高通Camera HAL3: CamX、Chi-CDK要点
目录
一、概述
二、目录
三、CamX组件之前的关系
一、概述
高通CamX架构是高通实现的相机HAL3架构,被各OEM厂商广泛采用。
二、目录
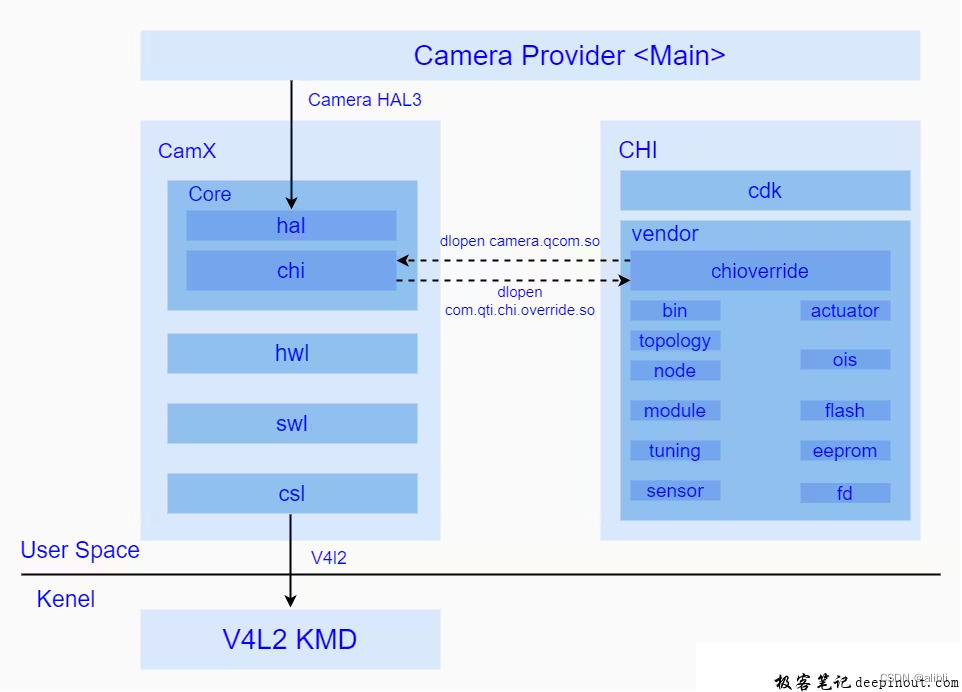
代码位于vendor/qcom/proprietary下:
- camx:通用功能性接口的代码实现集合
- chi-cdk:可定制化的代码实现集合
CamX子目录:
- core/: 用于存放camx的核心实现模块,其中还包含了主要用于实现hal3接口的hal/目录,以及负责与CHI进行交互的chi/目录
- hwl/: 用于存放自身具有独立运算能力的硬件node,该部分node受csl管理
- swl/: 用于存放自身并不具有独立运算能力,必须依靠CPU才能实现的软件node
- csl/:用于存放主要负责camx与camera driver的通讯模块,为camx提供了统一的Camera driver控制接口
Chi-Cdk子目录:
- chioverride/: 用于存放CHI实现的核心模块,负责与camx进行交互并且实现了CHI的总体框架以及具体的业务处理。
- bin/: 用于存放平台相关的配置项
- topology/: 用于存放用户自定的Usecase xml配置文件
- node/: 用于存放用户自定义功能的node
- module/: 用于存放不同sensor的配置文件,该部分在初始化sensor的时候需要用到
- tuning/: 用于存放不同场景下的效果参数的配置文件
- sensor/: 用于存放不同sensor的私有信息以及寄存器配置参数
- actuator/: 用于存放不同对焦模块的配置信息
- ois/: 用于存放防抖模块的配置信息
- flash/: 存放着闪光灯模块的配置信息
- eeprom/: 存放着eeprom外部存储模块的配置信息
- fd/: 存放了人脸识别模块的配置信息
三、CamX组件之前的关系
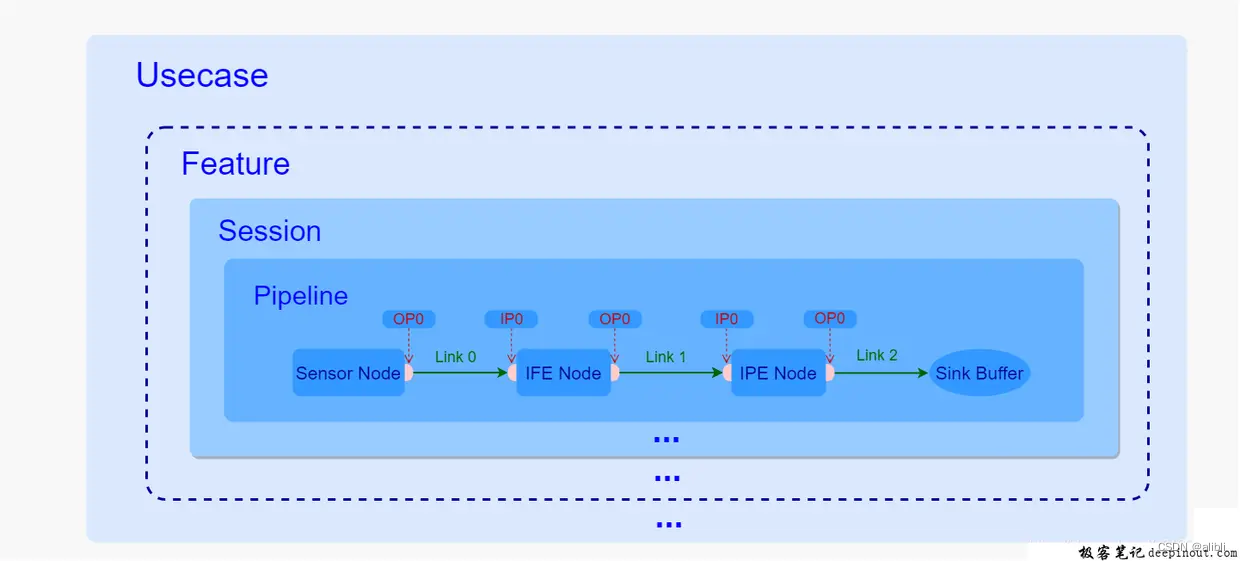
Usecase:一个Usecase代表了某个特定的图像采集场景,比如人像场景,后置拍照场景等等,在初始化的时候通过根据上层传入的一些具体信息来进行创建,这个过程中,一方面实例化了特定的Usecase,这个实例是用来管理整个场景的所有资源,同时也负责了其中的业务处理逻辑,另一方面,获取了定义在XML中的特定Usecase,获取了用于实现某些特定功能的pipeline。
