正则表达式及文本三剑客grep sed awk
目录
正则表达式
1.元字符
2.表示次数
3.位置锚定
4.分组或其他
grep
sed
语法:
常用选项
脚本格式
例:
查找11点56到12点10的日志
修改文件,找到文件并给其后缀加上er
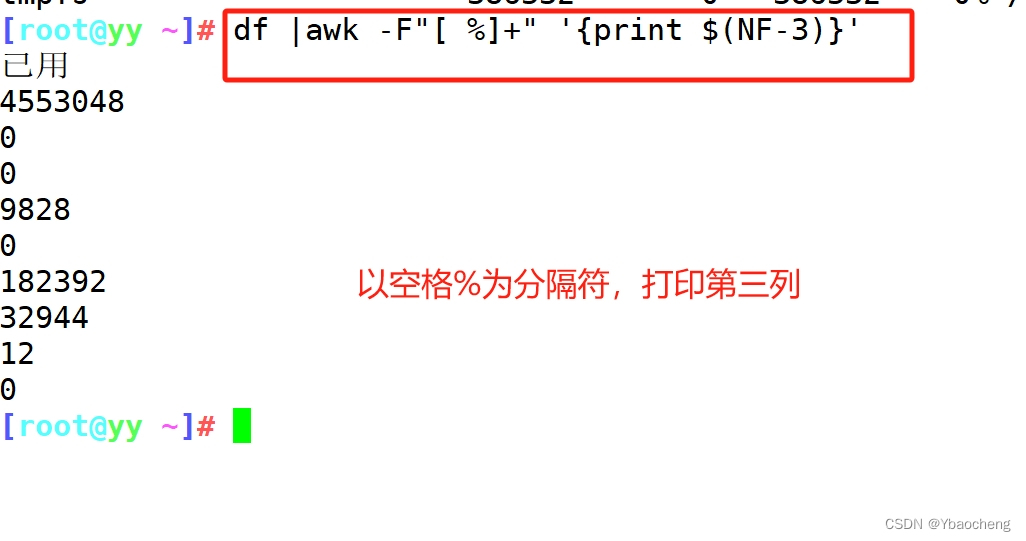
提取IP地址
提取版本号
提取文件权限
awk
工作原理:
格式:
正则表达式
1.元字符
. //匹配任意单个字符,可以是个汉字
[yang] //匹配范围内的任意单个字符
[^y] //匹配处理指定范围外的任意单个字符
[:alnum:] //字母和数字
[:alpha:] //代表任何英文大小写字符
[:lower:] //小写字母
[:upper:] //大写字母
[:blank:] //空白字符
[:space:] //包括空格、制表符
[:cntrl:] //不可打印的控制字符



2.表示次数
* //匹配前面的字符任意次包括0次
.* //任意长度的任意字符,不包括0次
\{n\} //匹配前面的字符n次
\{m,n\} //匹配前面的字符至少m次,至多n次
\{,n\} //匹配前面的字符至多n次
\{n,\} //匹配前面的字符至少n次


3.位置锚定
^ //行首锚定, 用于模式的最左侧
$ //行尾锚定,用于模式的最右侧
^PATTERN$ //用于模式匹配整行
^$ //空行
\< 或 \b //词首锚定,用于单词模式的左侧
\> 或 \b //词尾锚定,用于单词模式的右侧
\<PATTERN\> //匹配整个单词



4.分组或其他

grep
grep
-color=auto //对匹配到的文本着色显示
-m //匹配#次后停止
-v //显示不被pattern匹配到的行,即取反
-i //忽略字符大小写
-n //显示匹配的行号
-c //统计匹配的行数
-o //仅显示匹配到的字符串
-q //静默模式,不输出任何信息
-A # after //后#行
-B # before //前#行
-C # context //前后各#行
-e //实现多个选项间的逻辑or关系
-w //匹配整个单词
-E //使用ERE,相当于egrep
-F //不支持正则表达式,相当于fgrep
-f //file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件
-r //递归目录,但不处理软链接
-R //递归目录,但处理软链接sed
语法:
sed [选项] '脚本语法' [标准输入]常用选项
-n //关闭自动打印
-e //多点编辑
-f //从指定文件中读取编辑脚本
-r //使用扩展正则表达式
-i.bak //备份文件并原处编辑脚本格式
p //打印当前模式空间内容
Ip //忽略大小写输出
d //删除模式空间匹配的行
a //在指定行后面追加文本
i //在行前插入文本
c //替换行为单行或多行文本例:











sed -i.bak //实际修改之前先备份一个带后缀的同名文件
查找11点56到12点10的日志
sed -n '/2023:11:56/,/2023:12:10/p' /var/log/messages修改文件,找到文件并给其后缀加上er

