禁奥义·SQL秘籍
sql secret scripts
sql 语法顺序、执行顺序、执行过程、要点解析、优化技巧。
1、语法顺序
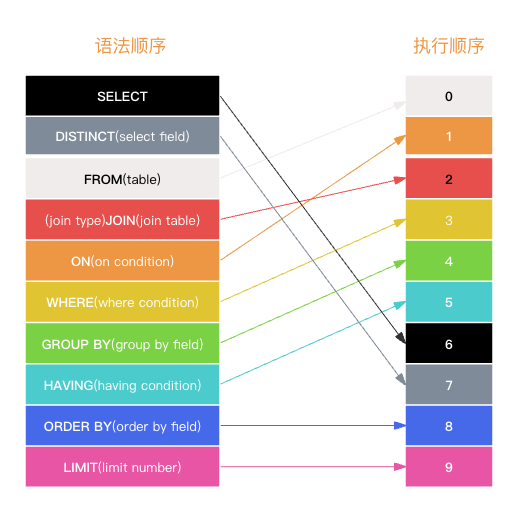
如上图所示,为 sql 语法顺序与执行顺序对照图。其具体含义如下:
- 0、select: 用于从数据库中选取数据,即表示从数据库中查询到的数据的列。其后可跟列名、函数、子查询等。
- 1、distinct: 用于对结果集进行去重,即若查询的数据中存在重复项,则可用其进行去重。其需要放在 select 后第一顺位,且其去重并不是对 select 后某个字段进行去重,而是对 select 后所有列进行去重。
- 2、from: 表示要查询的数据库表,即主表。其后跟表名、子查询等。
- 3、join: 表示要连接的表,及关联表。其后跟要连接表名、子查询等。
- 4、on: 表示主表与关联表的关联条件。
- 5、where: 表示查询条件。其后可跟普通条件、函数(普通函数)等。
- 6、group by: 表示分组,及将数据按照分组条件进行分组。其后跟要分组的列名。
- 7、having: 对分组结果进行筛选。其后跟普通条件、聚合函数等。
- 8、order by: 表示排序,及将结果集按照某种条件进行排序。其后跟要排序的列名及排序方式(升序、降序)。
- 9、limit: 表示最终结果集的大小,即查询结果集的大小将 <= limit 的值。其后跟数据集大小。
如上所述,则对于表 用户表 web_user(id, username, age, gender, address)、系统日志表 sys_log(id, user_id, operate_name, request_time, request_params),其查询 sql 可为:
# 某些数据库中 user 字符为关键字 故此 sql 中 user 别名呈关键字色
select distinct user.username, log.operate_name
from sys_log logleft join web_user useron log.user_id = user.id
where log.operate_name like '%列表%'
group by user.username, log.operate_name
having avg(log.request_time) > 100
order by user.username desc
limit 10
2、执行顺序
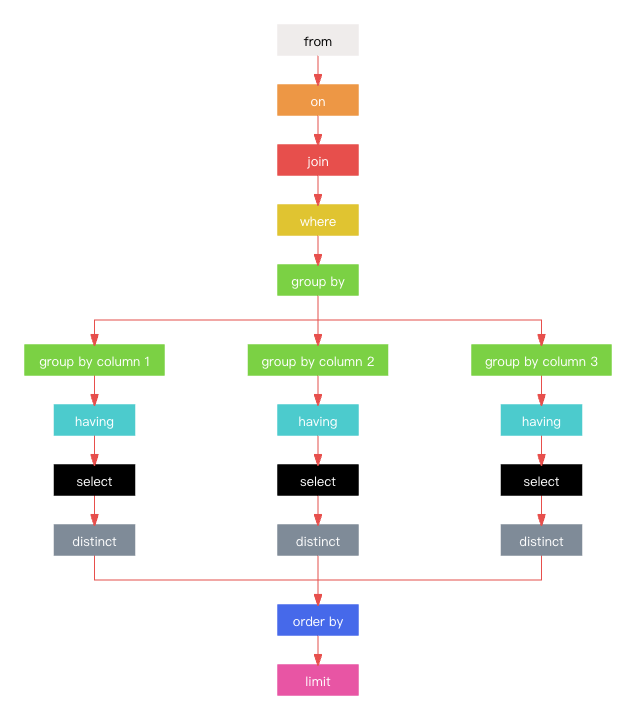
如上图所示,为 sql 实际执行顺序。在 sql 的实际执行过程中,每个步骤都会产生一个虚拟表,这个虚拟表将作为下一步的基础数据。其具体含义如下:
- 0、from: 选择要查询的基表(即主表),产生虚拟表 1。
- 1、on: 连接查询(join)时主表与关联表的关联条件。将关联条件匹配到的行记录在虚拟表 2。
- 2、join: 选择要关联的表。若为 left/right join,则将主表中关联条件为匹配到的行添加到虚拟表 2,产生虚拟表 3。若有多个关联表,则重复执行 0~2 步,直到所有关联表都处理完。
- 3、where: 使用过滤条件对虚拟表 3 进行过滤,将符合条件的行插入到虚拟表 4。
- 4、group by: 根据 group by 指定的列,对虚拟表 4 进行分组,产生虚拟表 5。
- 5、having: 根据 having 指定的过滤条件对 虚拟表 5 中的每一组记录进行过滤,将符合条件的的行插入到虚拟表 6。
- 6、select: 从虚拟表 6 中取出 select 指定的列的记录插入到虚拟表 7。
- 7、distinct: 将虚拟表 7 中重复的行删除(记录的唯一性),产生虚拟表 8。
- 8、order by: 对虚拟表 8 中的记录按照 order by 指定的列及指定的排序方式进行排序。
- 9、limit: 取出指定行数的记录,返回结果集。
3、要点解析
-
distinct: 其作用是对记录进行去重,去重时不是根据 distinct 后的某个字段去重,而是根据其后的所有字段去重,即可以理解为其后所有字段构成的唯一主键。一般而言,distinct 是 group by 子句的特殊情况,若对 distinct 结果集进行排序则可得到 group by 同样的结果。同时,distinct 会讲 null 值当作一条记录返回。
当想要根据某个或某几个字段去重,同时又要查出其它字段时,则可以结合 group by 来实现,如想根据 username 去重,同时查询出 id,则其 sql 可为:
# 此方案不适配 mysql select id, count(distinct username) from sys_log group by username; -
join: 关联查询,分为四种类型,分别是:
