FastText模型文本分类
项目地址:NLP-Application-and-Practice/07_FastText/7.2-FastText文本分类/text_classification at master · zz-zik/NLP-Application-and-Practice (github.com)
加载数据
load_data.py
# coding: UTF-8
import os
import pickle as pkl
from tqdm import tqdmMAX_VOCAB_SIZE = 10000 # 词表长度限制
UNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号def build_vocab(file_path, tokenizer, max_size, min_freq):vocab_dic = {}with open(file_path, 'r', encoding='UTF-8') as f:for line in tqdm(f):lin = line.strip()if not lin:continuecontent = lin.split('\t')[0]for word in tokenizer(content):vocab_dic[word] = vocab_dic.get(word, 0) + 1vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] >= min_freq], key=lambda x: x[1], reverse=True)[:max_size]vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})return vocab_dicdef build_dataset(config, ues_word):if ues_word:tokenizer = lambda x: x.split(' ') # 以空格隔开,word-levelelse:tokenizer = lambda x: [y for y in x] # char-levelif os.path.exists(config.vocab_path):vocab = pkl.load(open(config.vocab_path, 'rb'))else:vocab = build_vocab(config.train_path, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1)pkl.dump(vocab, open(config.vocab_path, 'wb'))print(f"Vocab size: {len(vocab)}")def load_dataset(path, pad_size=32):contents = []with open(path, 'r', encoding='UTF-8') as f:for line in tqdm(f):lin = line.strip()if not lin:continuecontent, label = lin.split('\t')words_line = []token = tokenizer(content)seq_len = len(token)if pad_size:if len(token) < pad_size:token.extend([PAD] * (pad_size - len(token)))else:token = token[:pad_size]seq_len = pad_size# word to idfor word in token:words_line.append(vocab.get(word, vocab.get(UNK)))# -----------------contents.append((words_line, int(label), seq_len))return contents # [([...], 0), ([...], 1), ...]train = load_dataset(config.train_path, config.pad_size)dev = load_dataset(config.dev_path, config.pad_size)test = load_dataset(config.test_path, config.pad_size)return vocab, train, dev, test迭代加载数据
load_data_iter.py
# coding:utf-8
import torch# 批量加载数据
class DatasetIterater(object):def __init__(self, batches, batch_size, device):self.batch_size = batch_sizeself.batches = batchesself.n_batches = len(batches) // batch_sizeself.residue = False # 记录batch数量是否为整数if len(batches) % self.n_batches != 0:self.residue = Trueself.index = 0self.device = devicedef _to_tensor(self, datas):x = torch.LongTensor([_[0] for _ in datas]).to(self.device)y = torch.LongTensor([_[1] for _ in datas]).to(self.device)# pad前的长度(超过pad_size的设为pad_size)seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)return (x, seq_len), ydef __next__(self):if self.residue and self.index == self.n_batches:batches = self.batches[self.index * self.batch_size: len(self.batches)]self.index += 1batches = self._to_tensor(batches)return batcheselif self.index >= self.n_batches:self.index = 0raise StopIterationelse:batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]self.index += 1batches = self._to_tensor(batches)return batchesdef __iter__(self):return selfdef __len__(self):if self.residue:return self.n_batches + 1else:return self.n_batchesdef build_iterator(dataset, config, predict):if predict is True:config.batch_size = 1iter = DatasetIterater(dataset, config.batch_size, config.device)return iterFastText模型
FastText.py
