牛客网Python篇数据分析习题(一)
1.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
你可以使用pandas打开文件,偷偷看一下里面的内容,请输出你看到的前6行数据。
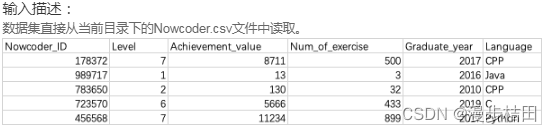
import pandas as pdNowcoder=pd.read_csv("Nowcoder.csv",sep=",",dtype=object)print(Nowcoder[1:6])
2.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
你不需要输出全部数据,请直接告诉我们这个数据集的大小,即行数与列数。
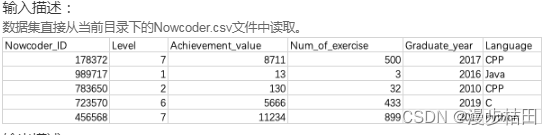
import pandas as pddata = pd.read_csv("Nowcoder.csv", dtype="object")print(data.shape)
3.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
现在牛牛想知道这个数据集中第10行的用户的全部信息,请你帮他输出一下。
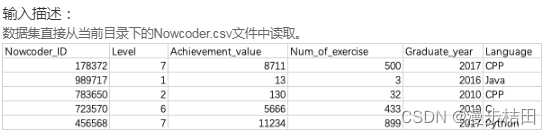
import pandas as pdNowcoder = pd.read_csv('Nowcoder.csv')print(Nowcoder.iloc[10])
4.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
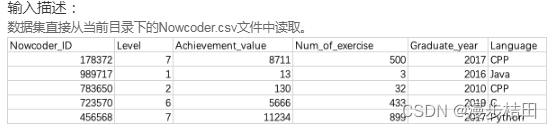
现在牛牛想知道这个数据集中第10行到第20行用户的常用语言分别是什么,请你帮他输出一下。

import pandas as pddf = pd.read_csv("Nowcoder.csv")print(df.loc[10:20, "Language"])5.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
如果你想知道这份数据是不是所有列的信息都是有数据的,有没有哪些列的数据没有补全,请输出每列信息是否有为空值。
import pandas as pda=pd.read_csv('Nowcoder.csv')print(a.isnull().all())
6.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
如果你想知道哪些人经常使用Python这门语言,并且他们的其他信息是怎么样的,该怎么输出?
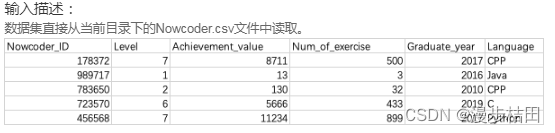
import pandas as pddf=pd.read_csv('Nowcoder.csv',dtype=object)print(df[df['Language']=='Python'])
7.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
假如你正在学习Python,你想知道牛客网的Python用户的成就值都有多高,请问该如何输出?
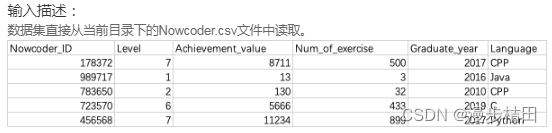
import pandas as pddf=pd.read_csv('Nowcoder.csv',dtype=object)
df0=df[df['Language']=='Python']print(df0.iloc[:,2])8.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
假设你想查看该文件最后5行用户的用户ID、等级、成就值、常用语言,请尝试输出。
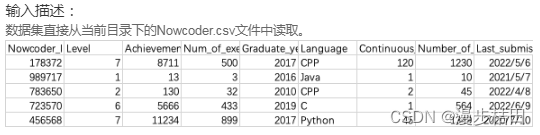
import pandas as pdNowcoder = pd.read_csv("Nowcoder.csv", sep=",")
a = Nowcoder.tail()print(a[["Nowcoder_ID", "Level", "Achievement_value", "Language"]])