CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
【导师不教?我来教!】同济计算机博士半小时就教会了我五大深度神经网络,CNN/RNN/GAN/transformer/LSTM一次学会,简直不要太强!_哔哩哔哩_bilibili了解的五大神经网络,整理笔记如下:
视频是唐宇迪博士讲解的,但是这个up主发的有一种东拼西凑的感觉,给人感觉不是很完整
一、卷积神经网络(优势:计算机视觉)
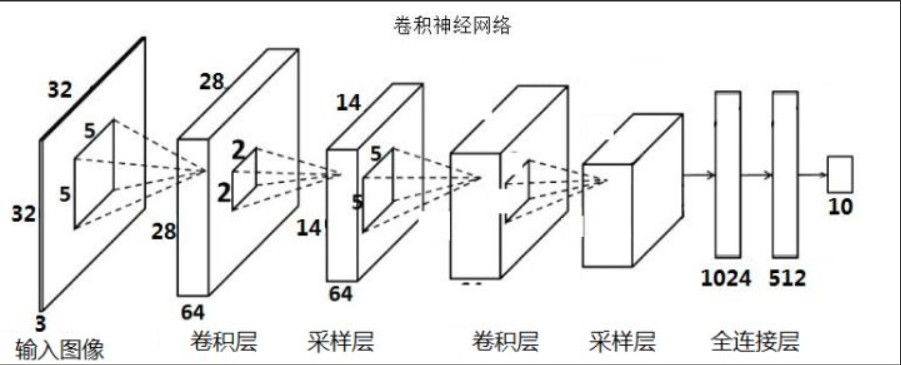
1、卷积的作用:特征提取,本质就是提取卷积核那个大小区域中的特征值
2、利用不同的卷积核对同一数据进行提取,可以得到多维度的特征图,丰富特征内容
3、边缘填充(padding)可以解决边缘特征在提取时权重不高的问题
4、卷积的结果公式:

其中size'是下一次特征图长或宽,size是这一次特征图的长或宽,kernelsize是卷积核大小,padding留白行数,step为卷积步长
5、为了减少计算量,在一轮卷积中,卷积核的参数是共享的,不会随着位置改变而改变
6、池化层的作用:特征降维
7、通常说几层神经网络的时候,只有带权值与参数的层会被计入,如卷积层与线性层,如池化层这种不带权值与参数的层不会被计入
8、经典的CNN网络模型:AlexNet、VGG、ResNet(利用残差相加提供了增加网络深度的方法)
9、感受野:特征图中特征所代表的原图中区域的大小
10、具有相同的感受野的多个小卷积核组合与一个大卷积核相比,所需要的参数少,特征提取更细致,加入的非线性变换也更多,所以现在基本上都使用小卷积核来进行卷积
