Redis中Hash类型的命令
目录
哈希类型的命令
hset
hget
hexists
hdel
hkeys
hvals
hgetall
hmget
hlen
hsetnx
hincrby
hincrbyfloat
内部编码
Hash类型的应用场景
作为缓存
哈希类型和关系型数据库的两点不同之处
缓存方式对比
Redis自身已经是键值对的结构了,Redis自身的键值对就是通过哈希的方式来组织的.
把key这一层组织完成之后,到了value这一层,value还可以是哈希.
在Redis中哈希类型的映射关系通常称为field-value,用于区分Redis整体的键值对(key-value).所以哈希类型当中value指的是field对应的值,不是键key对应的值.
字符串和哈希类型的比较
当我们需要存储一个uid为1的用户对象,姓名是zhangsan,年龄是18.
用字符串时,我们需要设置两个key-value,一个user:1:name-zhangsan和user:1:age-18.
而我们使用哈希时只需要一个键即可user:1->name-zhangsan,age-18.
哈希类型的命令
hset
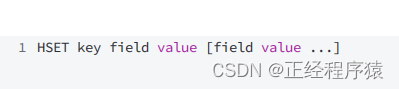
设置hash中指定的field的value.
返回值是设置成功的键值对(field-value)的个数.
注意hash类型中的value只能是字符串类型的.

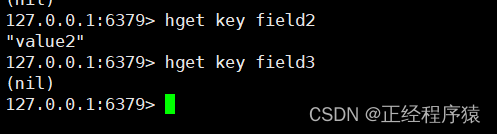
hget
hget key field
获取哈希中指定字段的值.
返回值是字段对应的值或者是nil.
 .
.
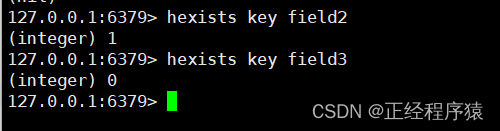
hexists
hexists key field
判断hash中是否有指定字段的值.
返回1表示存在,0表示不存在.
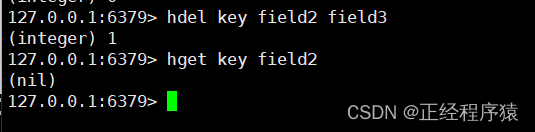
hdel
hdel key field [field......]
删除hash中指定的字段.
注意del命令删除的key而hdel命令删除的是field.
返回的是本次操作删除的字段个数.
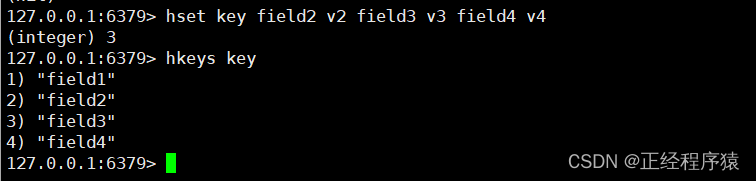
hkeys
hkeys key
获取hash中所有的字段.
返回的是字段列表.
hvals
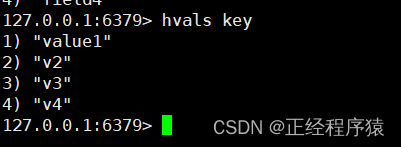
hvals key
获取hash中所有的值.
返回的是所有的val值.
hgetall
hgetall key
获取hash中所有的字段以及其对应的值.
返回的是字段和对应的值.
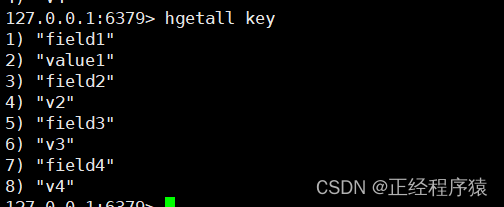
field和value是交替出现的.
hmget
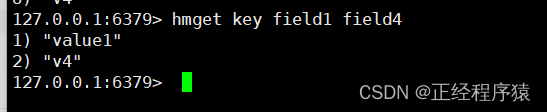
hmget key field [field......]
一次获取hash中多个字段的值.
返回的是字段对应的值或者是nil.
hash中也有hmset能够一次设置多个field和value,但是我们不需要使用,因为hset已经支持一次设置多个field和values了.
hlen
hlen key
获取hash中所有字段的个数.
返回的是字段个数.

hsetnx
hsetnx key field value
在字段不存在的情况下,设置hash中字段的值.
返回1表示设置成功,返回0表示设置失败.

