【项目实战】32G的电脑启动IDEA一个后端服务要2min,谁忍的了?
一、背景
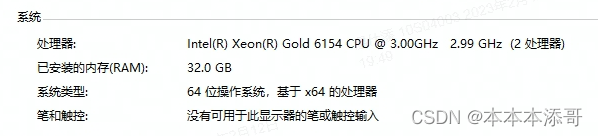
本人电脑性能一般,但是拥有着一台高性能的VDI(虚拟桌面基础架构),以下是具体的配置
二、问题描述
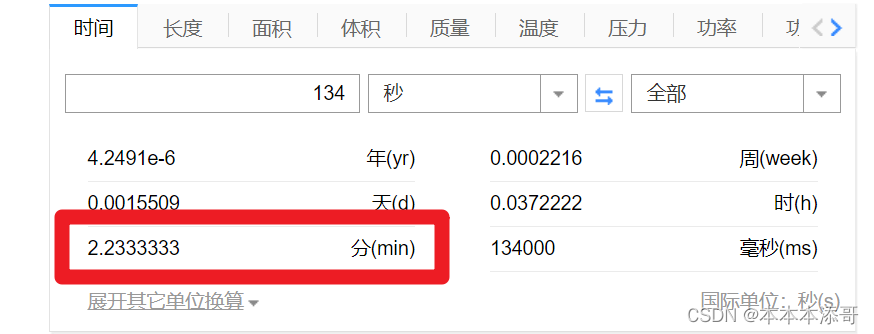
但是,即便是拥有这么高的性能,每次运行基于Dubbo微服务架构下的微服务都贼久,以下是启动一次所消耗的时长

使用百度的时间转换的计算耗时,好家伙,启动一次竟然要耗时2.2min分钟
跟同事讨论了这个项目的启动时长,同事A说是我的IDEA的问题,同事B说是我电脑的问题。
本着一探究竟的精神,耗时了一个下午,我倒要看看究竟是那个应用在拖后腿!
三、问题跟踪与解决
3.1 重启IDEA和VDI
重新启动了IDEA。关闭了所有的IDEA中的进程,以确保不是IDEA在拖后腿。
重新启动了VDI,VDI如果在定期杀毒的话,也会拖后进程的。
3.2 关闭devtools模式
热部署一般是开发过程中使用:开发者不想因为修改内容后重启server浪费大量的时间,而是希望修改代码后能够快速加载自己修改的方法或者类。节省开发时间,为开发者提供改好的开发体验。使用热部署之后,它会监督spring项目修改点,把修改点的java文件编译成class文件,然后替换掉修改前的class文件,不用再去重新部署。
之前有尝试过,但是各种限制总是不顺利,尤其现在有了JRebel,这个基本上用不了,于是考虑不再使用。
找到POM文件,直接注释掉devtools的使用。
关闭devtools模式后的效果并不明显。
3.3 关闭项目启动时,初始化字典到缓存的打印
查看打印日志,发现总是会输出以下的脚本,什么鬼?启动一次就打印一次,这不是浪费时间吗?去掉!