二、循环神经网络(RNN)(优势:时间序列问题处理,多用于NLP)

1、输入数据为特征向量,并且按照时间顺序排列
2、RNN网络缺点是会记忆之前所有的数据,LSTM模型通过加入遗忘门解决了这个问题
3、示例:Word2Vec 文本向量化:创建一个多维的文本空间,一个向量就代表一个词,词义越相近的词在文本空间中的距离也就越近
4、Word2Vec模型中,反向传播的过程中,不仅会更新神经网络,还会更新输入的词向量
5、RNN经典模型:CBOW,skipgram
6、由于数据量大,模型构建方案一般不使用输入一词输出预测词的模式,而是使用输入前一词A和后一词B,输出B在A后的概率,但是由于数据集均为通顺语句采集而来,概率均为1,所以需要人为在数据集中加入错误语句,并且标记概率为0,被称为负采样
三、对抗生成网络(GNN)
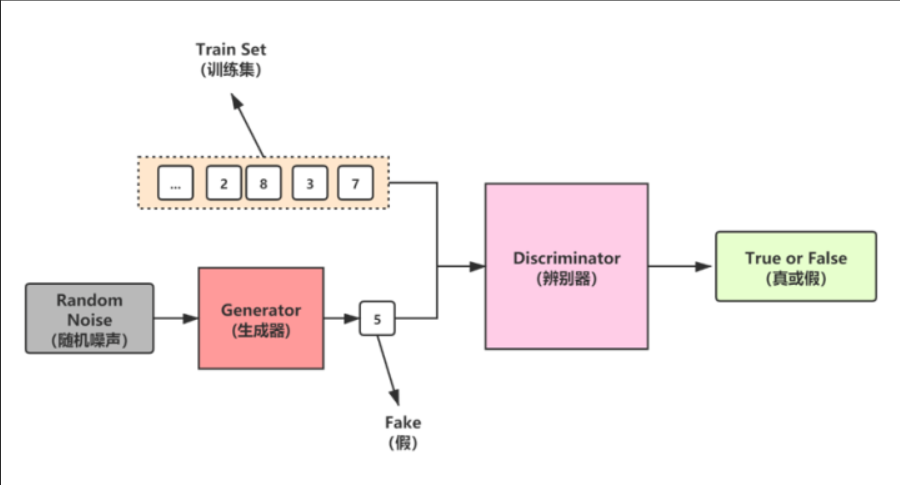
1、对抗生成网络分为生成器、判别器、损失函数,其中生成器负责利用噪声生成数据,产生以假乱真的效果,判别器需要火眼金睛,分辨真实数据与虚假数据,损失函数负责让生成器更加真实,让判别器更加强大。
四、Teansformer(功能强大,但是需要很大数据来训练)
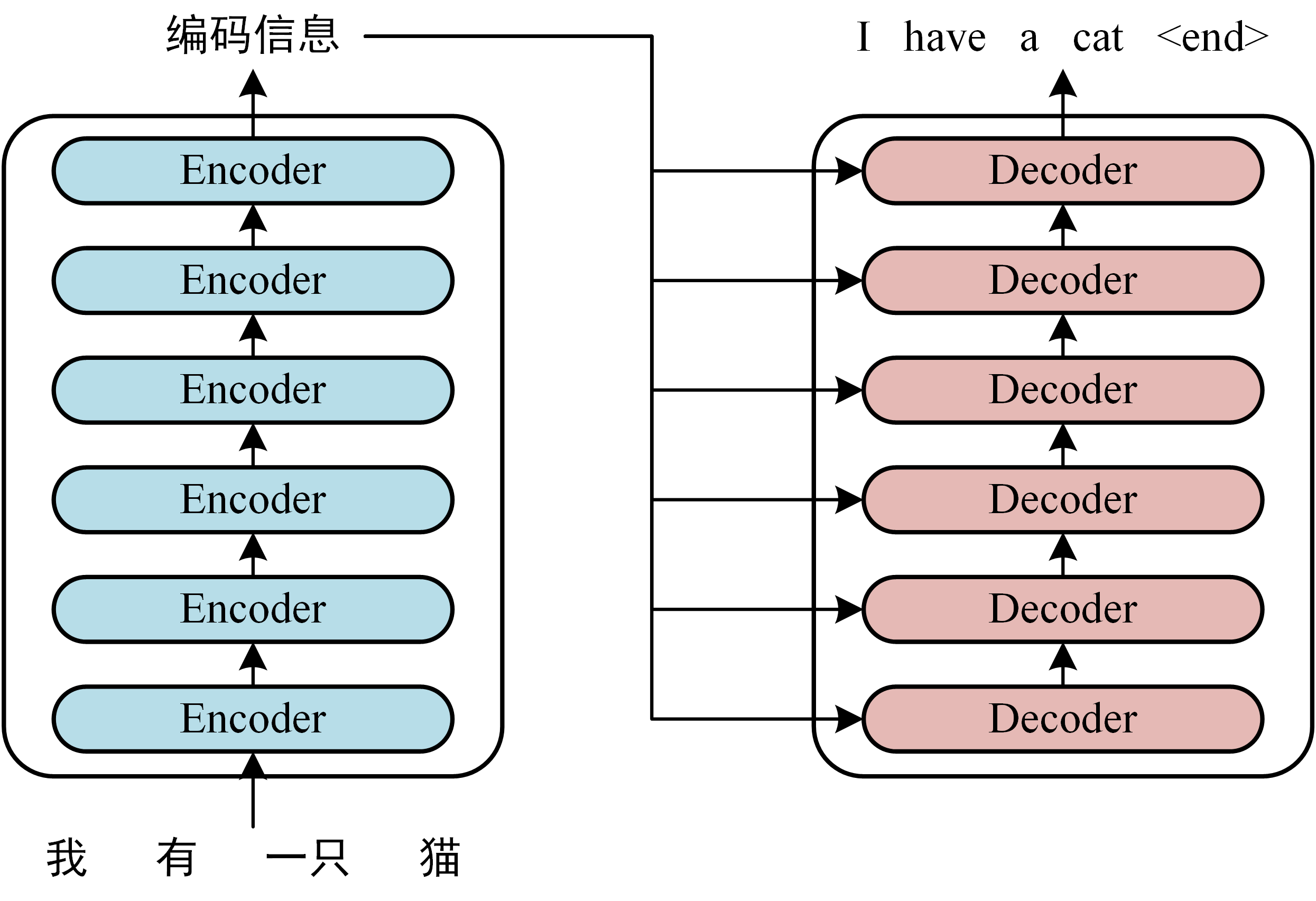
1、Transformer由编码器(Encoder)和解码器(Decoder)组成
2、Transfromer的本质就是重组输入的向量,以得到更加完美的特征向量
3、Transfromer的工作流程:
3.1、获取输入句子的每一个单词表示向量X(由单词特征加上位置特征得到)
