基于VM虚拟机下Ubuntu18.04系统,Hadoop的安装与详细配置
参考博客:
https://blog.csdn.net/duchenlong/article/details/114597944
与上面这个博客几乎差不多,就是java环境配置以及后面的hadoop的hdfs-site.xml文件有一些不同的地方。
准备工作
1.更新
# 更新
sudo apt update
sudo apt upgrade
2.关闭防火墙( 不用单独开辟端口)
sudo ufw disable
创建Hadoop用户
# 创建Hadoop用户,并使用/bin/bash作为shell
sudo useradd -m hadoop -s /bin/bash# 为Hadoop设置登录密码
sudo passwd hadoop# 增加管理员权限
sudo adduser hadoop sudo
创建一个Hadoop用户,是因为可以避免Hadoop在运行的过程中影响到其他用户的正常使用。
增加管理员权限可以避免Hadoop在运行时,出现一些权限的问题,比如在一些目录下创建文件等。
如何后续的安装在hadoop用户下进行
# 切换为 Hadoop用户
su hadoop
或者退出当前用户:
方法一:使用快捷键Ctrl+D组合键
方法二:在终端中输入$exit或者$logout命令,然后按下回车键就可退出当前用户会话
安装Java
如果安装的Hadoop是2.*版本的,那么需要安装的java版本最好是1.8,默认安装的是11,在配置伪分布式节点时会报一些警告
sudo apt install openjdk-8-jdk
配置环境变量( Ctrl + s 保存,Ctrl + x 退出)
nano ~/.bashrc
在结尾添加
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH然后更新环境变量
# 更新环境变量
source ~/.bashrc
查看是否安装成功,以及java的版本信息
# 查看是否安装成功
whereis java# java的版本信息
java-version# 环境变量是否导入成功
echo $JAVA_HOME

设置ssh免密登录
# 登录localhost
ssh localhost
(忘记直接截图在哪了,放上面博客博主的图吧,操作一样)

然后会在~/目录下发现一个.ssh文件。

配置秘钥,免密登录
# 到.ssh 目录下
cd ~/.sshssh-keygen -t rsa

# 加入授权
cat ./id_rsa.pub >> ./authorized_keys
再次输入$ssh localhost不需要密码的话,就是配置成功了

Hadoop下载安装
安装地址:https://blog.csdn.net/m0_62110645/article/details/134403165?spm=1001.2014.3001.5502
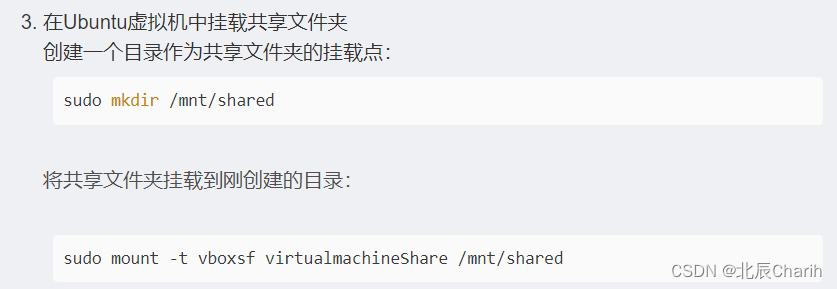
我是使用共享文件夹安装的:
在在virtualbox的ubuntu虚拟机上设置共享文件夹步骤:
1.设置共享文件夹
自行设定共享文件夹路径以及名称,记得勾选自动挂载(A),运行虚拟机的时候才会自动加载该文件夹。





# 将hadoop 压缩包在/usr/local 目录下解压
sudo tar -zxvf hadoop-2.10.1.tar.gz -C /usr/local/# 进入该目录
cd /usr/local# 更新名字文hadoop
sudo mv ./hadoop-2.10.1/ ./hadoop# 修改文件权限
sudo chown -R hadoop ./hadoop
配置java环境变量在hadoop中
# 进入配置文件目录
cd /usr/local/hadoop/etc/hadoop# 打开文件
nano hadoop-env.sh

查看hadoop版本信息
# 进入bin目录
cd /usr/local/hadoop/bin./hadoop version



伪分布式安装
# 进入配置文件的目录
cd /usr/local/hadoop/etc/hadoop
需要修改的两个文件core-site.xml和hdfs-site.xml文件
修改core-site.xml文件为:
nano core-site.xml
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>
修改hdfs-site.xml文件为:
nano hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property><property><name>dfs.http.address</name><value>localhost:50070</value></property>
</configuration>这里我直接是localhost:50070,在自己主机上访问。因为我按教程来,但是得不到一样的结果,就启动不出教程192.168.*的界面。后来经过四处搜索方法。在终端输入$ifconfig,显示我的是10.0.2.15 。
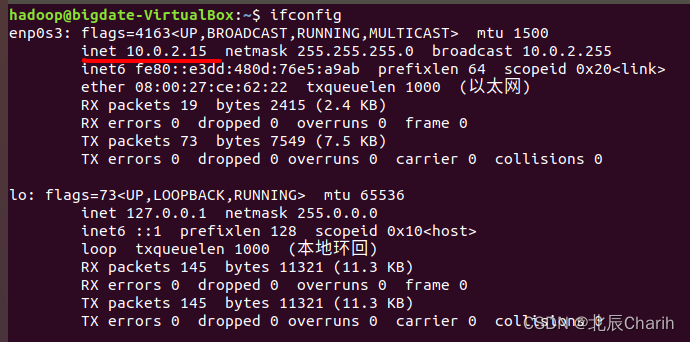
尝试过什么修改为桥接网络等等各种方法,但始终不成功,所以我干脆修改为只在自己主机运行。