HBase 高可用集群详细图文安装部署
目录
一、HBase 安装部署
1.1 Zookeeper 正常部署
1.2 Hadoop 正常部署
1.3 HBase 安装
1.4 HBase 的配置文件
1.4.1 hbase-env.sh
1.4.2 hbase-site.xml
1.4.3 regionservers
1.4.4 创建目录
1.5 HBase 远程发送到其他节点
1.6 HBase 服务的启动
1.6.1 单点启动(推荐)
1.6.2 群启
1.6.2 停止服务
1.7 查看 HBase 页面
1.8 高可用(推荐)
二、HBase 集群扩缩容
- jdk 版本的支持参考: Apache HBase ™ Reference Guide
- 与 hadoop 的版本对应参考: Apache HBase ™ Reference Guide (向下滑到 4.1 章节)
一、HBase 安装部署
| 主机名称 | IP | 资源 | 部署角色 |
| hadoop01 | 192.168.170.136 | 2cpu 4G | master、regionserver |
| hadoop02 | 192.168.170.137 | 2cpu 4G | master、regionserver |
| hadoop03 | 192.168.170.138 | 2cpu 4G | regionserver |
1.1 Zookeeper 正常部署
首先保证 Zookeeper 集群的正常部署,并启动之。
安装教程:【Zookeeper 初级】02、Zookeeper 集群部署-CSDN博客
1.2 Hadoop 正常部署
Hadoop 集群的正常部署并启动。
安装教程:Hadoop YARN HA 集群安装部署详细图文教程_hadoop yarn部署-CSDN博客
1.3 HBase 安装
HBase 官方下载地址:Apache Download Mirrors
(base) [root@hadoop01 ~]# ls
hbase-2.5.6-bin.tar.gz# 解压 Hbase 到指定目录
(base) [root@hadoop01 ~]# tar -zxvf hbase-2.5.6-bin.tar.gz -C /bigdata/
(base) [root@hadoop01 ~]# cd /bigdata/
(base) [root@hadoop01 /bigdata]# mv hbase-2.5.6 hbase# 配置环境变量
(base) [root@hadoop01 /bigdata]# vim /etc/profile
# hbase
export HBASE_HOME=/bigdata/hbase
export PATH=$PATH:$HBASE_HOME/bin# 使用 source 让配置的环境变量生效
(base) [root@hadoop01 /bigdata]# source /etc/profile
1.4 HBase 的配置文件
1.4.1 hbase-env.sh
[root@hadoop01 /bigdata]# cd /bigdata/hbase/conf/
[root@hadoop01 /bigdata/hbase/conf]# vim hbase-env.sh # 关闭 hbase 自带zk,使用自己搭建的 zookeeper 集群
export HBASE_MANAGES_ZK=false
# 设定 hbase 的内存为 2G,生产环境中可开启设置
#export HBASE_HEAPSIZE=2G
# 增加系统环境配置, 必须在/etc/profile定义JAVA_HOME
source /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_381
