2023_Spark_实验二十九:Flume配置KafkaSink
实验目的:掌握Flume采集数据发送到Kafka的方法
实验方法:通过配置Flume的KafkaSink采集数据到Kafka中
实验步骤:
一、明确日志采集方式
一般Flume采集日志source有两种方式:
1.Exec类型的Source
可以将命令产生的输出作为源,如:
a1.sources.r1.type = exec
a1.sources.r1.command = ping 10.3.1.227 //此处输入命令
2.Spooling Directory类型的 Source
将指定的文件加入到“自动搜集 ”目录中。flume会持续监听这个目录,把文件当做source来处理。注意:一旦文件被放到“自动收集”目录中后,便不能修改,如果修改,flume会报错。此外,也不能有重名的文件,如果有,flume也会报错。
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/work/data
向指定的文件目录下传送一个日志文件,发现flume的控制台打印相关的信息;此外,待收集的文件,会追加一个后缀:completed,表示已处理完。
3.确定采集策略:
采用exec方式采集数据
如果采用spooldir的方式来监控log文件夹,flume会采集log数据,flume会不断修改文件名,导致重复。
所以使用exec命令行的方式,通过tail -F *.log命令比较好!
注意: -F根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪。 而-f根据文件的nodeid即文件描述符进行追踪,当文件改名或被删除,追踪停止 。
二、配置KafkaSink
Flume版本多,网上教程多,版本之间不兼容,推荐大家以Flume官网为准。


Exec Source

Kafka Sink

三、配置Flume配置文件
1. 拷贝一份配置文件模板
cp flume-conf.properties.template kafka.conf
2. 编辑kafka.conf
kafka.conf编辑内容如下
# 定义a2配置文件中每个组件的名称
a2.sources = execSrc
a2.channels = memoryChannel
a2.sinks = loggerSink# 配置source组件
# For each one of the sources, the type is defined
a2.sources.execSrc.type = exec
a2.sources.execSrc.command = tail -F /home/hadoop/scripts/realtime/realdata.log# 配置sink组件
# Each sink's type must be defined
a2.sinks.loggerSink.type = org.apache.flume.sink.kafka.KafkaSink
a2.sinks.loggerSink.kafka.topic = RealDataTopic
a2.sinks.loggerSink.kafka.bootstrap.servers = hd1:9092
a2.sinks.loggerSink.kafka.flumeBatchSize = 20
a2.sinks.loggerSink.kafka.producer.acks = 1
a2.sinks.loggerSink.kafka.producer.linger.ms = 1
a2.sinks.loggerSink.kafka.producer.compression.type = snappy# 配置缓存方式
# Each channel's type is defined.
a2.channels.memoryChannel.type = memory
a2.channels.memoryChannel.capacity = 1000
a2.channels.memoryChannel.transactionCapacity = 100# 配置source channel sink之间的连接关系
# The channel can be defined as follows.
a2.sources.execSrc.channels = memoryChannel
a2.sinks.loggerSink.channels = memoryChannel3. 启动测试
/opt/module/apache-flume-1.9.0-bin/bin/flume-ng agent -c conf -f /opt/module/apache-flume-1.9.0-bin/conf/kafka.conf -n a2 -Dflume.root.logger=INFO,console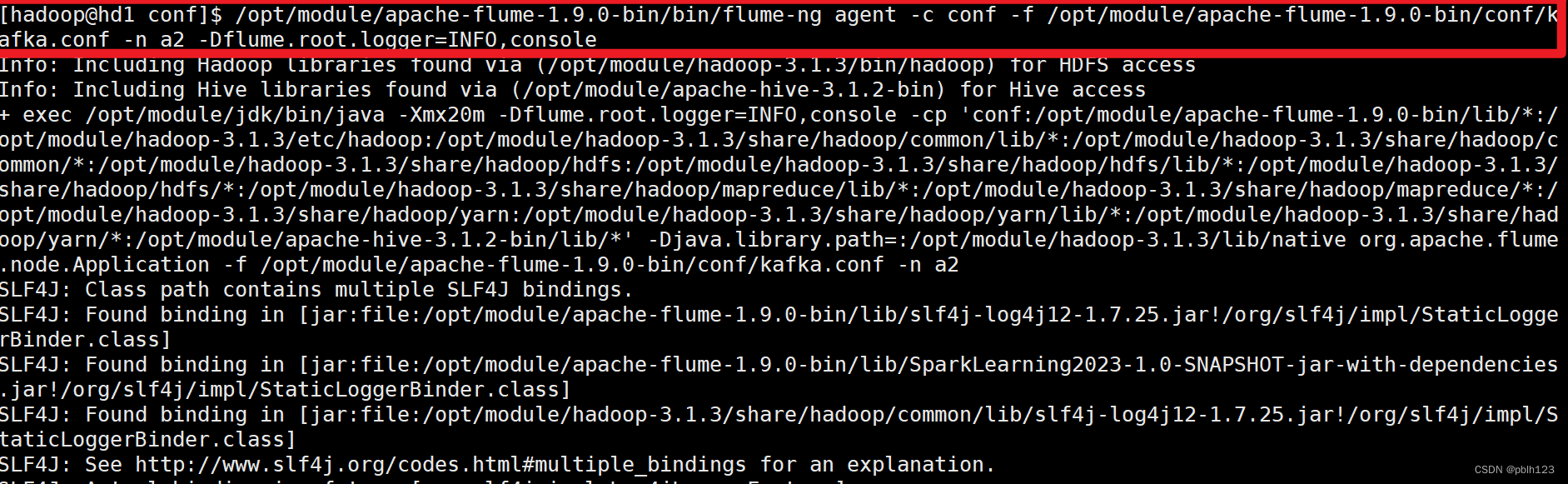
实验结果:配置kafkaSink成功,配置source为exec读取shell脚本模拟产生的实时数据