3.2、将得到的单词表示向量矩阵X传入Encoder中,输出编码矩阵C,C与输入的单词矩阵X维度完全一致
3.3、将矩阵C传递到Decoder中,Decoder依次根据当前翻译过的单词预测下一个单词。
4、Transformer的内部结构如下图所示
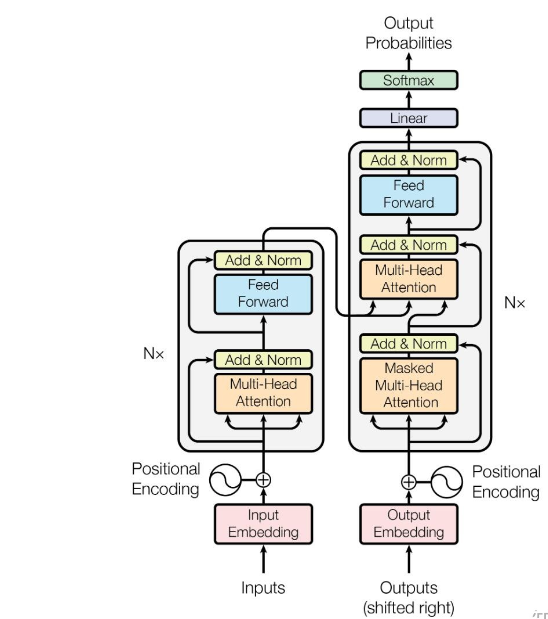
5、在训练时,Decoder中的第一个Multi-Head Attention采用mask模式,即在预测到第i+1个单词时候,需要掩盖i+1之后的单词。
6、单词的特征获取方法有很多种,比如Word2Vec,Glov算法预训练,或者也可以使用Transformer训练得到,位置特征则可以通过公式得到,公式如下:

7、Add是残差链接操作,Norm是LayerNormalization归一化操作,Feed Forward层是两个全连接层,第一个全连接层使用ReLU进行非线性激活,第二个不激活
8、Transformer内部结构存在多个Multi-Head Attention结构,这个结构是由多个Attention组成的多头注意力机制,Attention 注意力机制为Transformer的重点,它可以使模型更加关注那些比较好的特征,忽略差一些的特征
9、Attention内部结构如下图所示
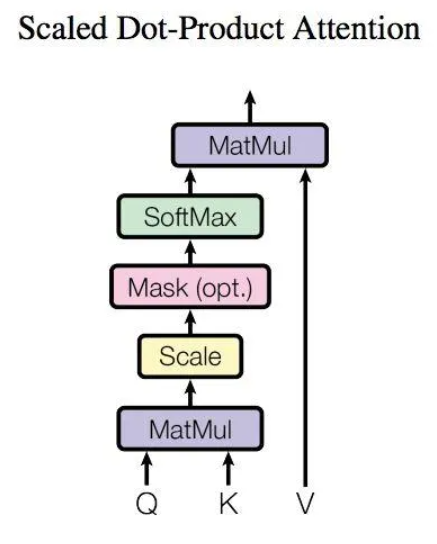
10、Attention接收的输入为单词特征矩阵X或者上一个Encoder block的输入,经过三个矩阵WQ、WK、WV的变换得到了三个输入Q、K、V然后经过内部计算得到输出Z
11、Attention内部计算的公式可以概况为