# 存放 PID 文件的目录
export HBASE_PID_DIR=/bigdata/hbase/pids
# 避免 master 启动报错类冲突
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
1.4.2 hbase-site.xml
[root@hadoop01 /bigdata/hbase/conf]# vim hbase-site.xml
<!-- hbase 在 hdfs 中的存储位置, 如果 hdfs 是 ha 模式, 那就把 hadoop01 换成逻辑集群名(比如我的是 mycluster,可在你的 hadoop 配置文件 core-site.xml 查看) 并且创建 hdfs-site.xml 软连接 --><!-- hbase 在 hdfs 中的存储位置 --><property><name>hbase.rootdir</name><value>hdfs://hadoop01/hbase</value></property><!-- 开启 hbase 的全分布式 --><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- zookeeper 的端口号 --><property><name>hbase.zookeeper.property.clientPort</name><value>2181</value></property><!-- zookeeper 集群的主机名 --><property><name>hbase.zookeeper.quorum</name><value>hadoop01,hadoop02,hadoop03</value></property><!-- hbase 的临时文件存储路径 --><property><name>hbase.tmp.dir</name><value>/bigdata/hbase/tmpdata</value></property><!-- 开启配置防止 hmaster 启动问题 --><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property><!-- 监控页面端口 --><property><name>hbase.master.info.port</name><value>60010</value></property>1.4.3 regionservers
[root@hadoop01 /bigdata/hbase/conf]# vim regionservers
hadoop01
hadoop02
hadoop031.4.4 创建目录
[root@hadoop01 ~]# mkdir -p /bigdata/hbase/tmpdata# 如果 hadoop 是集群模式(HA 模式),则执行以下步骤
(base) [root@hadoop01 ~]# ln -s /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/core-site.xml /bigdata/hbase/conf/core-site.xml
(base) [root@hadoop01 ~]# ln -s /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/hdfs-site.xml /bigdata/hbase/conf/hdfs-site.xml
1.5 HBase 远程发送到其他节点
[root@hadoop01 ~]# scp -r /bigdata/hbase 192.168.170.137:/bigdata/hbase