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as npclass Config(object):"""配置参数"""def __init__(self):self.model_name = 'FastText'self.train_path = './data/train.txt' # 训练集self.dev_path = './data/dev.txt' # 验证集self.test_path = './data/test.txt' # 测试集self.predict_path = './data/predict.txt'self.class_list = [x.strip() for x in open('./data/class.txt', encoding='utf-8').readlines()]self.vocab_path = './data/vocab.pkl' # 词表self.save_path = './saved_dict/' + self.model_name + '.ckpt' # 模型训练结果self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备self.dropout = 0.5self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练self.num_classes = len(self.class_list) # 类别数self.n_vocab = 0 # 词表大小,在运行时赋值self.num_epochs = 5 # epoch数self.batch_size = 128 # mini-batch大小self.pad_size = 32 # 每句话处理成的长度(短填长切)self.learning_rate = 1e-3 # 学习率self.embed = 300 # 字向量维度self.filter_sizes = (2, 3, 4) # 卷积核尺寸self.num_filters = 256 # 卷积核数量(channels数)self.dropout = 0.5 # 随机失活self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练self.num_classes = len(self.class_list) # 类别数self.n_vocab = 0 # 词表大小,在运行时赋值self.num_epochs = 10 # epoch数self.batch_size = 128 # mini-batch大小self.pad_size = 32 # 每句话处理成的长度(短填长切)self.learning_rate = 1e-3 # 学习率self.embed = 300 # 字向量维度self.hidden_size = 256 # 隐藏层大小'''Bag of Tricks for Efficient Text Classification'''class Model(nn.Module):def __init__(self, config):super(Model,self).__init__()self.embedding = nn.Embedding(config.n_vocab, # 词汇表达的大小config.embed, # 词向量的的维度padding_idx=config.n_vocab-1 # 填充)self.dropout = nn.Dropout(config.dropout)self.fc1 = nn.Linear(config.embed, config.hidden_size)self.dropout = nn.Dropout(config.dropout)self.fc2 = nn.Linear(config.hidden_size, config.num_classes)def forward(self, x):out_word = self.embedding(x[0])out = out_word.mean(dim=1)out = self.dropout(out)out = self.fc1(out)out = F.relu(out)out = self.fc2(out)return out
训练模型
train_eval.py
# coding: UTF-8
import numpy as np
import torch
import torch.nn.functional as F
from sklearn import metrics# 训练
def train(config, model, train_iter, dev_iter):print("begin")model.train()optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)total_batch = 0 # 记录进行到多少batchdev_best_loss = float('inf')last_improve = 0 # 记录上次验证集loss下降的batch数flag = False # 记录是否很久没有效果提升for epoch in range(config.num_epochs):print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))# 批量训练for i, (trains, labels) in enumerate(train_iter):outputs = model(trains)model.zero_grad()loss = F.cross_entropy(outputs, labels)loss.backward()optimizer.step()if total_batch % 100 == 0:# 每多少轮输出在训练集和验证集上的效果true = labels.data.cpu()predict = torch.max(outputs.data, 1)[1].cpu()train_acc = metrics.accuracy_score(true, predict)dev_acc, dev_loss = evaluate(config, model, dev_iter)if dev_loss < dev_best_loss:dev_best_loss = dev_losstorch.save(model.state_dict(), config.save_path)improve = '*'last_improve = total_batchelse:improve = ''msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, ' \' Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}'print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, improve))model.train()total_batch += 1if total_batch - last_improve > config.require_improvement:# 验证集loss超过1000batch没下降,结束训练print("No optimization for a long time, auto-stopping...")flag = Truebreakif flag:break# 评价
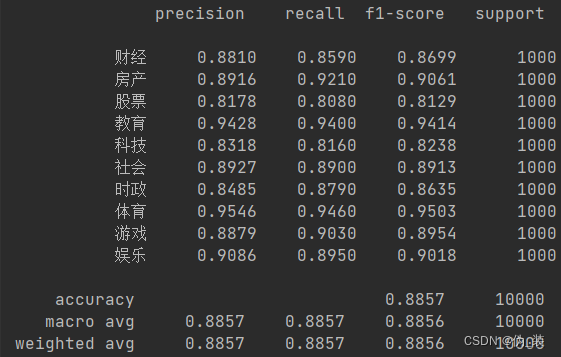
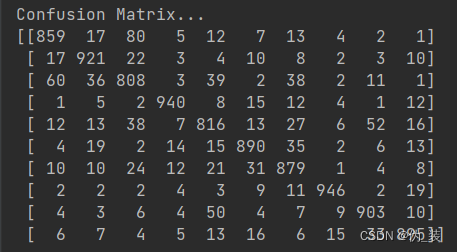
def evaluate(config, model, data_iter, test=False):model.eval()loss_total = 0predict_all = np.array([], dtype=int)labels_all = np.array([], dtype=int)with torch.no_grad():for texts, labels in data_iter:outputs = model(texts)loss = F.cross_entropy(outputs, labels)loss_total += losslabels = labels.data.cpu().numpy()predict = torch.max(outputs.data, 1)[1].cpu().numpy()labels_all = np.append(labels_all, labels)predict_all = np.append(predict_all, predict)acc = metrics.accuracy_score(labels_all, predict_all)if test:report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)confusion = metrics.confusion_matrix(labels_all, predict_all)return acc, loss_total / len(data_iter), report, confusionreturn acc, loss_total / len(data_iter)
