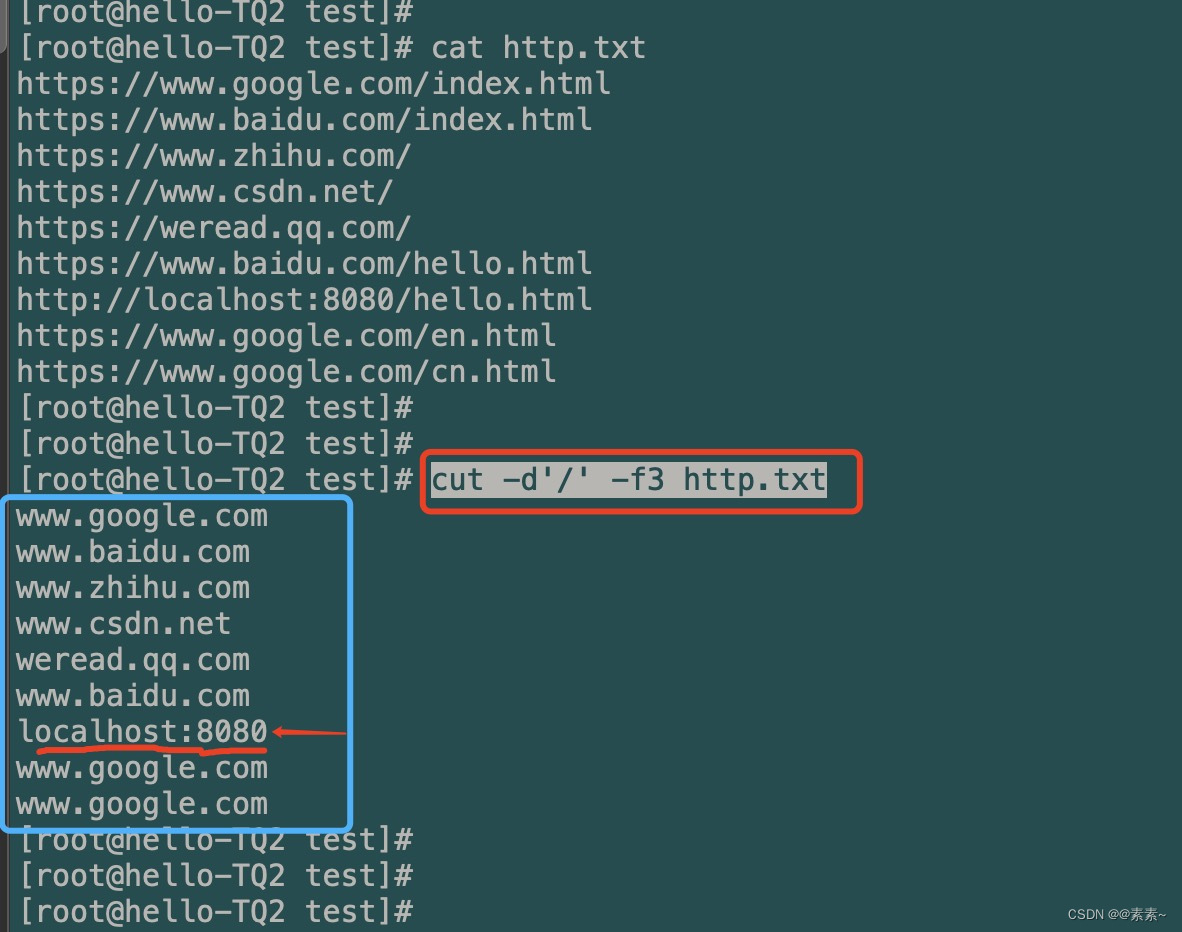
嗯,还不错,浓缩出精华来了,但是localhost:8080不是我们想要的,怎么处理,接下来第二步……
- 第二步:行过滤掉非域名 localhost:8080
-
根据第一步的效果,我们在第二步里要把
localhost:8080这个就要用到我们的 grep 行过滤了,不太清楚的话,还是点进去上面的链接,这里不多说,直接看效果:cut -d'/' -f3 http.txt | grep -v 'localhost'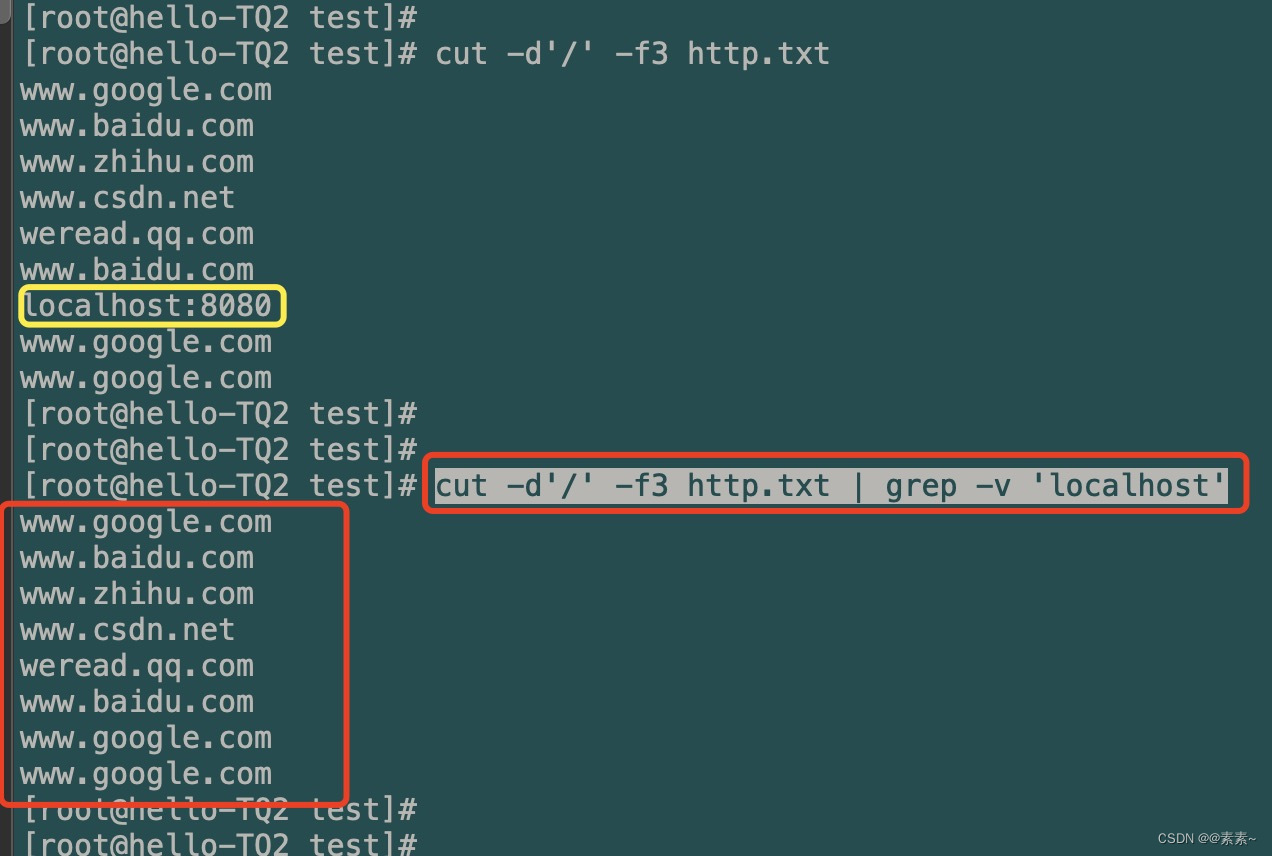
嗯,貌似也还不错,至少达到了我们第二步想要的效果了,好,接下来就是怎么统计并排序了,这就需要用到我们另一个命令了,uniq,关于这个命令的使用可以看下面的文章,在这里不做介绍,如下:linux常用命令介绍 04 篇——uniq命令使用介绍(Linux重复数据的统计处理).
