汽车虚拟仿真视频数据理解--CLIP模型原理
CLIP模型原理
CLIP的全称是Contrastive Language-Image Pre-Training,中文是对比语言-图像预训练,是一个预训练模型,简称为CLIP。该模型是 OpenAI 在 2021 年发布的,最初用于匹配图像和文本的预训练神经网络模型,这个任务在多模态领域比较常见,可以用于文本图像检索,CLIP是近年来在多模态研究领域的经典之作。该模型大量的成对互联网数据进行预训练,在很多任务表现上达到了目前最佳表现(SOTA)
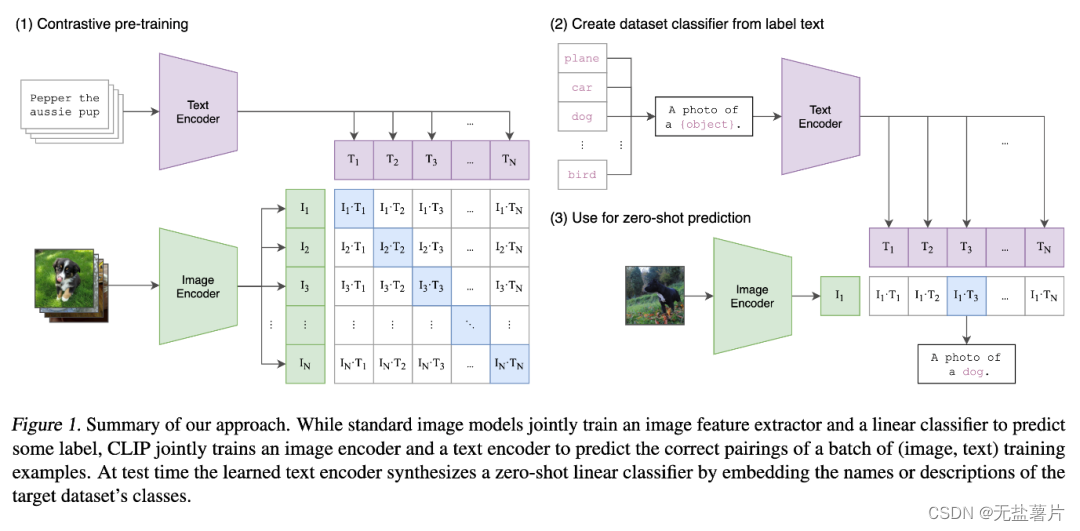
CLIP一共有两个模态,一个是文本模态,一个是视觉模态,分别对应了Text Encoder和Image Encoder。
CLIP模型能够实现文本和图像之间的跨模态学习,这意味着它可以理解和关联文本和图像这两种不同的数据类型。通过对文本和图像进行联合学习,CLIP可以更好地理解和生成符合文本描述的图像。由于CLIP模型在预训练阶段已经学习了大量的文本和图像知识,因此它可以在没有见过的新类别上实现零样本学习。这意味着CLIP模型可以处理那些在训练时没有见过的新的文本和图像,具有很强的适应能力。
原文可见