kafka精准一次、事务、幂等性
Kafka事务
消息中间件的消息保障的3个级别
- At most once 至多一次。数据丢失。
- At last once 至少一次。数据冗余
- Exactly one 精准一次。好!!!
如何区分只要盯准提交位移、消费消息这两个动作的时机就可以了。
当:先消费消息、再提交位移。
如果提交位移这一步挂了,就会再消费一遍消息。重复消费====》〉》至少一次
当:先提交位移、再消费消息。
提议位移成功、消费消息失败,那么数据就丢失了====》〉》至多一次
如何精准一次呢?
幂等和事务!
幂等
对接口的多次调用所产生的结果和一次调用的结果是一样的。
即:(第一次调用,中途挂了,再次调用==一次调用) 为true
如何实现?
在v2版本的消息存储格式用有两个字段。produce_id(简称pid) 、first sequence
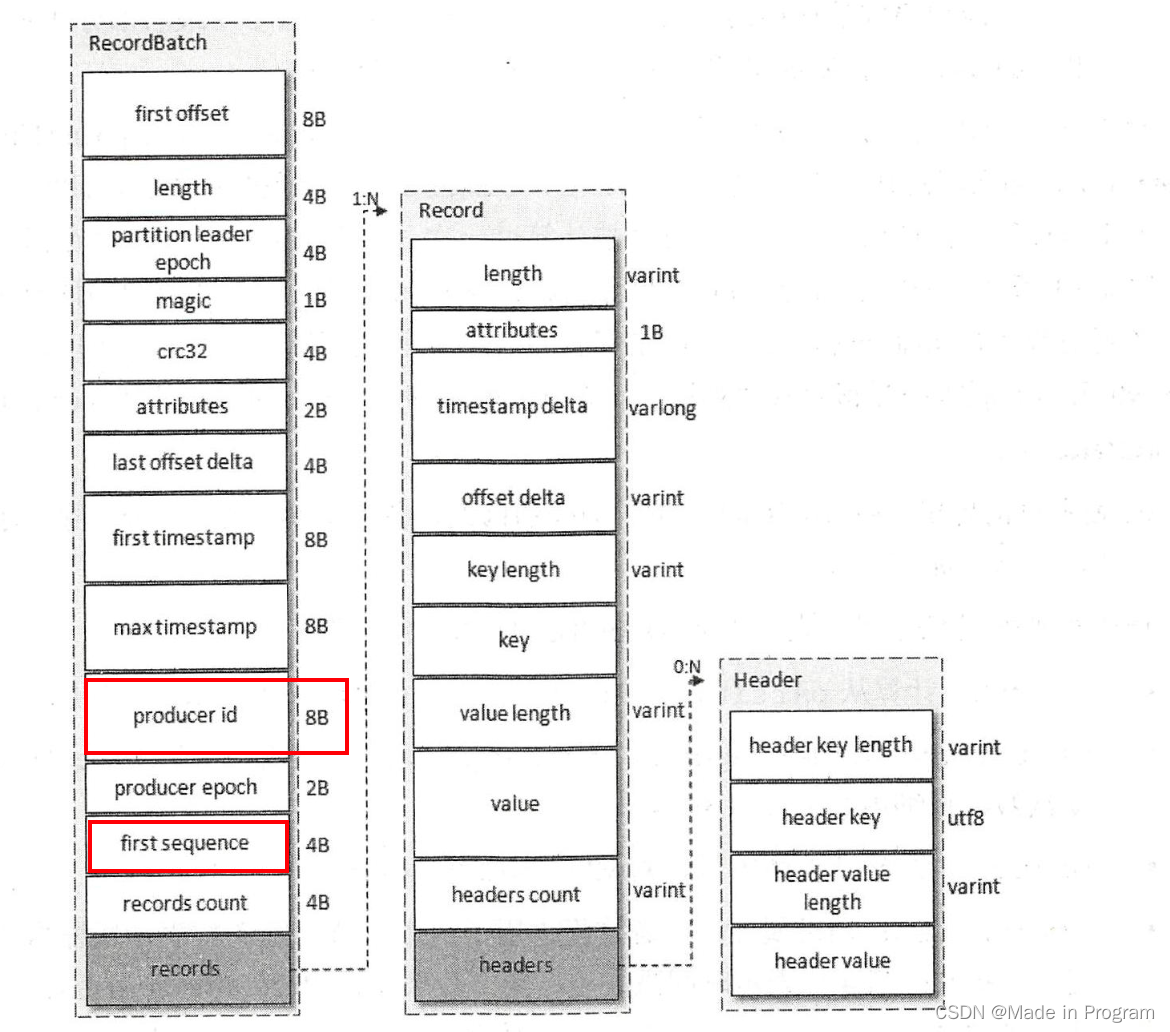
每个新的生产者实例在初始化的时候都会被分配一个pid,每个pid,消息发送到每一个分区都有序列号 sequence,序列号会从0开始递增,每发送一条消息,<PID,分区> 对应的序列号的值会➕1。这个序列号值(SN)在broker的内存中维护。只有当SN_new=SN_old+1.
broker才会接收这个消息。
如SN_new < SN_old+1 说明消息重复了,这个消息可以直接丢掉。
如SN_new>SN_old+1 说明消息丢失了,有数据还没有卸写入。抛乱序异常OutOforderSequenceException。
即用序列号来保证消息的顺序消费。
注意 所记录的这个序列号是针对 每一对<PID,分区> 所以这个幂等实现的是单会话、单分区的。
如何保证多个分区之间的幂等性呢?
