GaussDB新特性Ustore存储引擎介绍

1、 Ustore和Astore存储引擎介绍
Ustore存储引擎,又名In-place Update存储引擎(原地更新),是openGauss 内核新增的一种存储模式。此前的版本使用的行存储引擎是Append Update(追加更新)模式。相比于Append Update(追加更新)行存储引擎,Ustore存储引擎可以提高数据页面内更新的HOT UPDATE的垃圾回收效率,有效降低多次更新元组后存储空间占用的问题。Append Update和 In-place Update是两种不同的存储引擎策略,适用场景有所不同。
Append Update:Append Update 存储引擎策略将更新操作视为一种追加操作,即将新的数据追加到已有的数据之后。这种方式适合于写操作频率较高、更新操作较少的场景。在 Append Update 中,旧数据不直接被修改或删除,而是继续存储,新数据将追加到数据集的末尾。这样可以避免数据的移动和重建,提高写入的性能,并且可以实现快速的回滚和历史数据的查询。
In-place Update:In-place Update 存储引擎策略将更新操作视为一种就地修改操作,即直接在原有位置上进行数据的更新。这种方式适用于需要频繁更新和随机访问的场景。在 In-place Update 中,数据库系统会在原有位置上修改被更新的数据,而不是追加新的数据。这可以减少存储空间的占用,并且支持更高的并发性能。然而,In-place Update 可能涉及到数据的移动和重建,特别是在更新操作导致数据大小变化时,可能需要重新分配和调整存储空间。
2、 Ustore存储引擎优势
相比于Append Update(追加更新)行存储引擎,Ustore存储引擎可以提高数据页面内更新的HOT UPDATE的垃圾回收效率,有效降低多次更新元组后存储空间占用的问题。
Ustore存储引擎结合Undo空间,可以实现更高效、更全面的闪回查询和回收站机制,能快速回退人为“误操作”,为GaussDB Kernel提供了更丰富的闪回功能。
Undo技术相对成熟,Ustore基于Undo回滚段技术、页面并行回放技术、多版本索引技术等实现了Ustore作为一款高可用高可靠的行存储引擎。
闪回作为数据库恢复技术的一环,能够使得DBA有选择性的高效撤销一个已提交事务的影响,将数据从人为的不正确的操作中进行恢复。在采用闪回技术之前,只能通过备份恢复、PITR等手段找回已提交的数据库修改,恢复时长需要数小时甚至数天。采用闪回技术后,恢复已提交的数据库修改前的数据,只需要秒级,而且恢复时间和数据库大小无关。Ustore支持闪回表、闪回查询、闪回TRUNCATE、闪回DROP,而且适用于分区表。
Ubtree与有的Btree索引相比,索引页面增加了事务信息,使得UBtree索引具备MVCC能力以及独立过期旧版本回收能力。In-place Update引擎支持 UBtree索引,UBtree也是In-place Update引擎的默认索引类型。支持并行创建索引、索引空间管理算法优化,索引空间进一步压缩。
Ustore整体架构图:
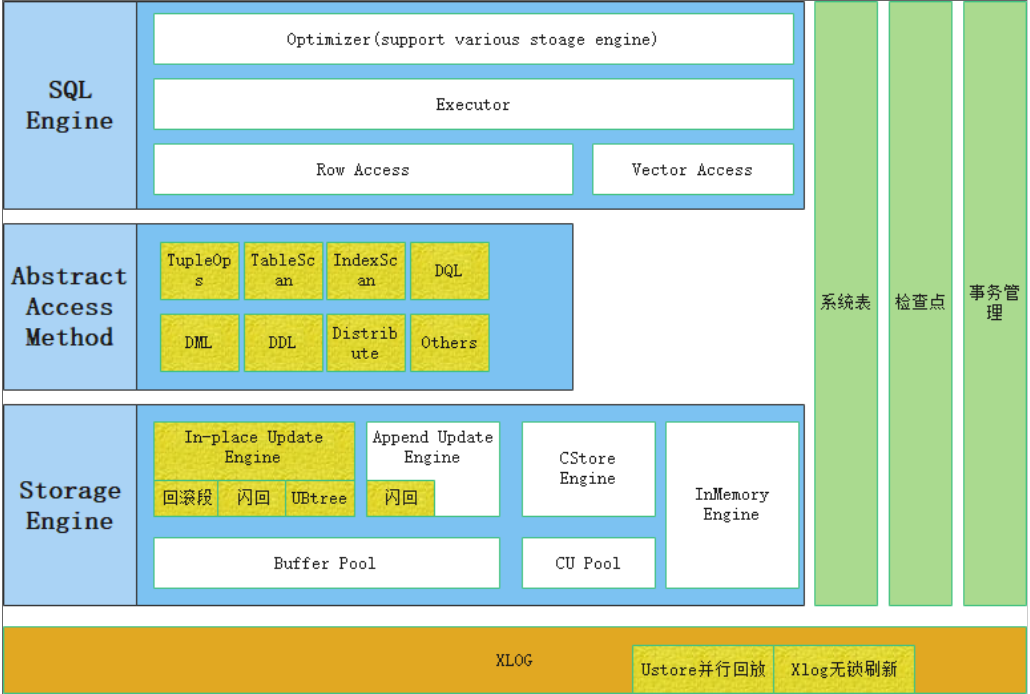
3、 Ustore存储引擎实践