- inner join:内连接,即左右两个表中至少匹配到一条记录则返回。
- left join:左连接,即使右表(关联表)中没有匹配到行,也返回左表(主表)中的所有行。
- right join:右连接,即使左表(关联表)中没有匹配到行,也返回右表(主表)中的所有行。
- full join:全连接,只要有一个表中匹配到行,则返回。
join 时要注意 on 条件,on 条件作为左右两表的关联条件,直接决定了后续 where 时的数据量,所以尽可能的在 on 中筛选掉无用数据。若无 on 条件则会出现笛卡尔积现象。
-
where: where 条件中只能使用普通条件(如 and、or、in 等)和普通函数(ucase()、lcase()、mid()、substring()、len()、round()、now()、format() 等),不能使用聚合函数(avg()、max()、min()、count()、first()、last()、sum() 等)。
-
not、and、or: 逻辑运算符。
- and:若 and 前后两个条件都成立,则 and 运算符显示一条记录。
- or:若 or 前后两个条件只要一个成立,则 or 运算符显示一条记录。
- not:表示非。
逻辑运算符使用需要注意优先级,其优先级为 ( )、not、and、or。所以必要时需使用 ( ) 来确保 and 和 or 条件的先后顺序。
-
between: between 的使用需要注意上下限,而其上下限由不同数据库的实现决定。如:
- 在某些数据库中,between 选取介于两个值之间但不包括两个值的数据。
- 在某些数据库中,between 选取介于两个值之间且包括两个值的数据。
- 在某些数据库中,between 选取介于两个值之间但只包括第一个值不包括第二个值的数据。
-
group by: group by 表示分组,其规定 group by 后跟的列需和 select distinct 后跟的列保持一致,若此时还需要查出其它字段,则可以使用 rank() over (parition by) 关键字实现。
rank() over (partition by):其中 rank() 是排序函数,其会对结果集排序并产生一个序号;partition by 为分组,若无指定则所有结果集默认一个组。如想按 operate_name 分组,同时又想查出 username、operate_name 列,则 sql 可为:
# order by 是为了对 partition by 分组结果进行排序,所以 order by 列尽可能使用 id 这种差异性极强的列来排序(如唯一索引) # 只有排序后每条记录的 rankNo 值都不同,才能根据 rankNo = 1 取到唯一的一条记录 select * from (select username, operate_name, rank() over (partition by operate_name order by id) rankNo from sys_log) as temp where temp.rankNo = 1 -
having: 对分组后的结果进行筛选,其后只能跟普通条件和聚合函数(avg()、max()、min()、count()、first()、last()、sum() 等)。
-
order by: order by 表示排序,需要注意多字段排序的情况。如 order by a, b,先根据字段 a 的值排序,然后对 a 列相同的行再根据字段 b 的值排序。
-
union: union 用来合并两个或多个 select 的结果集。需注意,使用 union 时,多个 select 语句必须拥有相同数量的列,且列的数据类型需保持一致,select 列的先后顺序也要保持一致。
-
limit: limit 语句用来截取指定条数的结果集,一般用在分页中,如以下 sql:
select * from sys_log where operate_name = '列表' limit 1000000, 10其含义为查询出第 1000000 行及之后的 9 行,但在实际执行中会发现耗时较长。这是因为数据库也不知道第 1000000 行从什么地方开始,因此需要先找到第 1000000 行,然后再取出 10 条。此时则可以将上一页的最大值作为查询条件传入,则 sql 如下:
# 假设上一页最后一条数据的 create_time 值为 2023-11-30 22:25:00 select * from sys_log where operate_name = '列表' and create_time > '2023-11-30 22:25:00' limit 10此时会发现,耗时将大大减小。