机器学习8:在病马数据集上进行算法比较(ROC曲线与AUC)
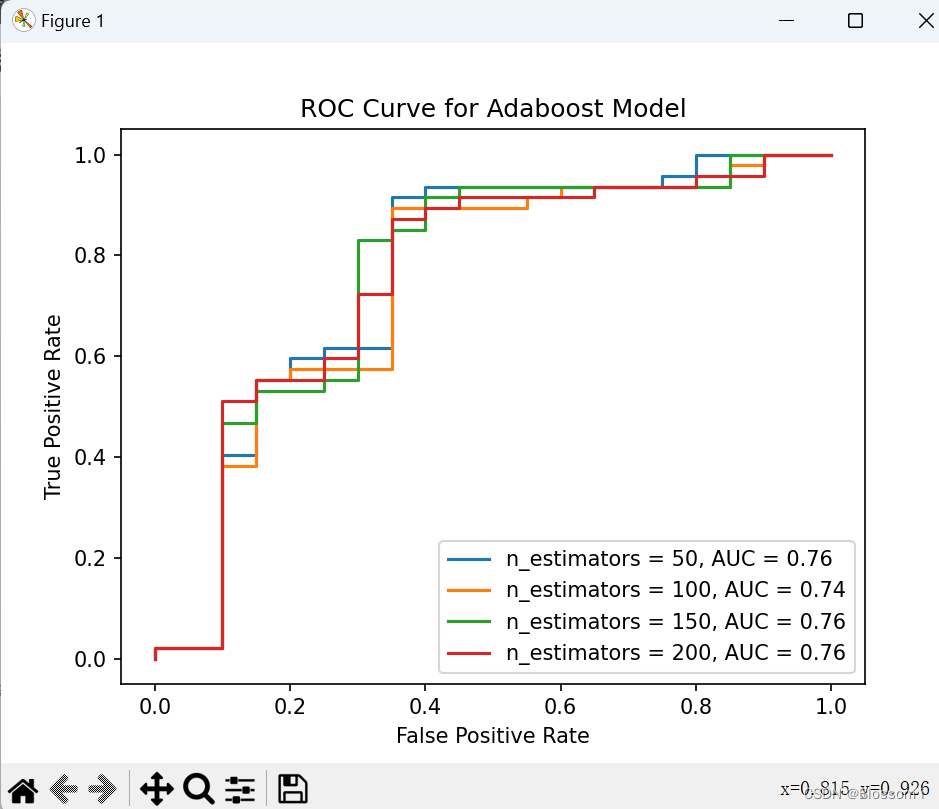
ROC曲线与AUC。使用不同的迭代次数(基模型数量)进行 Adaboost 模型训练,并记录每个模型的真阳性率和假阳性率,并绘制每个模型对应的 ROC 曲线,比较模型性能,输出 AUC 值最高的模型的迭代次数和 ROC 曲线。
使用Python的scikit-learn库来训练Adaboost模型,并记录每个模型的真阳性率和假阳性率,并绘制每个模型对应的ROC曲线。然后比较模型性能,并输出AUC值最高的模型的迭代次数和ROC曲线。
下面是一个示例代码,用于在病马数据集上进行Adaboost模型的训练、绘制ROC曲线和计算AUC值:
如果你的是csv文件
import numpy as np
import pandas as pd
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt# 加载数据集,这里假设数据已经存储在名为data的DataFrame中
# 请根据实际情况修改加载数据集的代码
data = pd.read_csv('your_dataset.csv')# 假设数据集中最后一列为标签,其余列为特征
X = data.iloc[:, :-1]
y = data.iloc[:, -1]# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化基模型数量列表和对应的AUC值列表
n_estimators_list = [50, 100, 150, 200]
auc_list = []# 训练Adaboost模型,并计算每个模型的AUC值
for n_estimators in n_estimators_list:ada_model = AdaBoostClassifier(n_estimators=n_estimators, random_state=42)ada_model.fit(X_train, y_train)y_score = ada_model.decision_function(X_test)fpr, tpr, thresholds = roc_curve(y_test, y_score)roc_auc = auc(fpr, tpr)auc_list.append(roc_auc)# 绘制ROC曲线plt.plot(fpr, tpr, label='n_estimators = %d, AUC = %0.2f' % (n_estimators, roc_auc))# 找到AUC值最高的模型的迭代次数
best_n_estimators = n_estimators_list[np.argmax(auc_list)]# 设置图形参数
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve for Adaboost Model')
plt.legend(loc='lower right')
plt.show()# 输出AUC值最高的模型的迭代次数和ROC曲线
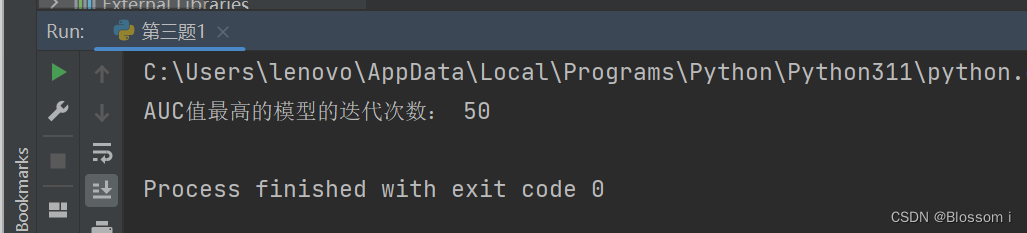
print("AUC值最高的模型的迭代次数:", best_n_estimators)
在病马数据集上进行算法比较(ROC曲线与AUC)
