PostgreSQL技术大讲堂 - 第34讲:调优工具pgBagder部署

PostgreSQL从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对PG基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱PG、学习PG的同学们有帮助,欢迎持续关注CUUG PG技术大讲堂。
第34讲:调优工具pgBagder部署
第34讲:11月18日(周六)19:30-20:30,往期文档及视频,联系CUUG
内容1 : 日志分析器pgBadger简介
内容2 : pgBadger部署
内容3 : 如何产生类似于AWR报告
内容4 : 基于:一小时、一天、一周、一月的报告
内容5 : 如何分析pgBadger
第34讲:调优工具pgBagder部署
pgBadger简介
pgBadger是一个PostgreSQL日志分析器,它是为提高速度而构建的,具有来自PostgreSQL日志文件的完整报告。它是一个小型的Perl脚本,性能优于任何其他PostgreSQL日志分析器。
pgBadger可以自动检测日志文件格式(syslog、stderr、csvlog或jsonlog)。它被设计用来解析巨大的日志文件和压缩文件。支持的压缩格式有gzip、bzip2、lz4、xz、zip和zstd。
还可以使用命令行选项将pgBadger限制为仅报告错误或删除报告的任何部分。
pgBadger支持在postgresql.conf文件中通过log_line_prefix 自定义的任何格式,只要它至少指定%t和%p模式。
pgBadger允许通过使用指定CPU数量的-j选项并行处理单个日志文件或多个文件。
如果要保存系统性能,也可以使用log_duration 替代log_min_duration_statement来仅报告持续时间和查询数。
pgBadger特性
· pgBadger报告有关SQL查询的所有信息:
总体统计数据。
等待最频繁的查询。
等待时间最长的查询。
生成最多临时文件的查询。
生成最大临时文件的查询。
最慢的查询。
占用时间最多的查询。
最频繁的查询。
最常见的错误。
查询时间直方图。
会话时间柱状图。
参与热门查询的用户。
顶级查询中涉及的应用程序。
产生最多取消的查询。
查询大部分被取消。
最耗时的准备/绑定查询。
· 还提供分为五分钟的小时图表
SQL查询统计信息。
临时文件统计。
检查点统计。
自动真空和自动分析统计数据。
取消的查询。
错误事件(死机、致命、错误和警告)。
错误类分布。
· 一些关于分布的饼图:
锁定统计信息。
按类型查询(选择/插入/更新/删除)。
每个数据库/应用程序的查询类型分布。
每个数据库/用户/客户端/应用程序的会话数。
每个数据库/用户/客户端/应用程序的连接数。
根据表格自动真空和自动分析。
每个用户的查询数和每个用户的总持续时间。
所有图表都是可缩放的,可以保存为PNG图像。报告的SQL查询将自动突出显示和美化。