-
- 第三步:使用
uniq命令 和sort命令进行排序并统计- 对这两命令有疑问的,点上面的链接,里面有详细的介绍与使用示例。
- 下面直接看效果:
cut -d'/' -f3 http.txt | grep -v 'localhost' | sort cut -d'/' -f3 http.txt | grep -v 'localhost' | sort | uniq -c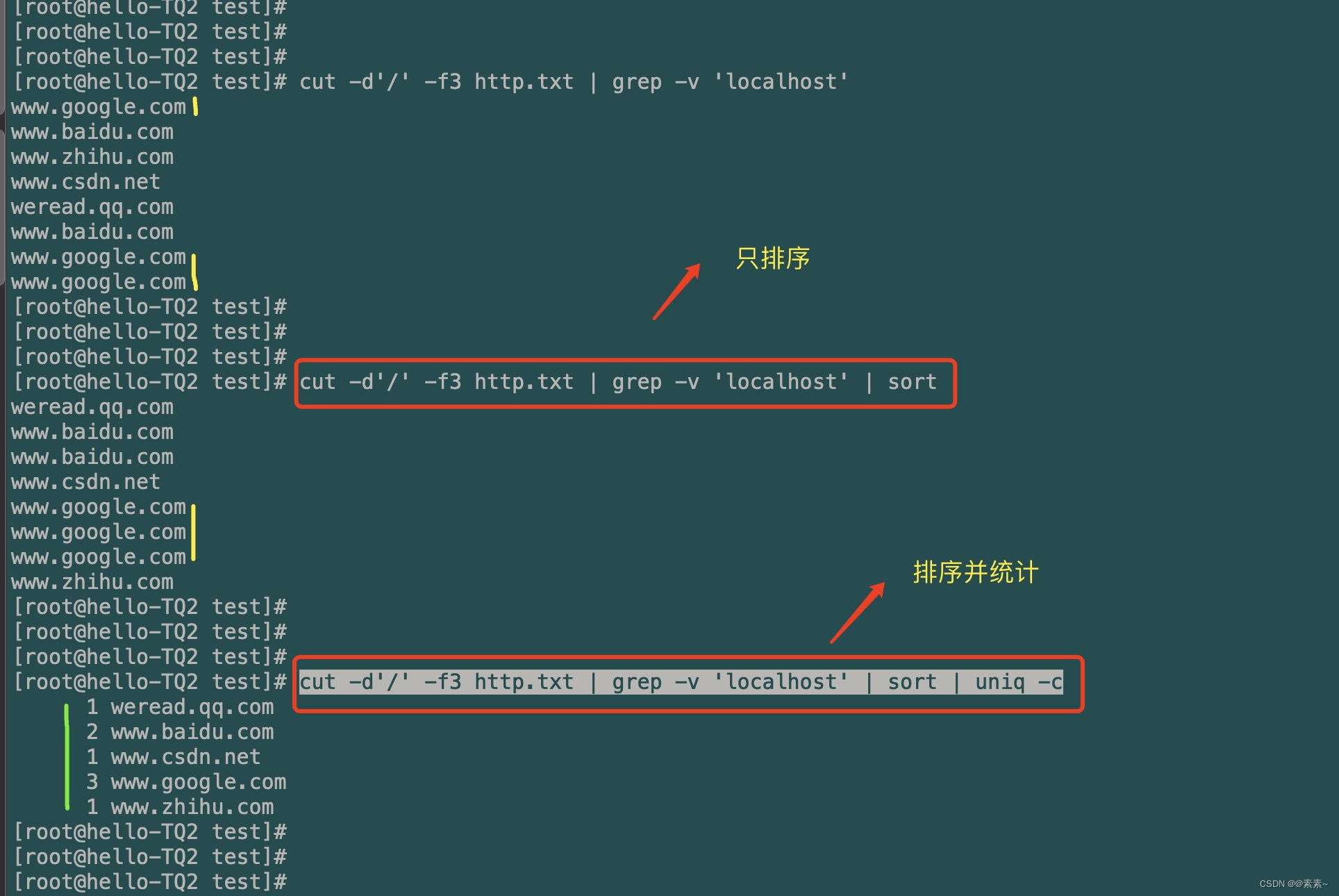
好,几乎接近我们要实现的目标了,就差怎么把前面统计的数字也给排序一下了,继续往下……