JDBC Connection [org.apache.shardingsphere.driver.jdbc.core.connection.ShardingSphereConnection@537236d3] will not be managed by Spring
==> Preparing: select dict_id, dict_name, dict_type, status, create_by, create_time, remark from sys_dict_type
==> Parameters:
<== Columns: dict_id, dict_name, dict_type, status, create_by, create_time, remark
<== Row: 1, 系统开关, sys_normal_disable, 0, admin, 2018-03-16 11:33:00, 系统开关列表
<== Row: 123, 数据状态, ipds_data_status, 0, admin, 2020-08-11 16:38:25, null
<== Row: 125, 漏洞类型, idps_loophole_type, 0, admin, 2020-08-12 16:30:22, null
<== Row: 127, 严重等级, idps_loophole_grade, 0, admin, 2020-08-12 16:34:24, 漏洞严重等级
<== Total: 4
Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@636226a9]
Creating a new SqlSession
SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@1a9a2c28] was not registered for synchronization because synchronization is not active
JDBC Connection [org.apache.shardingsphere.driver.jdbc.core.connection.ShardingSphereConnection@1287e60e] will not be managed by Spring
==> Preparing: select dict_code, dict_sort, dict_label, dict_value, dict_type, css_class, list_class, is_default, status, create_by, create_time, remark from sys_dict_data where status = '0' and dict_type = ? order by dict_sort asc
==> Parameters: sys_normal_disable(String)
<== Columns: dict_code, dict_sort, dict_label, dict_value, dict_type, css_class, list_class, is_default, status, create_by, create_time, remark
<== Row: 6, 1, 正常, 0, sys_normal_disable, , primary, Y, 0, admin, 2018-03-16 11:33:00, 正常状态
<== Row: 7, 2, 停用, 1, sys_normal_disable, , danger, N, 0, admin, 2018-03-16 11:33:00, 停用状态
<== Total: 2
因为模块涉及到dict,所以很快定位到是数据字典模块的功能。
/**
* 项目启动时,初始化字典到缓存
*/
@PostConstruct
public void init() {List<SysDictType> dictTypeList = dictTypeMapper.selectDictTypeAll();for (SysDictType dictType : dictTypeList) {List<SysDictData> dictDataList = dictDataMapper.selectDictDataByType(dictType.getDictType());DictUtils.setDictCache(dictType.getDictType(), dictDataList);}