· 可以解析PgBouncer日志文件并创建以下报告
请求吞吐量
字节I/O吞吐量
查询平均持续时间
同时举行的会议
会话时间柱状图
每个数据库的会话数
每个用户的会话数
每个主机的会话数
已建立的联系
每个数据库的连接数
每个用户的连接数
每个主机的连接数
使用最多的保留池
最常见错误/事件
pgBadger报告模式
· pgBadger报告模式
一小时一个报告
每天一个报告
每周一个累积报告的增量报告
每月一个报告
多个进程处理一个日志
多个进程处理多个日志
pgBadger部署
· 官方下载地址
https://github.com/darold/pgbadger/releases
· 编译与安装(root用户)
1、解压后进入该安装目录
# unzip pgbadger-master.zip
# cd pgbadger-master
2、编译并安装:
# perl Makefile.PL
# make && make install
3、默认安装目录:
/usr/local/bin/pgbadger
postgresql.conf配置
logging_collector = on
log_directory = 'pg_log‘
log_checkpoints = on
log_connections = on
log_disconnections = on
log_lock_waits = on
log_temp_files = 0
log_autovacuum_min_duration = 0
log_rotation_size=10240
--例如,对于“stderr”日志格式,日志行前缀必须至少为:
log_line_prefix = '%t [%p]: '
--日志行前缀可以添加用户、数据库名称、应用程序名称和客户端ip地址,如下所示:
log_line_prefix = '%t [%p]: user=%u,db=%d,app=%a,client=%h '
--或者对于syslog日志文件格式:
log_line_prefix = 'user=%u,db=%d,app=%a,client=%h '
--日志消息支持英文,不支持中文:
lc_messages='en_US.UTF-8'
lc_messages='C‘
--记录的日志语句
假如:log_statement=all
则:不会使用(log_min_duration_statement)记录任何内容
所以:log_min_duration_statement=0 #记录所有的统计信息包含实际的查询字符串
警告:不要同时启用log_min_duration_statement、log_duration and log_statement ,这将导致错误的计数器值。注意,这也会大大增加日志的大小。log_min_duration_statement应始终首选。
如何产生报告
当有许多小的日志文件和许多CPU时,一次将一个内核专用于一个日志文件会更快。要启用此行为,必须改用-J N选项。对于每个10MB的200个日志文件,-J选项的使用开始变得非常有效,有8个内核。使用此方法,您将确保不会丢失报表中的任何查询。