事务
保证对多个分区写入操作的原子性,要么全部成功、要么全部失败。将应用程序的生产消息、消费消息、提交消费位移当作原子操作来处理。
用户显示指定一个事务id: transactionalId。这个事务id是唯一的
从生产者角度来考虑,事务保证了生产者会话消息的幂等发送 和跨生产者会话的事务恢复.
- 生产者会话消息的幂等发送:如有有两个相同事务id的生产者,新的创建了 旧的就会被kill
- 某个生产者实例宕机了,新的生产者实例可以保证未完成的旧事务要么被提交 要没被中断
实现过程,以consume-transform-produce为例。
package com.hzbank.yjj.transaction;import com.hzbank.yjj.producer.CustomerPartitioner;
import com.hzbank.yjj.producer.ProducerlnterceptorPrefix;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.errors.ProducerFencedException;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;import java.time.Duration;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Properties;public class TransactionConsumeTransformProduce {public static final String brokerList = "localhost:9092";public static Properties getConsumerProps(){Properties props =new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.GROUP_ID_CONFIG,"groupId");props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);return props;}public static Properties getProducerProps(){Properties props =new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"transactionalId");return props;}public static void main(String[] args) {//初始化生产者和消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(getConsumerProps());consumer.subscribe(Collections.singletonList("topic-source"));KafkaProducer<String, String> producer = new KafkaProducer<>(getProducerProps());//初始化事务producer.initTransactions();while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));if(!records.isEmpty()){HashMap<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();//开启事务producer.beginTransaction();try {for (TopicPartition partition : records.partitions()) {List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);for (ConsumerRecord<String, String> record : partitionRecords) {System.out.println("获取到了topic-source发送过来的数据"+record.value());System.out.println("do some ");ProducerRecord<String, String> producerRecord = new ProducerRecord<>("topic-sink", record.key(), record.value());producer.send(producerRecord);}// 获取最近一次的消费位移long lastConsumedOffset = partitionRecords.get(partitionRecords.size() - 1).offset();offsets.put(partition,new OffsetAndMetadata(lastConsumedOffset+1));}//提交消费位移producer.sendOffsetsToTransaction(offsets,"groupId");//提交事务producer.commitTransaction();} catch (ProducerFencedException e) {System.out.println("异常了");producer.abortTransaction();}}}}}1. 找到TransactionCoordinator。
TransactionCoordinator负责分配和管理事务。
FindCoordinatorRequest 发送请求找到TransactionCoordinator所在的broker节点。返回其对应的node_id、 host、 port 信息
transactionalId 的哈希值计算主题_transaction_state 中的分区编号
根据分区leader副本找到所在的broker节点,极为Transaction Coordinator节点
2. 获取pid
通过InitProducerIdRequest向TransactionCoordinator 获取pid 为当前生产者分配一个pid。
String transactionalId; 事务id
int transactionTimeoutMs; 事务状态更新超时时间
3. 保存pid
TransactionCoordinator 第一次收到事务id会和对应pid保存下来,以消息(事务日志消息)的形式保存到主题_transaction_state中,实现持久化
InitProducerIdRequest还会出发一下任务:
- 增加pid对应的producer_epoch.具有相同 PID 但 producer_epoch 小 于该 producer_叩och 的其他生产者新开启的事务将被拒绝 。
- 恢复( Commit)或中止( Ab。此)之前的生 产 者未完成的 事务
4. 开启事务
通过 KafkaProduc町的 beginTransaction()方法。调用该方法后,生产者本 地会标记己经开启了 一个新的事务 ,只有在生产者发送第一条消息之后 TransactionCoordinator 才会认为该事务 己经开启 。
5. Consume-Transform-Produce
整个事务处理数据。
-
AddPartitionsToTxnRequest:让 TransactionCoordinator 将<transactionld, TopicPartition>的对应关系存储在主题
transaction state 中
-
ProduceRequest:生产者通过 ProduceRequest 请求发送消息( ProducerBatch)到用户 自定义主题中
-
AddOffsetsToTxnRequest:TransactionCoordinator 收到这个AddOffsetsToTxnRequest请求,通过 groupId 来推导出在一consumer_offsets 中的分区
-
TxnOffsetCommitRequest:发送 TxnOffsetCommitRequest 请求给 GroupCoordinator,从而将本次事务中 包含的消费位移信息 offsets 存储到主题 consumer offsets 中
6. 提交或者终止事务
KafkaProducer 的 commitTransaction()方法或 abortTransaction()方法。
写不下去了,暂时就先理解这么多了,后面再多结合源码去看看。
参考:书籍《深入理解 Kafka:核心设计与实践原理》