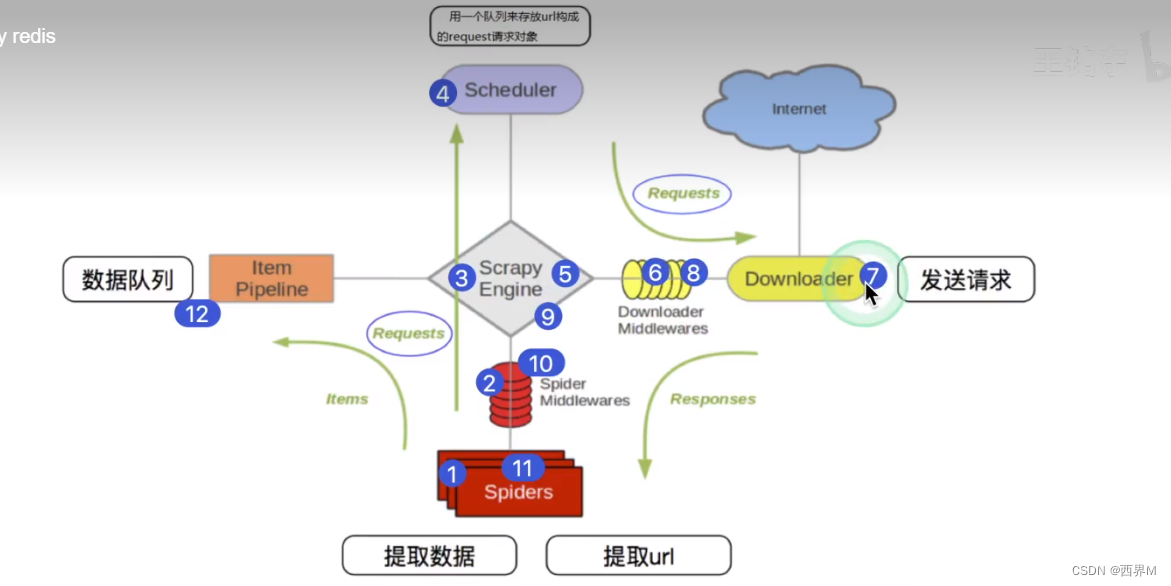
1、Scrapy从Spider子类中提取start_url,然后构造为request请求对象
2、将request请求对象传递给爬虫中间件
3、将request请求对象传递给Scrapy引擎(核心代码)
4、将request请求对象传递给调度器(它负责对多个request安排,好比交通管理员负责指挥交通)
5、将request请求对象传递给scrapy引擎
6、Scrapy引擎将request请求对象传递给下载中间件(可以更换代理IP 更换cookie 更换user-agent,自动重试等)
7、request请求对象传递给到下载器(它通过异步的发送HTTP(s)请求。得到响应封装为response对象)
8、将requests传递给下载中间件
9、下载中间件将response对象传递给scrapy引擎
10、Scrapy 引擎将response对象传递给爬虫中间件(这里可以处理异常情况)
11、爬虫对象中的parse函数被调用(在这里可以得到的response对象进行处理 例如status得到的响应码 ,xpath可以进行提取数据等)
12、第11步调用的yelid管道 调用piplines 对数据进行存储或处理