一个在服务器上完成的基准测试,有8个CPU和9.5GB的单个文件。
Option | 1 CPU | 2 CPU | 4 CPU | 8 CPU
--------+---------+-------+-------+------
-j | 1h41m18 | 50m25 | 25m39 | 15m58
-J | 1h41m18 | 54m28 | 41m16 | 34m45
200个日志文件,每个10MB,总共2GB,结果略有不同:
Option | 1 CPU | 2 CPU | 4 CPU | 8 CPU
--------+-------+-------+-------+------
-j | 20m15 | 9m56 | 5m20 | 4m20
-J | 20m15 | 9m49 | 5m00 | 2m40
--产生一个小时的日志报告:
$ pgbadger -q /usr/local/pg12.2/data/pg_log/postgresql-2020-06-19_00*.log \
-o /home/postgres/www/pg_reports/day-06-19-00.html
--产生每日和每周的日志报告:
$ pgbadger -I -q /usr/local/pg12.2/data/pg_log/* \
-O /home/postgres/www/pg_reports/ \
-f stderr
在这种模式下,pgBadger将在输出目录中创建一个自动增量文件。这意味着可以在每周旋转的日志文件上每天以这种模式运行pgBadger,并且它不会对日志条目计数两次,可以使用crontab进行定时运行。
--重建报告:
pgbadger -X -I -O /home/postgres/www/pg_reports/ --rebuild
此时在reports目录下产生创建一个目录,里面包含js文件,同时在另外一个目录下创建一个目录week-25,存放index文件。
它还将更新所有资源文件(JS和CSS)。如果报表是使用此选项生成的,请使用-E或--explode。
--默认情况下,增量模式下的pgBadger只计算每日和每周报告。如果需要每月累积报告,则必须使用单独的命令指定要生成的报告。例如,为2019年8月编制一份报告:
pgbadger --month-report 2919-08 /path/to/incremantal/reports/
JSON FORMAT
JSON格式有利于与其他语言共享数据,这使得pgBadger结果很容易集成到其他监控工具(如Cacti或Graphite)中。
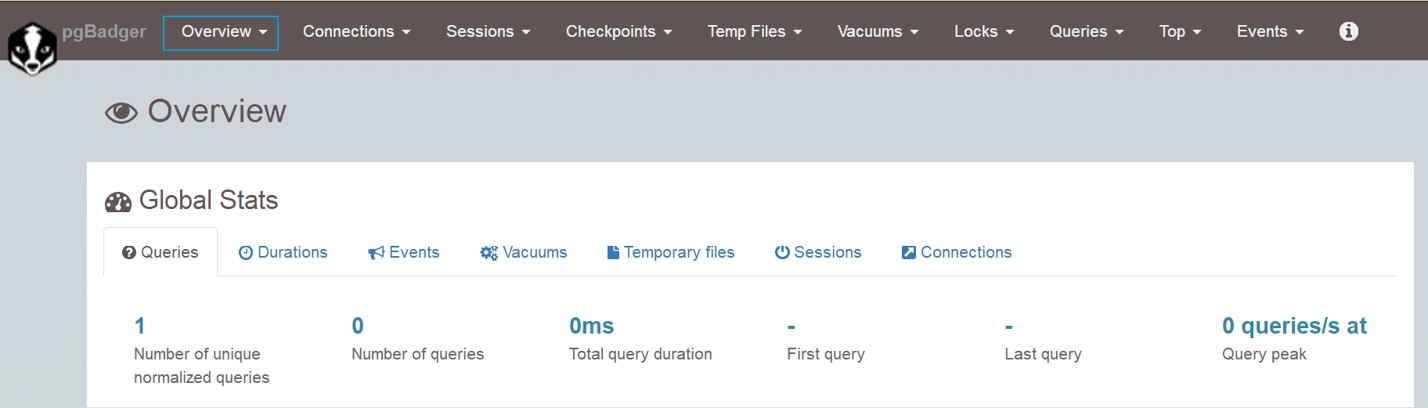
报告界面一
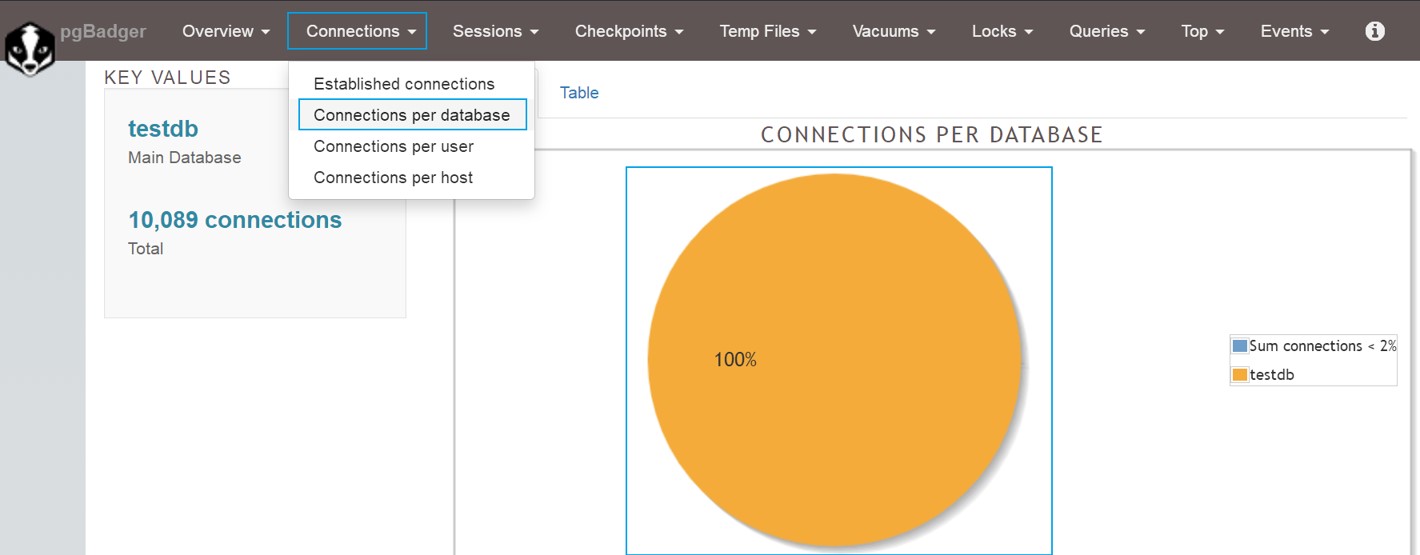
报告界面二
CUUG PostgreSQL技术大讲堂系列公开课,往期视频及文档,请联系CUUG客服。