Feature:在Usecase中,Feature是一个可选项,如果当前用户选择了HDR模式或者需要在Zoom下进行拍照等特殊功能的话,在Usecase创建过程中,便会根据需要创建一个或者多个Feature,一般一个Feature对应着一个特定的功能,如果场景中并不需要任何特定的功能,则也完全可以不使用也不创建任何Feature。
Session:每一个Usecase或者Feature都可以包含一个或者多个Session,每一个Session都是直接管理并负责了内部的Pipeline的数据流转,其中每一次的Request都是Usecase或者Featuret通过Session下发到内部的Pipeline进行处理,数据处理完成之后也是通过Session的方法将结果给到CHI中,之后是直接给到上层还是将数据封装下再次下发到另一个Session中进行后处理,这都交由CHI来决定。
Pipeline:Session和Pipeline是一对多的关系,通常一个Session只包含了一条Pipeline,用于某个特定图像处理功能的实现,但是也不绝对,比如FeatureMFNR中包含的Session就包括了三条pipeline,又比如后置人像预览,也是用一个Session包含了两条分别用于主副双摄预览的Pipeline,主要是要看当前功能需要的pipeline数量以及它们之间是否存在一定关联。
Node:根据上面关于Pipeline的定义,它内部包含了一定数量的Node,并且实现的功能越复杂,所包含的Node也就越多,同时Node之间的连接也就越错综复杂,比如后置人像预览虚化效果的实现就是将拿到的主副双摄的图像通过RTBOfflinePreview这一条Pipeline将两帧图像合成一帧具有虚化效果的图像,从而完成了虚化功能。
最后Pipeline中的Node的连接方式是通过XML文件中的Link来进行描述的,每一个Link定义了一个输入端和输出端分别对应着不同Node上面的输入输出端口,通过这种方式就将其中的一个Node的输出端与另外一个Node的输入端,一个一个串联起来,等到图像数据从Pipeline的起始端开始输入的时候,便可以按照这种定义好的轨迹在一个一个Node之间进行流转,而在流转的过程中每经过一个Node都会在内部对数据进行处理,这样等到数据从起始端一直流转到最后一个Node的输出端的时候,数据就经过了很多次处理,这些处理效果最后叠加在一起便是该Pipeline所要实现的功能,比如降噪、虚化等等。
参考优秀博客:
深入理解Android相机体系结构_深入理解android 相机-CSDN博客