- 第四步:按域名统计个数的数字大小进行排序
- 这步就是在上面基础上再使用一次
sort即可,生序、降序都可实现,效果如下:cut -d'/' -f3 http.txt | grep -v 'localhost' | sort | uniq -c | sort cut -d'/' -f3 http.txt | grep -v 'localhost' | sort | uniq -c | sort -r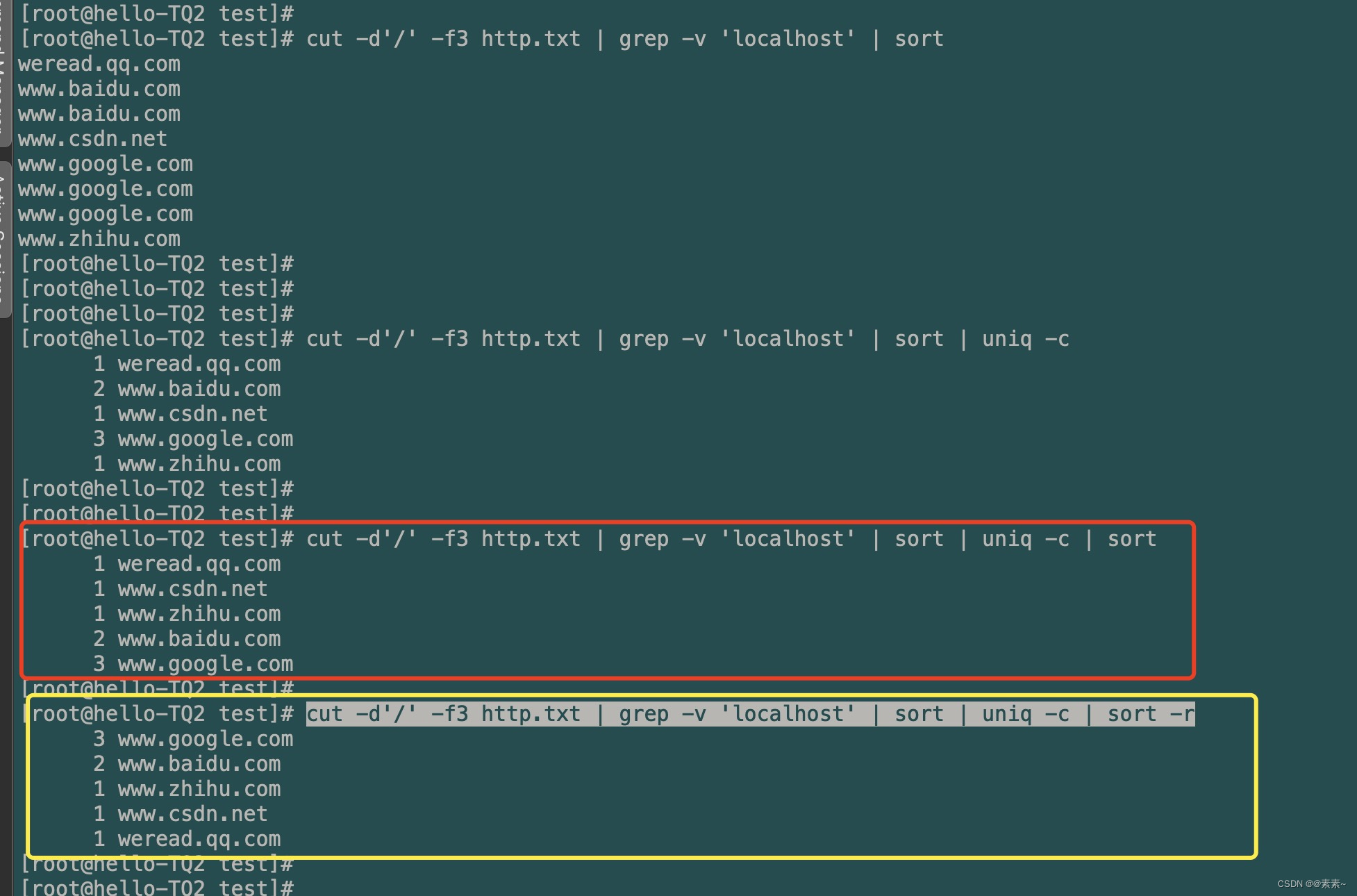
好了,到这里就是完美地实现了上面的需求了!!
