机器学习2:决策树--基于信息增益的ID3算法
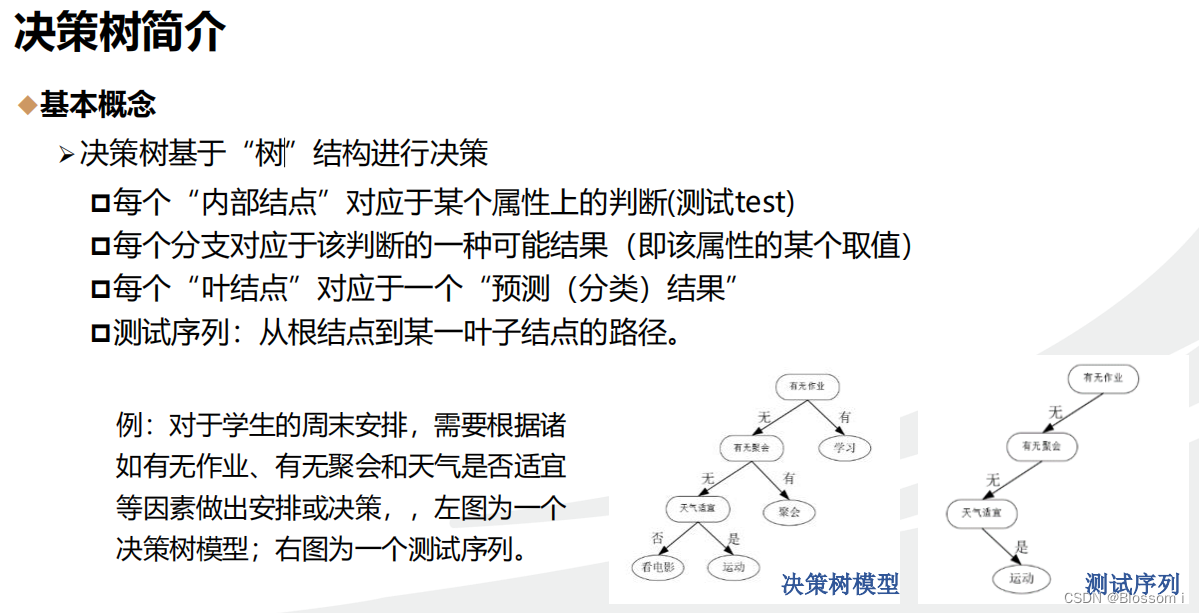
1.决策树的简介


建立决策树的过程可以分为以下几个步骤:
- 计算每个特征的信息增益或信息增益比,选择最优的特征作为当前节点的划分标准。
- 根据选择的特征将数据集划分为不同的子集。
- 对每个子集递归执行步骤 1 和步骤 2,直到满足终止条件。
- 构建决策树,并输出。
基于信息增益的ID3算法;
ID3算法:
- 计算每个特征的信息增益。信息增益 = H(D) - H(D|A),其中H(D)是样本的熵,H(D|A)是在特征A给定的条件下样本的条件熵。
- 选择信息增益最大的特征作为当前节点的划分标准。
- 对每个特征值创建一个子节点,并递归地执行步骤 1 和步骤 2。

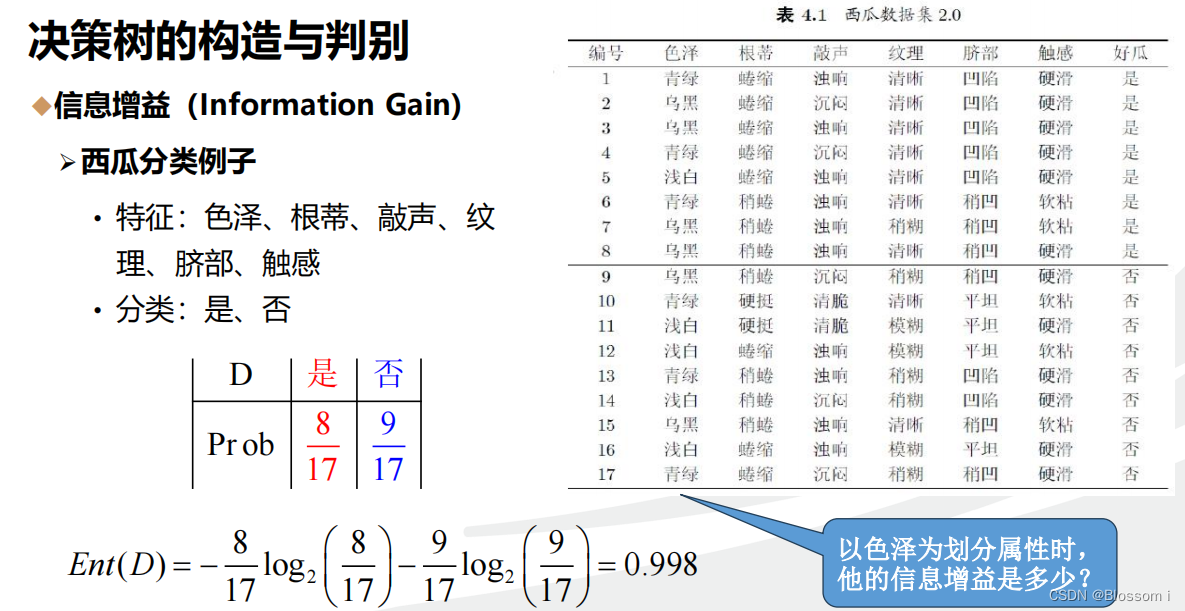
(1)信息熵的计算

案例1

案例2
(2)信息增益 Gain


案例1