提取IP地址
ifconfig ens33|sed -nr '2s/.*inet (.*) netmask.*/\1/p'
提取版本号
cat text|sed -nr 's/.*-(.*).jar/\1/p'
提取文件权限
stat text|sed -nr '4s#.*([0-9]{4}).*#\1#p'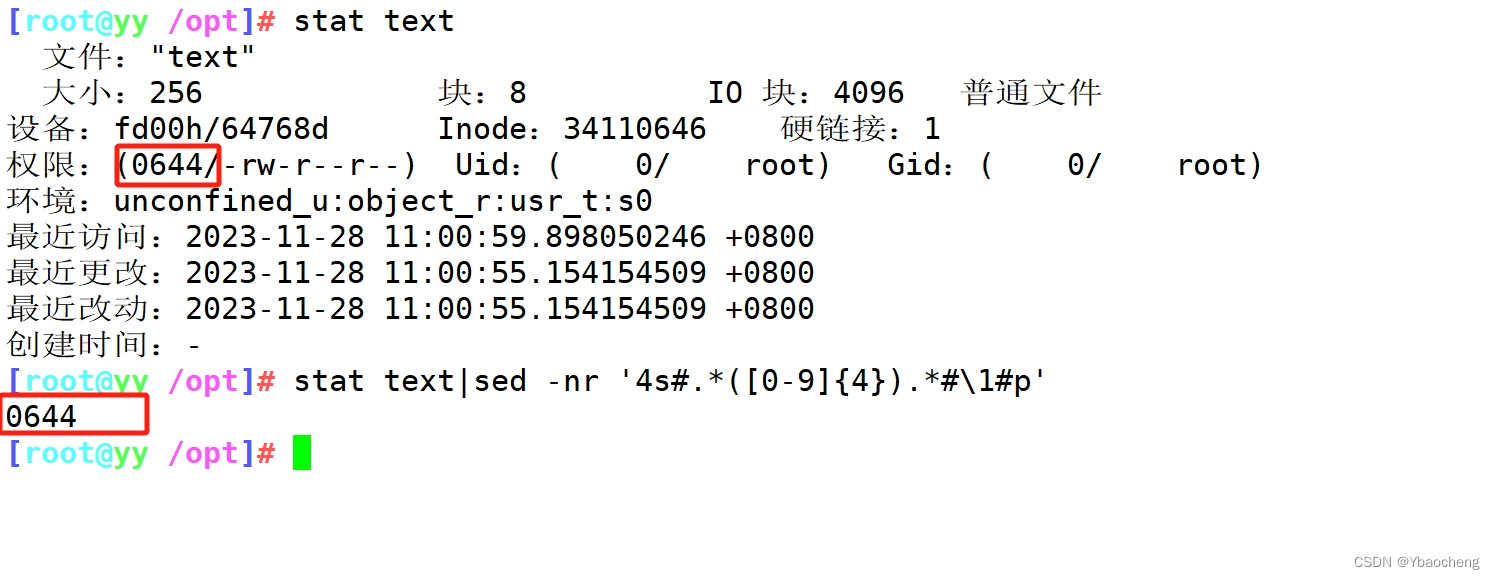
awk
工作原理:
awk 比较倾向于将一行分成多个“字段”然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。
格式:
awk 选项 模式 处理动作-F(大写) //指定分隔符-v //自定义变量-f //脚本
//处理动作
print:打印
printf:打印
//awk内置变量
NF:当前处理的行的字段个数
NR:当前处理的行的行号(序数)
$0:当前处理的行的整行内容
$n:当前处理行的第n个字段(第n列)