[root@hadoop01 ~]# scp -r /bigdata/hbase 192.168.170.138:/bigdata/hbase# 并修改 /etc/profile 环境变量(其他节点),同 1.3 的步骤一样
1.6 HBase 服务的启动
1.6.1 单点启动(推荐)
# 只启动本节点 master
hbase-daemon.sh start master# 启动所有从节点
hbase-daemon.sh start regionserver1.6.2 群启
# 只启动本机器的 master 和所有机器的从节点, 不推荐, 推荐使用 daemon 脚本
start-hbase.sh[root@hadoop01 ~]# jps
1264 RunJar
2512 JournalNode
1442 RunJar
2212 DataNode
2789 DFSZKFailoverController
3189 ResourceManager
1734 QuorumPeerMain
3382 NodeManager
7368 HMaster
2028 NameNode
7614 HRegionServer
7711 Jps
1.6.2 停止服务
# 只停止本节点的 master 和所有节点的 regionserver
stop-hbase.sh1.7 查看 HBase 页面
启动成功后,可以通过 “192.168.170.136:60010” 的方式来访问 HBase 管理页面,例如:

1.8 高可用(推荐)
在 HBase 中 HMaster 负责监控 HRegionServer 的生命周期,均衡 RegionServer 的负载,如果 HMaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以 HBase 支持对 HMaster 的高可用配置。
# 可以随意选择任意一个节点作为 Backup Master,这里我以 hadoop02节点
(base) [root@hadoop02 /bigdata/hbase/conf]# hbase-daemon.sh start master
(base) [root@hadoop02 /bigdata/hbase/conf]# jps
1570 DataNode
35123 Jps
1701 JournalNode
34694 HRegionServer
1865 DFSZKFailoverController
2009 ResourceManager
2121 NodeManager
1338 QuorumPeerMain
1466 NameNode
35050 HMaster
访问 Backup Master 页面:192.168.170.137:60010

刷新 hadoop01 页面: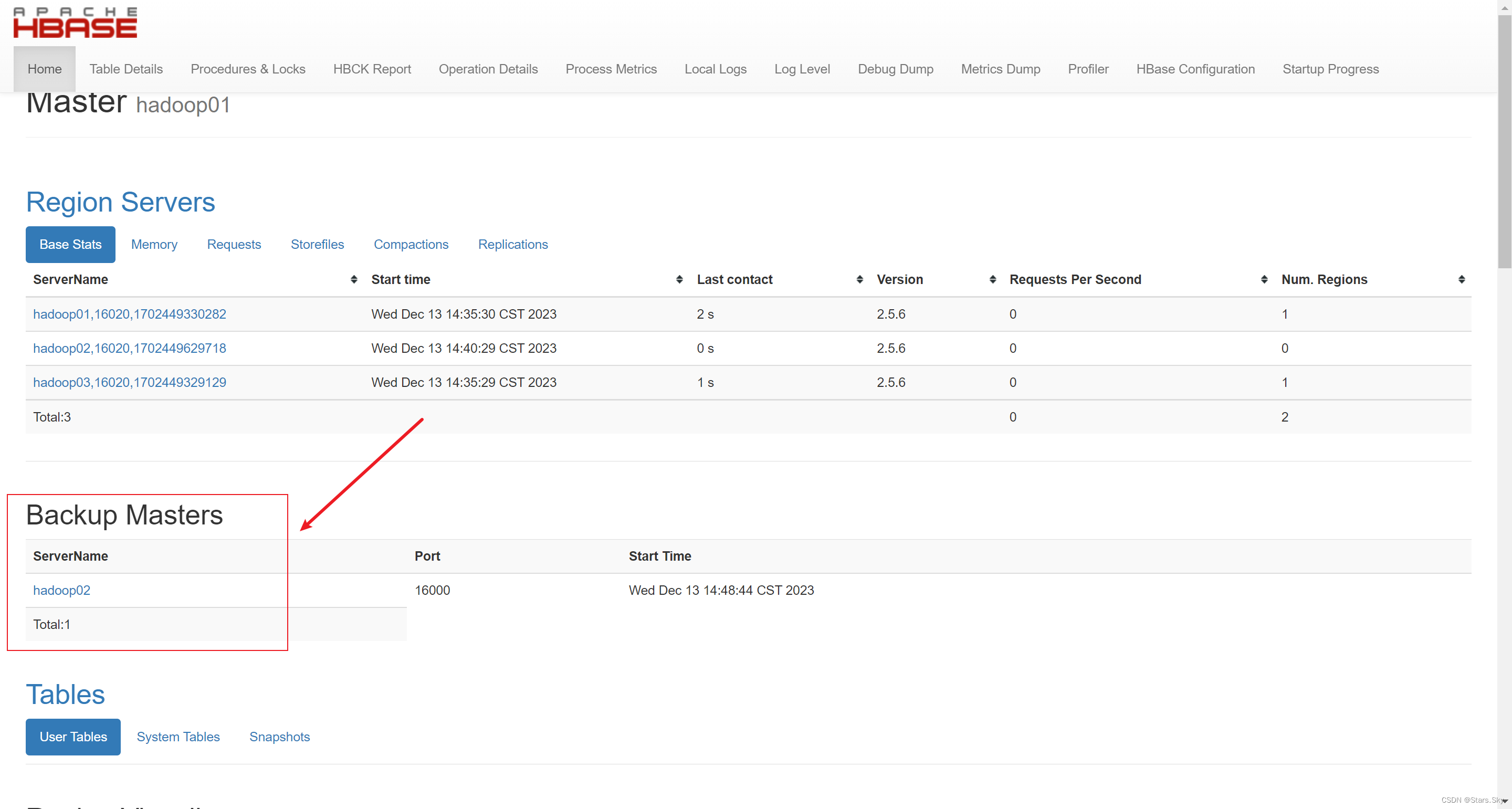
至此 HBase 高可用集群部署完毕!
二、HBase 集群扩缩容
在新节点初始化并拷贝安装目录。
# 在新节点启动 master
hbase-daemon.sh start regionserver# 修改各节点的 conf/regionservers,增加新节点的 ip
vi conf/regionservers# 进入 hbase shell, 开启重新分配 region 数据, 这是hbase的一个周期性工作, 默认 5 分钟
hbase shell
balance_switch true# 执行命令查看当前 hbase 的负载均衡 balance 是否开启
# 注意这个命令没有写错, 不是 balance_switch status, status 是将 balance 状态强制转换为 false
balancer_enabled# 立即进行一次均衡操作
# 当前各节点的 region 数量可以在前端页面查看
balancer上一篇文章:HBase 详细图文介绍-CSDN博客