- 使用不同的迭代次数(基模型数量)进行 Adaboost 模型训练,并记录每个模型的真阳性率和假阳性率,并绘制每个模型对应的 ROC 曲线,比较模型性能,输出 AUC 值最高的模型的迭代次数和 ROC 曲线。
- 计算不同基模型数量下的AUC值,画出“分类器个数-AUC”关系图
- 讨论:随着弱分类器个数的增加,AUC的值会如何变化?为什么?如果AUC值随着弱分类器的增加而增加,是否表示弱分类器个数越多越好呢?
- 我们能否根据AUC的曲线图找到最优的弱分类器个数?怎么找?
数据集是horseColicTest.txt和horseColicTraining.txt,不是csv文件
使用不同的迭代次数(基模型数量)进行 Adaboost 模型训练,并记录每个模型的真阳性率和假阳性率,并绘制每个模型对应的 ROC 曲线,比较模型性能,输出 AUC 值最高的模型的迭代次数和 ROC 曲线。
import numpy as np
import pandas as pd
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt# 加载训练集和测试集
train_data = pd.read_csv('horseColicTraining.txt', delimiter='\t', header=None)
test_data = pd.read_csv('horseColicTest.txt', delimiter='\t', header=None)# 假设数据集中最后一列为标签,其余列为特征
X_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
X_test = test_data.iloc[:, :-1]
y_test = test_data.iloc[:, -1]# 初始化基模型数量列表和对应的AUC值列表
n_estimators_list = [50, 100, 150, 200]
auc_list = []# 训练Adaboost模型,并计算每个模型的AUC值
for n_estimators in n_estimators_list:ada_model = AdaBoostClassifier(n_estimators=n_estimators, random_state=42)ada_model.fit(X_train, y_train)y_score = ada_model.decision_function(X_test)fpr, tpr, thresholds = roc_curve(y_test, y_score)roc_auc = auc(fpr, tpr)auc_list.append(roc_auc)# 绘制ROC曲线plt.plot(fpr, tpr, label='n_estimators = %d, AUC = %0.2f' % (n_estimators, roc_auc))# 找到AUC值最高的模型的迭代次数
best_n_estimators = n_estimators_list[np.argmax(auc_list)]# 设置图形参数
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve for Adaboost Model')
plt.legend(loc='lower right')
plt.show()# 输出AUC值最高的模型的迭代次数和ROC曲线
print("AUC值最高的模型的迭代次数:", best_n_estimators)