大数据基础设施搭建 - Hive
文章目录
- 一、上传压缩包
- 二、解压压缩包
- 三、配置环境变量
- 四、初始化元数据库
- 4.1 配置MySQL地址
- 4.2 拷贝MySQL驱动
- 4.3 初始化元数据库
- 4.3.1 创建数据库
- 4.3.2 初始化元数据库
- 五、启动元数据服务metastore
- 5.1 修改配置文件
- 5.2 启动/关闭metastore服务
- 六、启动hiveserver2服务
- 6.1 修改配置文件
- 6.2 启动/关闭hiveserver2服务
- 七、访问Hive
- 7.1 通过hive客户端访问
- 7.2 通过beeline客户端访问(JDBC)
- 八、修改元数据库字符集(TODO)
- 8.1 修改hive元数据库中存储注释的字段的字符集为utf-8
- (1)字段注释
- (2)表注释
- 8.2 修改hive-site.xml配置文件
- 九、整合HDFS(TODO)
- 十、升级为hive集群(TODO)
一、上传压缩包
https://hive.apache.org/
二、解压压缩包
[hadoop@hadoop102 software]$ tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
三、配置环境变量
[hadoop@hadoop102 apache-hive-3.1.2-bin]$ sudo vim /etc/profile.d/my_env.sh
新增内容:
#HIVE_HOME
export HIVE_HOME=/opt/module/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin
使环境变量生效:
[hadoop@hadoop102 apache-hive-3.1.2-bin]$ source /etc/profile.d/my_env.sh
四、初始化元数据库
hive元数据概述:记录了hive中表的名称、列名、数据类型、分区信息、数据存储路径等。
hive元数据存储:默认是元数据存储于hive内置的derby数据库,是用Java写的。一定要切换到MySQL,内嵌derby局限性太高!当一个hive客户端启动时,就会独占derby元数据库且不与其他客户端共享元数据,所以无法同时开启多个hive客户端进行操作!
4.1 配置MySQL地址
[hadoop@hadoop102 ~]$ vim $HIVE_HOME/conf/hive-site.xml
新增内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://mall:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><!-- Hive默认在HDFS的工作目录;数据库被创建之后默认存储的位置。 eg:/warehouse/xx_dw_dwb.db --><property><name>hive.metastore.warehouse.dir</name><value>/warehouse</value></property><!-- Hive元数据存储的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property><!-- 元数据存储授权 --><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property>
</configuration>
4.2 拷贝MySQL驱动
[hadoop@hadoop102 ~]$ cp /opt/software/mysql-connector-java-5.1.37.jar $HIVE_HOME/lib
4.3 初始化元数据库
4.3.1 创建数据库
[mall@mall ~]$ mysql -uroot -p123456
mysql> create database metastore;
mysql> quit;
4.3.2 初始化元数据库
-verbose参数:显示初始化过程日志
-dbType:指定数据库类型
[hadoop@hadoop102 ~]$ schematool -initSchema -dbType mysql -verbose
五、启动元数据服务metastore
metastore服务用于访问hive元数据。有两种提供服务的方式,分别是嵌入式模式和独立服务模式。
生产中使用独立服务模式,因为在嵌入式模式下,每个Hive CLI都需要直接连接元数据库,当Hive CLI较多时,数据库压力会比较大。
内嵌式模式:

独立服务模式:
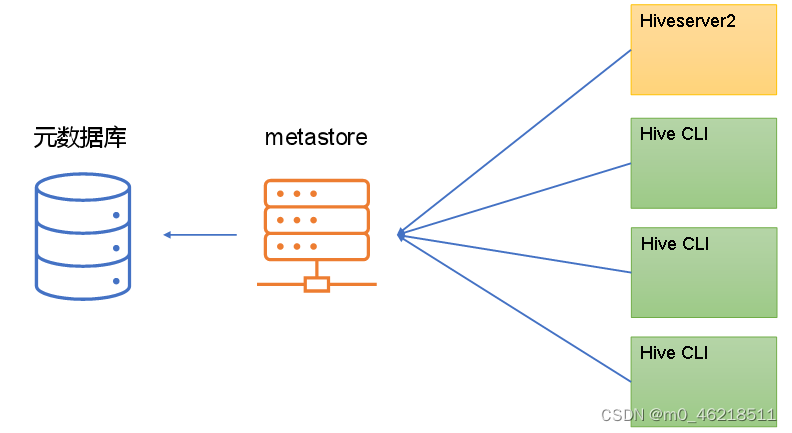
5.1 修改配置文件
如果配置文件中有此项配置,说明hive在连接元数据的时候需要走第三方服务thrift,必须启动独立服务模式metastore服务!
[hadoop@hadoop102 ~]$ vim $HIVE_HOME/conf/hive-site.xml
新增内容:
<!-- hive元数据服务metastore的ip和端口号 --><property><name>hive.metastore.uris</name><value>thrift://hadoop102:9083</value></property>
5.2 启动/关闭metastore服务
# 启动
[hadoop@hadoop102 ~]$ nohup hive --service metastore &>/dev/null 2>/dev/null &
# 关闭
[hadoop@hadoop102 ~]$ ps -ef | grep metastore
[hadoop@hadoop102 ~]$ kill 28832
六、启动hiveserver2服务
6.1 修改配置文件
[hadoop@hadoop102 ~]$ vim $HIVE_HOME/conf/hive-site.xml
新增内容:
<!-- 指定hiveserver2连接的host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop102</value></property><!-- 指定hiveserver2连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property>
6.2 启动/关闭hiveserver2服务
# 启动
[hadoop@hadoop102 apache-hive-3.1.2-bin]$ nohup bin/hive --service hiveserver2 &>/dev/null 2>/dev/null &
# 关闭
[hadoop@hadoop102 ~]$ ps -ef | grep hiveserver2
[hadoop@hadoop102 ~]$ kill 29204
七、访问Hive
7.1 通过hive客户端访问
[hadoop@hadoop102 ~]$ cd /opt/module/apache-hive-3.1.2-bin/
[hadoop@hadoop102 apache-hive-3.1.2-bin]$ bin/hive
查看数据库:
hive> show databases;
OK
default
Time taken: 0.756 seconds, Fetched: 1 row(s)
7.2 通过beeline客户端访问(JDBC)
-u参数:hiveserver2所在ip和端口号
-n参数:账号
[hadoop@hadoop102 apache-hive-3.1.2-bin]$ bin/beeline -u jdbc:hive2://hadoop102:10000 -n hadoop
八、修改元数据库字符集(TODO)
Hive元数据库字符集默认是Latin1,如果建表语句中有中文注释,会出现乱码现象。
8.1 修改hive元数据库中存储注释的字段的字符集为utf-8
以utf-8编码向元数据库中写入数据
mysql -uroot -p
(1)字段注释
use metastore;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
(2)表注释
alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
8.2 修改hive-site.xml配置文件
以utf-8编码从元数据库中读取数据
[hadoop@hadoop102 ~]$ vim $HIVE_HOME/conf/hive-site.xml
修改内容:
<!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://mall:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value></property>
九、整合HDFS(TODO)
将HDFS文件包装成hive中的表