}
这一段代码中,使用了@PostConstruct,这个注解的介绍如下
从Java EE5规范开始,Servlet中增加了两个影响Servlet生命周期的注解,@PostConstruct和@PreDestroy,这两个注解被用来修饰一个非静态的void()方法。@PostConstruct是Java自带的注解,在方法上加该注解会在项目启动时执行该方法,也可以理解为在spring容器初始化的时候执行该方法。
注意:在方法上加@PostConstruct注解会在项目启动时执行该方法
因此解决方案也很简单,直接注释掉这个注解即可。
3.4 给XXL-job增加一个开关
看以下截图,发现每次都会进行XXL-job的init的动作。
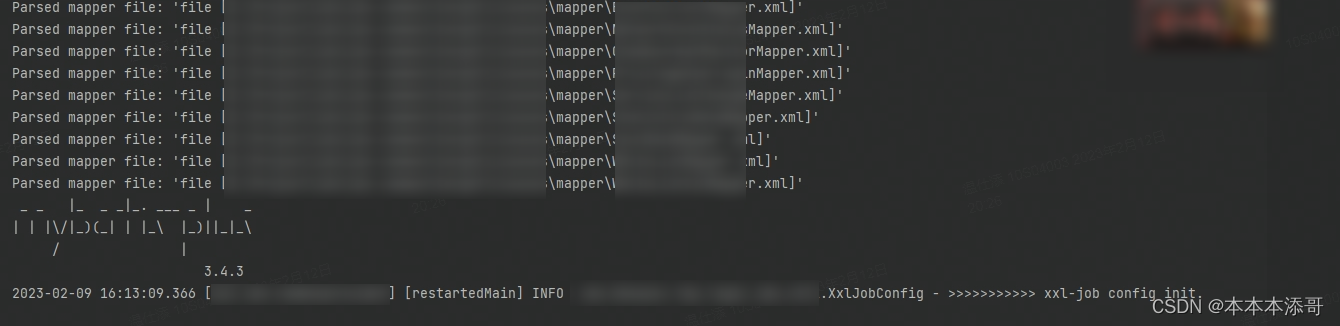
溯源这个的打印处,发现了如下代码
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {log.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;
}
难怪了,本机每次启动都会把自己注册到XXL-job的服务端。
因此,是否可以设计一个开关,让本机的服务不注册到XXL-job的服务端呢。于是有了以下的代码改善。
3.4.1 新增一个enabled字段,用于动态控制注册动作。
@Configuration
@Slf4j
public class XxlJobConfig {@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.accessToken}")private String accessToken;@Value("${xxl.job.executor.appname}")private String appname;@Value("${xxl.job.executor.address}")private String address;@Value("${xxl.job.executor.ip}")private String ip;@Value("${xxl.job.executor.port}")private int port;@Value("${xxl.job.executor.logpath}")private String logPath;@Value("${xxl.job.executor.logretentiondays}")private int logRetentionDays;/*** 开关,默认关闭*/@Value("${xxl.job.enabled}")private Boolean enabled;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {if (enabled) {log.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}return null;}
}
3.4.2 配置文件中新增开关的配置
xxl.job.enabled=true
3.5 关闭断点(最重要的点)
大家都知道在项目Debug过程中,使用Debug模式运行项目会太慢,往往会比正常直接运行要慢上将近三倍的时间
但是其中的原因却很少人说的清楚,其实是因为使用Debug模式运行时,我们会在某些方法上打了断点(像我,就往往会忘记关闭这些断点),而这种情况会出现Method breakpoints may dramatically slow down debugging的提示,这类提示有时会提示你,有时不会提示你。
解决方案:
3.5.1 返选取消所有断点
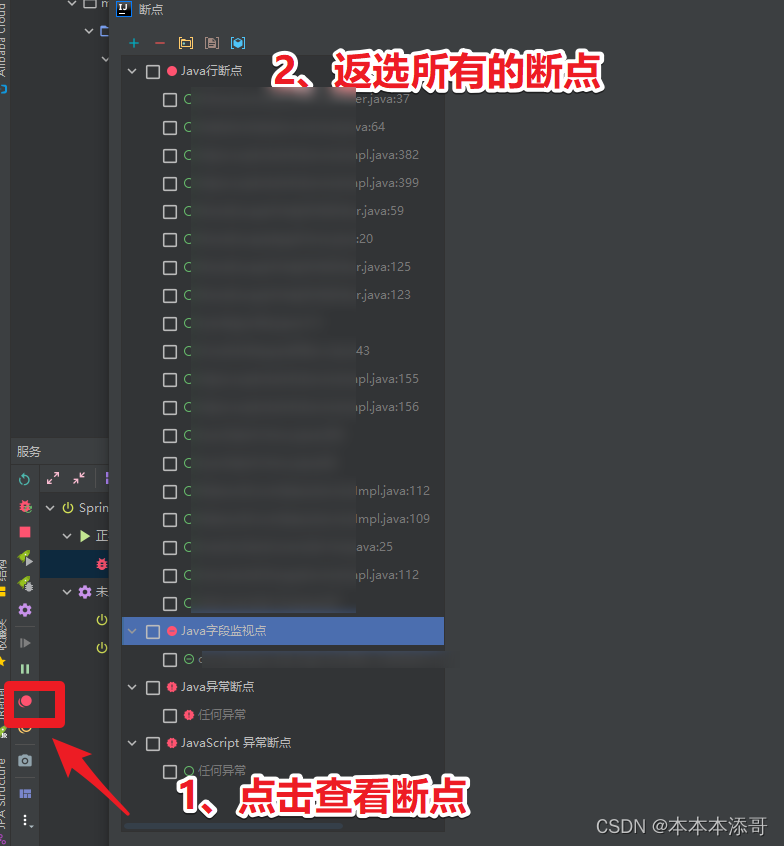
将Java Method Breakpoints下的选项的勾都去掉。
3.5.2 直接点击静音断点
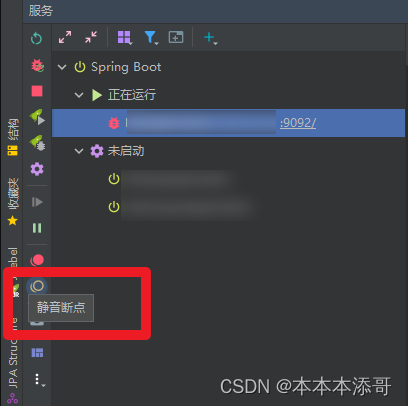
四、问题验证
Started Application in 19.06 seconds
解决后,重新使用debug模式启动,发现启动时间直接降低下拉啦,撒花。