预测代码
predict_eval.py
# coding:utf-8
import torch
import numpy as np
from train_eval import evaluateMAX_VOCAB_SIZE = 10000
UNK, PAD = '<UNK>', '<PAD>'tokenizer = lambda x: [y for y in x] # char-leveldef test(config, model, test_iter):# testmodel.load_state_dict(torch.load(config.save_path)) # 加载训练好的的模型model.eval() # 开启评价模式test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'print(msg.format(test_loss, test_acc))print("Precision, Recall and F1-Score...")print(test_report)print("Confusion Matrix...")print(test_confusion)def load_dataset(text, vocab, config, pad_size=32):contents = []for line in text:lin = line.strip()if not lin:continuewords_line = []token = tokenizer(line)seq_len = len(token)if pad_size:if len(token) < pad_size:token.extend([PAD] * (pad_size - len(token)))else:token = token[:pad_size]seq_len = pad_size# word to idfor word in token:words_line.append(vocab.get(word, vocab.get(UNK)))contents.append((words_line, int(0), seq_len))return contents # [([...], 0), ([...], 1), ...]def match_label(pred, config):label_list = config.class_listreturn label_list[pred]def final_predict(config, model, data_iter):map_location = lambda storage, loc: storagemodel.load_state_dict(torch.load(config.save_path, map_location=map_location))model.eval()predict_all = np.array([])with torch.no_grad():for texts, _ in data_iter:outputs = model(texts)pred = torch.max(outputs.data, 1)[1].cpu().numpy()pred_label = [match_label(i, config) for i in pred]predict_all = np.append(predict_all, pred_label)return predict_all
项目运行
run.py
# coding:utf-8from FastText import Config
from FastText import Model
from load_data import build_dataset
from load_data_iter import build_iterator
from train_eval import train
from predict_eval import test,load_dataset,final_predicttext = ['国考28日网上查报名序号查询后务必牢记报名参加2011年国家公务员的考生,如果您已通过资格审查,那么请于10月28日8:00后,登录考录专题网站查询自己的“关键数字”——报名序号。''国家公务员局等部门提醒:报名序号是报考人员报名确认和下载打印准考证等事项的重要依据和关键字,请务必牢记。此外,由于年龄在35周岁以上、40周岁以下的应届毕业硕士研究生和''博士研究生(非在职),不通过网络进行报名,所以,这类人报名须直接与要报考的招录机关联系,通过电话传真或发送电子邮件等方式报名。','高品质低价格东芝L315双核本3999元作者:徐彬【北京行情】2月20日东芝SatelliteL300(参数图片文章评论)采用14.1英寸WXGA宽屏幕设计,配备了IntelPentiumDual-CoreT2390''双核处理器(1.86GHz主频/1MB二级缓存/533MHz前端总线)、IntelGM965芯片组、1GBDDR2内存、120GB硬盘、DVD刻录光驱和IntelGMAX3100集成显卡。目前,它的经销商报价为3999元。','国安少帅曾两度出山救危局他已托起京师一代才俊新浪体育讯随着联赛中的连续不胜,卫冕冠军北京国安的队员心里到了崩溃的边缘,俱乐部董事会连夜开会做出了更换主教练洪元硕的决定。''而接替洪元硕的,正是上赛季在李章洙下课风波中同样下课的国安俱乐部副总魏克兴。生于1963年的魏克兴球员时代并没有特别辉煌的履历,但也绝对称得上特别:15岁在北京青年队获青年''联赛最佳射手,22岁进入国家队,著名的5-19一战中,他是国家队的替补队员。','汤盈盈撞人心情未平复眼泛泪光拒谈悔意(附图)新浪娱乐讯汤盈盈日前醉驾撞车伤人被捕,','甲醇期货今日挂牌上市继上半年焦炭、铅期货上市后,酝酿已久的甲醇期货将在今日正式挂牌交易。基准价均为3050元/吨继上半年焦炭、铅期货上市后,酝酿已久的甲醇期货将在今日正式''挂牌交易。郑州商品交易所(郑商所)昨日公布首批甲醇期货8合约的上市挂牌基准价,均为3050元/吨。据此推算,买卖一手甲醇合约至少需要12200元。业内人士认为,作为国际市场上的''首个甲醇期货品种,其今日挂牌后可能会因炒新资金追捧而出现冲高走势,脉冲式行情过后可能有所回落,不过,投资者在上市初期应关注期现价差异常带来的无风险套利交易机会。','佟丽娅穿白色羽毛长裙美翻,自曝跳舞的女孩能吃苦','江欣燕透露汤盈盈钱嘉乐分手 用冷笑话补救']if __name__ == "__main__":config = Config()print("Loading data...")vocab, train_data, dev_data, test_data = build_dataset(config, False)# 1. 批量加载测试数据train_iter = build_iterator(train_data, config, False)dev_iter = build_iterator(dev_data, config, False)test_iter = build_iterator(test_data,config, False)config.n_vocab = len(vocab)# 2. 加载模型结构model = Model(config).to(config.device)train(config, model, train_iter, dev_iter)# 3. 测试test(config, model, test_iter)print("+++++++++++++++++")# 4. 预测content = load_dataset(text, vocab, config)predict_iter = build_iterator(content, config, predict=True)result = final_predict(config, model, predict_iter)for i, j in enumerate(result):print('text:{}'.format(text[i]), '\t', 'label:{}'.format(j))