12、Multi-Head Attention将多个Attention的输出拼接在一起传入一个线性层,得到最终的输出Z
13、Transformer与RNN相比,不能利用单词顺序特征,所以需要在输入加入位置特征,经过实验,加入位置特征比不加位置特征的效果好三个百分点,位置特征的编码方式不对模型产生影响。
14、VIT是Transfromer在CV领域的应用,VIT第一层的感受野就可以覆盖整张图
15、VIT的结构如下:
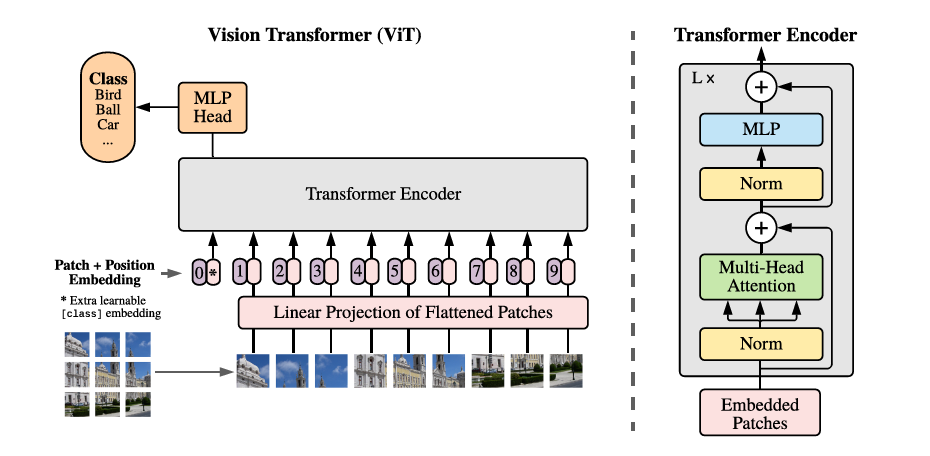
16、VIT将图片分为多个patch(16*16)然后将patch投影为多个固定长度的向量送入Transformer,利用Transformer的Encoder进行编码,并且在输入序列的0位置加入一个特殊的token,token对应的输出就可以代表图片的类别
17、Transformer需要大量的数据,比CNN多得多,需要谷歌那个级别的数据量
18、TNT模型:VIT将图片分为了16*16的多个patch,TNT认为每个patch还是太大了,可以继续进行分割
19、TNT模型方法:在VIT基础上,将拆分后的patch当作一张图像进行transformer进一步分割,划分为新的向量,通过全连接改变输出特征大小,使其重组后的特征与patch编码大小相同,最后与元素输入patch向量进行相加
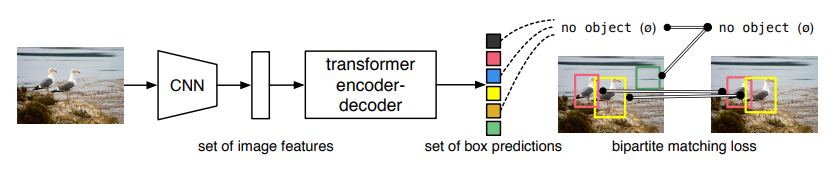
20、DETR模型,用于目标检测,结构如下
五、LSTM长短期记忆
这部分基本是代码解析了,就没有记录,我认为LSTM其实就是RNN的一个分支。