如果key也不存在,也会创建key.
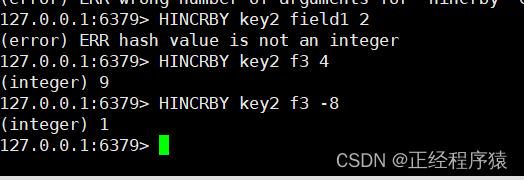
hincrby
hincrby key field increment
将hash中字段对应的数值添加指定的值.此时value必须能被当作数字处理.
hincrbyfloat
这是hincrby的浮点数版本.
hincrbyfloat key field increment

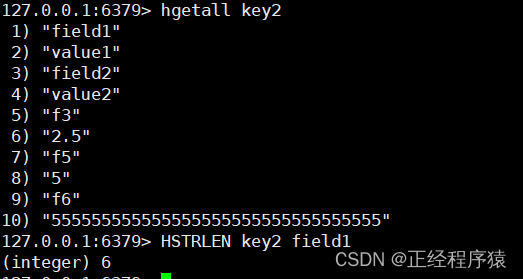
hstrlen
hstrlen key field
计算value的字符串长度.
内部编码
哈希类型的内部编码是ziplist和hashtable.
使用ziplist目的是为了节省内存空间,因为当数据元素不多的时候,使用一个hash表来表示,可能会造成空间的浪费,hash首先是一个数组,数组上的有些位置上有元素,有的元素可能就没有元素,就会造成浪费.但是数据元素过多的时候,此时在使用ziplist,读写元素的速度会比较慢,此时就要使用hashtable来组织和存储数据.
如果哈希中的元素比较少,使用ziplist表示,元素个数比较多的时候使用hashtable来表示.
如果每个value的值的长度都比较短,使用ziplist表示,如果某个value的长度太长了,也会转换哼hashtable.
对于多少个元素是多,多长的value算长,redis中有两个配置.
hash-max-ziplist-entries配置.(默认是512个).
hash-max-ziplist-value配置.(默认是64字节).

我们可以在redis的配置文件中对其进行修改.根据不同的业务场景选择更加契合当前业务的值.
Hash类型的应用场景
作为缓存
string类型也可以作为缓存使用,但是存储结构话的数据,使用hash更加合适一些.
比如mysql中有一个表.
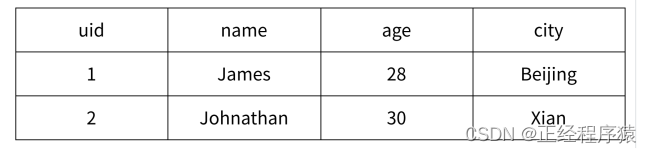
使用hash可以更加直观的表示表中的每一条记录.
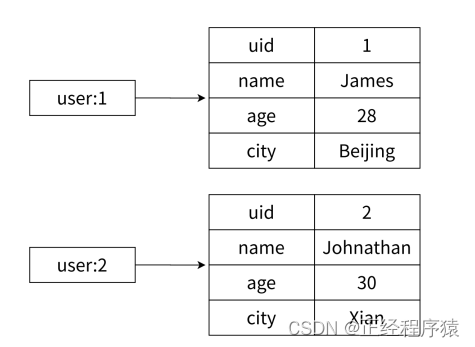
上述场景使用string类型也可以做到,要用到json这样的数据格式.
如果使用string(json格式)来表示userinfo,万一只想获取其中的一个field或者修改某个field的值,就需要把整个json都读出来,解析成对象,在操作field,最后重新转写成json字符串,在写回去.
如果使用hash的方式来表示userinfo.就可以使用field表示对象的某个属性,此时就可以非常方便的修改/获取任何一个属性的值了.
使用hash的方式读写field更加直观高效,但是付出的是空间的代价.
哈希类型和关系型数据库的两点不同之处
1.哈希类型是稀疏的,而关系型数据库是完全结构化的.例如哈希的每个键都可以有不同的field,而关系型数据库一旦添加新的列,所有行都要为其设置值,即使是null也要设置.
2.关系型数据库可以做复杂的关系查询,而redis去模拟关系型复杂查询基本不可能,维护成本很高.
缓存方式对比
目前,我们已经掌握了三种缓存用户信息的方法.
1.原生字符串类型-使用字符串类型,每个属性一个键
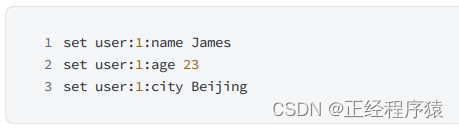
优点:实现比较简单,针对个别属性的操作更加灵活.
缺点:占用过多的键,内存的占用量较大,同时用户的信息在redis中比较分散,缺少内聚性,所以这种方案基本没有实用性.
2.序列化字符串类型-json格式

优点:针对总是以整体作为操作的场景比较合适,编程也简单.同时,如果序列化的方案选择合适,内存的使用效率很高.
缺点:本身的序列化和反序列化需要一定的开销,同时如果针对某个属性进行操作会变的不灵活.
3.哈希类型

优点:简单,直观,灵活.尤其是针对信息的局部变更.
缺点:需要控制哈希在两种内部编码之间的转换,可能会造成内存的较大消耗.