- 这步就是在上面基础上再使用一次
- 第五步:可了解
- 当然,上面四步已经实现了需求,下面这个只是了解,我就方上效果,可以看看:
cut -d'/' -f3 http.txt | grep -v 'localhost' | sort | uniq -c | sort -r | awk '{print $2,$1}' cut -d'/' -f3 http.txt | grep -v 'localhost' | sort | uniq -c | sort -r | awk '{print $1,$2}'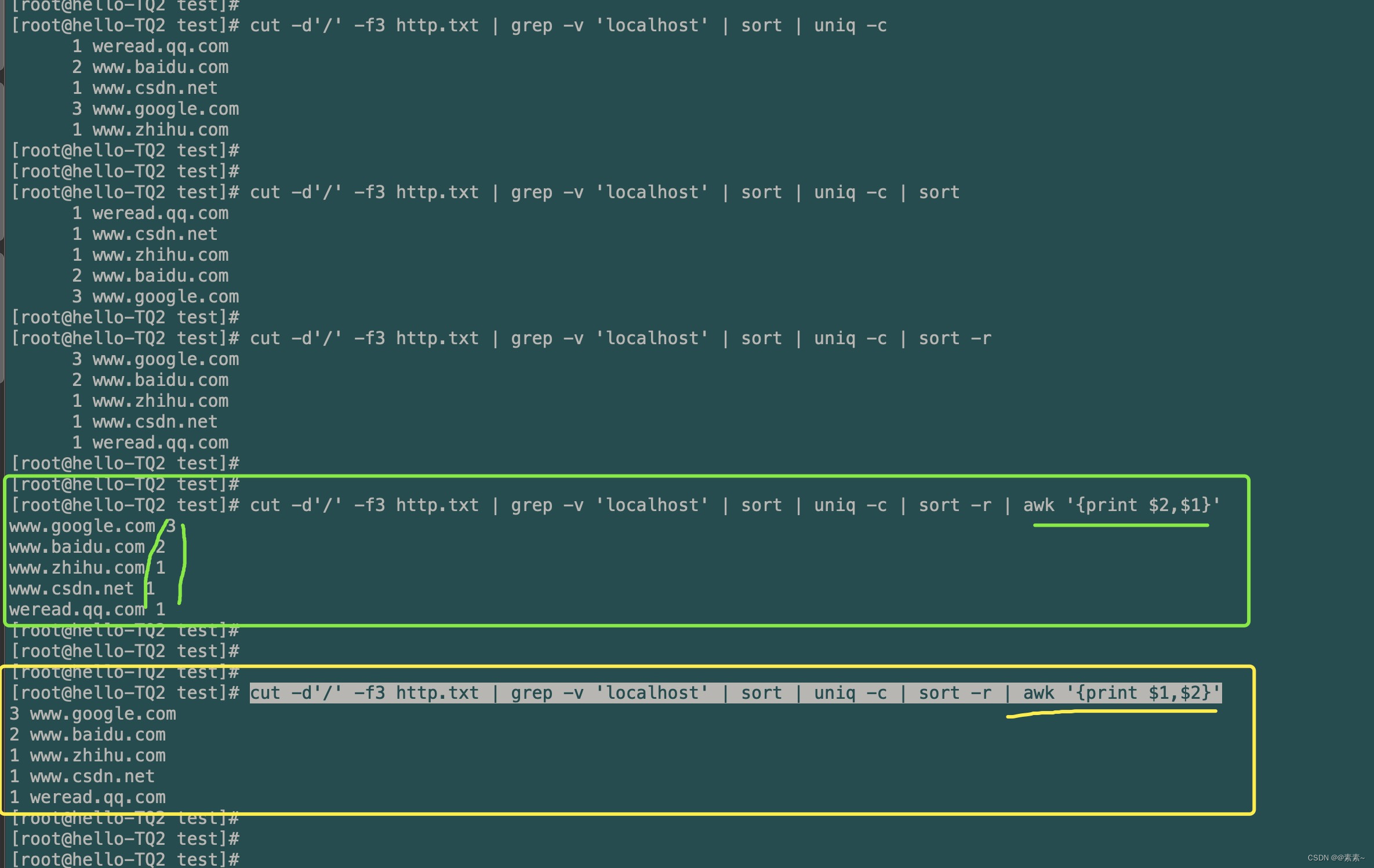
好了,这个就介绍到这里吧,希望对你有帮助!
- 当然,上面四步已经实现了需求,下面这个只是了解,我就方上效果,可以看看: