Batch Normalization
文章目录
- 一,Norimalize(归一化)的想法:
- 二,为什么要做归一化?
- 三,问题来了,如果标准正态分布约束过于严格了怎么办?
- 四,注意:Test-Time
- 五,Batch Normalization 放置的位置
- 六,Batch Normalization的优点
- 七,Layer Normalization
- 八,Instance Normalization
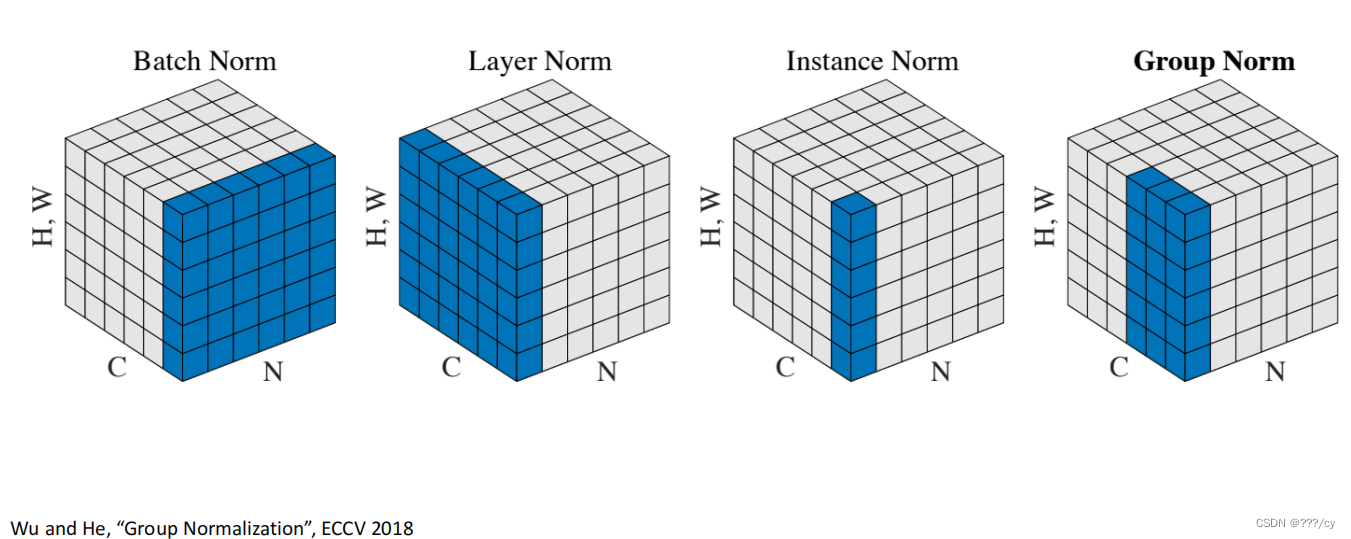
- 九,不同的Normalization的对比
一,Norimalize(归一化)的想法:
- 使得layer的输出为标准正态分布(均值为0,标准差为1)
二,为什么要做归一化?
-
帮助减少内部 internal covariate shift.
-
Internal Covariate Shift(内部协变量偏移)它指的是在训练深度神经网络时,由于每一层的输入分布在训练过程中不断变化,导致网络的学习变得困难的问题。具体来说,当一个层的输入分布发生变化时,该层需要不断地适应新的输入分布,这会使得网络的训练过程变得不稳定,同时也会影响收敛速度和性能。
-
把数据拉回标准正态分布,因为神经网络的Block大部分都是矩阵运算,一个向量经过矩阵运算后值会越来越大,为了网络的稳定性,我们需要及时把值拉回正态分布。

每一个维度来做均值,方差,得到标准正态分布。
三,问题来了,如果标准正态分布约束过于严格了怎么办?
- 这时候我们的,可学习的scale(缩放因子),shift(平移因子)就闪亮登场了。
- 这两个可学习的参数将修复我们的恒等式

四,注意:Test-Time
-
我们的均值和方差是在Minibatch的基础上做的。在test阶段,我们只单纯测试一张图片的话是得不到均值和方差的。此时,均值和方差用的就是训练过程中的平均值(average of values seen during training)
-
当testing的时候batchnorm就变成了一个线性运算(linear operator),可以跟前一层的全连接层或者卷积层融合起来计算。
五,Batch Normalization 放置的位置
- 通常在全连接层或者卷积层 之后,激活函数之前。
六,Batch Normalization的优点
- 使得更深的网络更简单的训练起来 Makes deep networks much easier to train!
- 用了batch normalization之后 可以设更大的学习率,让其更快的收敛
- 网络 对初始化更具有鲁棒性 了(因为做了归一嘛)
- 在训练的时候有起到 正则化 的效果
- 在test-time 零开销 :因为可以跟conv做融合嘛,一起计算。
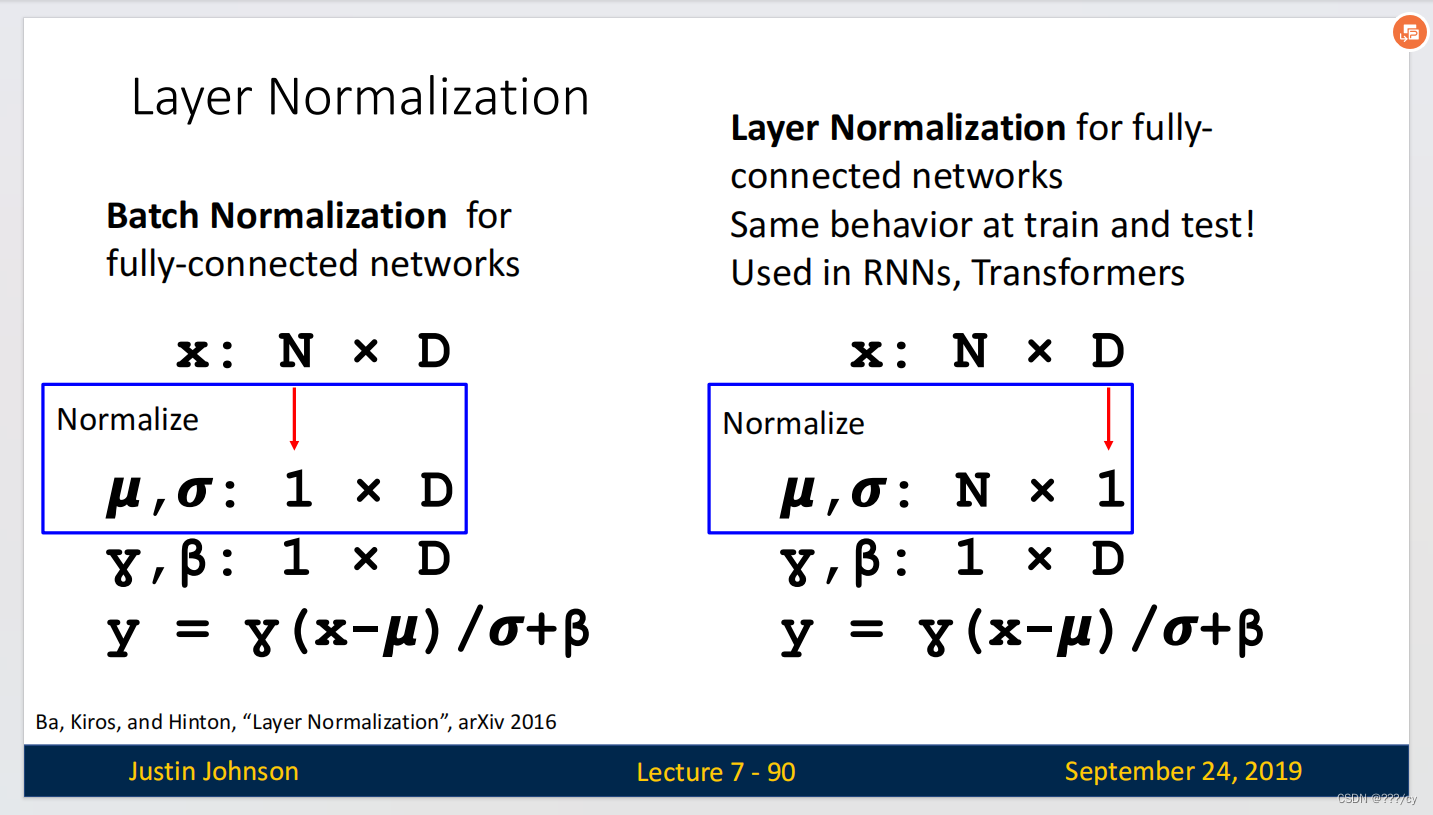
七,Layer Normalization
先来看一下Layer Normalization 与 Batch Normalization的区别
八,Instance Normalization

九,不同的Normalization的对比