USTORE与原有的ASTORE(Append Update)存储引擎并存。USTORE存储引擎屏蔽了存储层实现的细节,SQL语法和原有的ASTORE存储引擎使用基本保持一致,唯一差别是建表和建索引有些细微区别。同时和Astore相比,Ustore没有VM文件。
在postgresql.conf配置文件中添加如下选项并重启数据库:
track_counts=on
track_activities=on
enable_ustore=on
enable_default_ustore_table=on
创建Ustore表:
create table city(id int, name varchar(120) ,code varchar(20)) with (storage_type=ustore);
确认city表使用ustore存储引擎:
openGauss=# \d
List of relations
Schema | Name | Type | Owner | Storage
--------+------+-------+-------+------------------------------------------------------
public | city | table | omm | {orientation=row,storage_type=ustore,compression=no}
4、 Ustore使用场景
-
高性能:对插入、更新、删除等不同负载的业务,性能以及资源使用表现相对均衡。更新操作采用原地更新模式,在频繁更新类的业务场景下可拥有更高、更平稳的性能表现。适应“短”(事务短)、“频”(更新操作频繁)、“快”(性能要求高)的典型OLTP类业务场景。
-
高效存储:支持最大限度的原位更新, 极大节约了空间;将回滚段、数据页面分离存储,具备更高效、平稳的IO使用能力,Undo子系统采用NUMA-aware设计,具有更好的多核扩展性,Undo空间统一分配,集中回收,复用效率更高,存储空间使用更加高效、平稳。
-
细粒度资源控制:Ustore引擎提供多维度的事务“监管”方式,可基于事务运行时长、单事务使用Undo空间大小、以及整体Undo空间限制等方式对事务运行进行“监管”,防止异常、非预期内的行为出现,方便数据库管理员对数据库系统资源使用进行规范和约束。
5、 Ustore使用约束
尽管Ustore设计几乎能够覆盖SQL和未来特性集;支持大多数的SQL标准,也支持常见的数据库特性。但也存在如下约束:
1)不支持可重复读和串行化隔离级别。
2)对于支持row movement的分区表,不支持并发更新或删除同一行操作。
3)不支持的DDL功能:在线vacuum full/cluster、在线alter table(除新增字段、重命名等无需全量重写数据的操作外)、table sampling、并行查询。
4)不支持hash索引、GiST索引、SP-GiST索引、BRIN索引。
5)不支持压缩。
6)不支持批量访存接口。不支持rowid语义。
7)不支持创建、使用物化视图。
8)不支持设置透明数据加密。
9)不支持单事务块或语句中既包含Astore表又包含Ustore表。
6、 展望未来
Ustore和Astore都有各自的使用场景,在使用时需要根据具体的业务场景进行选择,因此GaussDB把选择权交给了用户。那么Ustore和Astore是否可以融合互补所长,在存储引擎层做彻底的融合优化呢?让我们拭目以待。