Python:PDF转长图像和分页图像
简介:随着电子化文档的普及,PDF文件的使用频率越来越高。有时我们需要将PDF中的内容转化为图片格式进行分享或编辑,那么如何才能轻松地完成此任务呢?本文将为你展示一个Python工具:如何将PDF文件转化为图片,包括将PDF转化为长图像和每页分别转为单独的图像。
历史攻略:
python:pdf 转 word
安装步骤:
# Ubuntu:
sudo apt-get update
sudo apt-get install python3-pip
sudo apt-get install poppler-utils
pip3 install pdf2image
pip3 install Pillow# CentOS:
yum update
yum install python3-pip
yum install poppler-utils
pip3 install pdf2image
pip3 install Pillow# Windows 10:
安装Python:访问Python官网下载并安装Python。
安装poppler:下载poppler for Windows并解压。
设置poppler环境变量:将poppler的bin目录路径添加到系统PATH环境变量中。# 安装库
pip install pdf2image
pip install Pillow
参数说明:
pdf_path: 输入的PDF文件的路径。
output_image_path: 输出的长图像的路径。
output_folder: 输出的单页图像的文件夹路径。
poppler_path: poppler工具的bin目录路径,此路径是在Windows下必要的,因为pdf2image库需要它来进行PDF到图像的转换。
案例源码:
# -*- coding: utf-8 -*-
# time: 2023/10/23 15:53
# file: pdf2picture.py
# 公众号: 玩转测试开发import os
from pdf2image import convert_from_path
from PIL import Imagedef pdf_to_long_image(pdf_path, output_image_path):# 从PDF提取每一页为图像pages = convert_from_path(pdf_path, poppler_path='C:\\Users\\poppler-23.08.0\\Library\\bin')# 获取总的高度total_height = sum(page.height for page in pages)# 创建一个空白的长图像long_image = Image.new('RGB', (pages[0].width, total_height))# 将每一页的图像粘贴到长图像上y_offset = 0for page in pages:long_image.paste(page, (0, y_offset))y_offset += page.height# 保存长图像long_image.save(output_image_path)def pdf_to_images(pdf_path, output_folder):# 将PDF转换为PIL图像列表pages = convert_from_path(pdf_path, poppler_path='C:\\Users\\poppler-23.08.0\\Library\\bin')# 确保输出文件夹存在if not os.path.exists(output_folder):os.makedirs(output_folder)# 将每页保存为单独的图像for i, page in enumerate(pages):image_filename = os.path.join(output_folder, f"output_image_page_{i + 1}.png")page.save(image_filename, "PNG")if __name__ == '__main__':pdf_path = 'qp_01.pdf'output_folder = 'output_images'# 使用示例pdf_to_long_image('qp_01.pdf', 'output_image.png')pdf_to_images(pdf_path, output_folder)
运行结果:
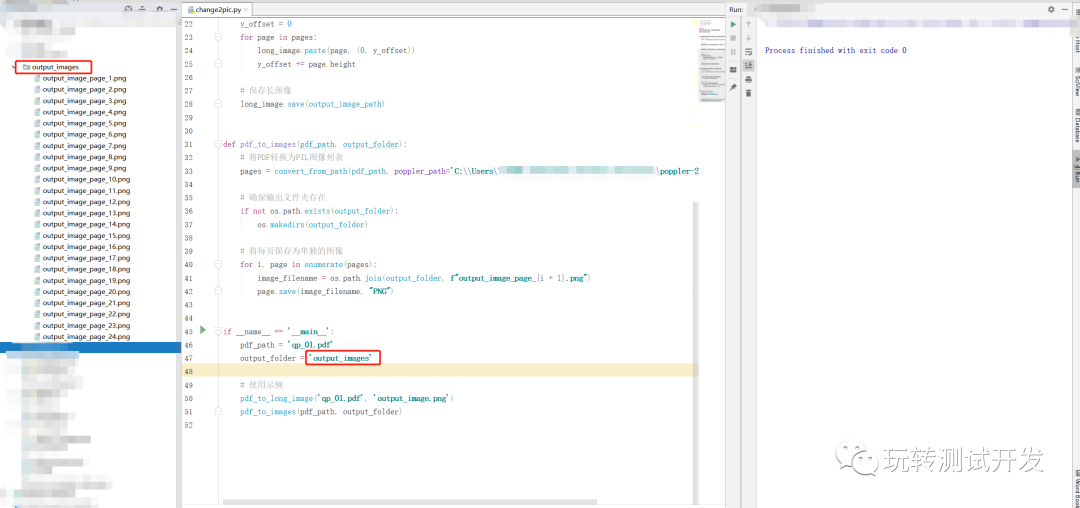
1、使用pdf_to_long_image函数,将得到合并了PDF所有页面长图像。
2、使用pdf_to_images函数,会在指定的输出文件夹中得到每一页PDF的单独图像文件,文件名格式为output_image_page_页码.png。
注意事项:
1、确保已经安装了所有必要的库和工具。
2、输入的PDF文件路径应该是有效的,否则程序会报错。
3、在Windows系统下,确保已经设置了poppler的环境变量或在代码中提供了正确的poppler路径。
4、生成的图像可能会占用较大存储空间,特别是当PDF文件页数较多时。
总结:通过Python可以轻松地实现PDF到图像的转换,不仅可以将整个PDF转为一个长图像,还可以将每一页分别转为单独的图像。这个小工具对于那些经常需要处理PDF的人来说非常有用。