Kafka - 3.x Kafka消费者不完全指北
文章目录
- Kafka消费模式
- Kakfa消费者工作流程
- 消费者总体工作流程
- 消费者组原理
- 消费者组初始化流程
- 消费者组详细消费流程
- 独立消费者案例(订阅主题)
- 消费者重要参数

Kafka消费模式
Kafka的consumer采用pull(拉)模式从broker中读取数据。
| 模式 | 优点 | 缺点 |
|---|---|---|
| Push(推)模式 | - 快速传递消息 - 消息发送速率由broker决定 | - 难以适应不同消费者的消费速率 - 可能导致拒绝服务和网络拥塞 |
| Pull(拉)模式 | - 可以根据消费者的消费能力以适当速率消费消息 | - 潜在的循环问题,如果Kafka没有数据,消费者可能会一直返回空数据 - 需要设置轮询的timeout以避免无限等待时长过长 |
Kakfa消费者工作流程
消费者总体工作流程
Kafka消费者的总体工作流程包括以下步骤:
-
配置消费者属性:首先,你需要配置消费者的属性,包括Kafka集群的地址、消费者组、主题名称、序列化/反序列化器、自动偏移提交等。
-
创建消费者实例:使用配置创建Kafka消费者实例。
-
订阅主题:使用消费者实例订阅一个或多个Kafka主题。这告诉Kafka消费者你想要从哪些主题中接收消息。
-
轮询数据:消费者使用
poll()方法从Kafka broker中拉取消息。它会定期轮询(拉)Kafka集群以获取新消息。 -
处理消息:一旦从Kafka broker获取到消息,消费者会对消息进行处理,执行你的业务逻辑。这可能包括数据处理、计算、存储或其他操作。
-
提交偏移量:消费者可以选择手动或自动提交偏移量,以记录已处理消息的位置。这有助于防止消息重复处理。
-
处理异常:处理消息期间可能会出现异常,你需要处理这些异常,例如重试或记录错误日志。
-
关闭消费者:在不再需要消费者实例时,确保关闭它以释放资源。
这个工作流程涵盖了Kafka消费者从配置到数据处理再到资源管理的主要步骤。消费者通常是多线程或多进程的,以处理大量的消息,并能够根据需要调整消费速率。此外,Kafka的消费者库提供了很多功能,如自动负载均衡、自动偏移管理等,以简化消费者的开发和维护。
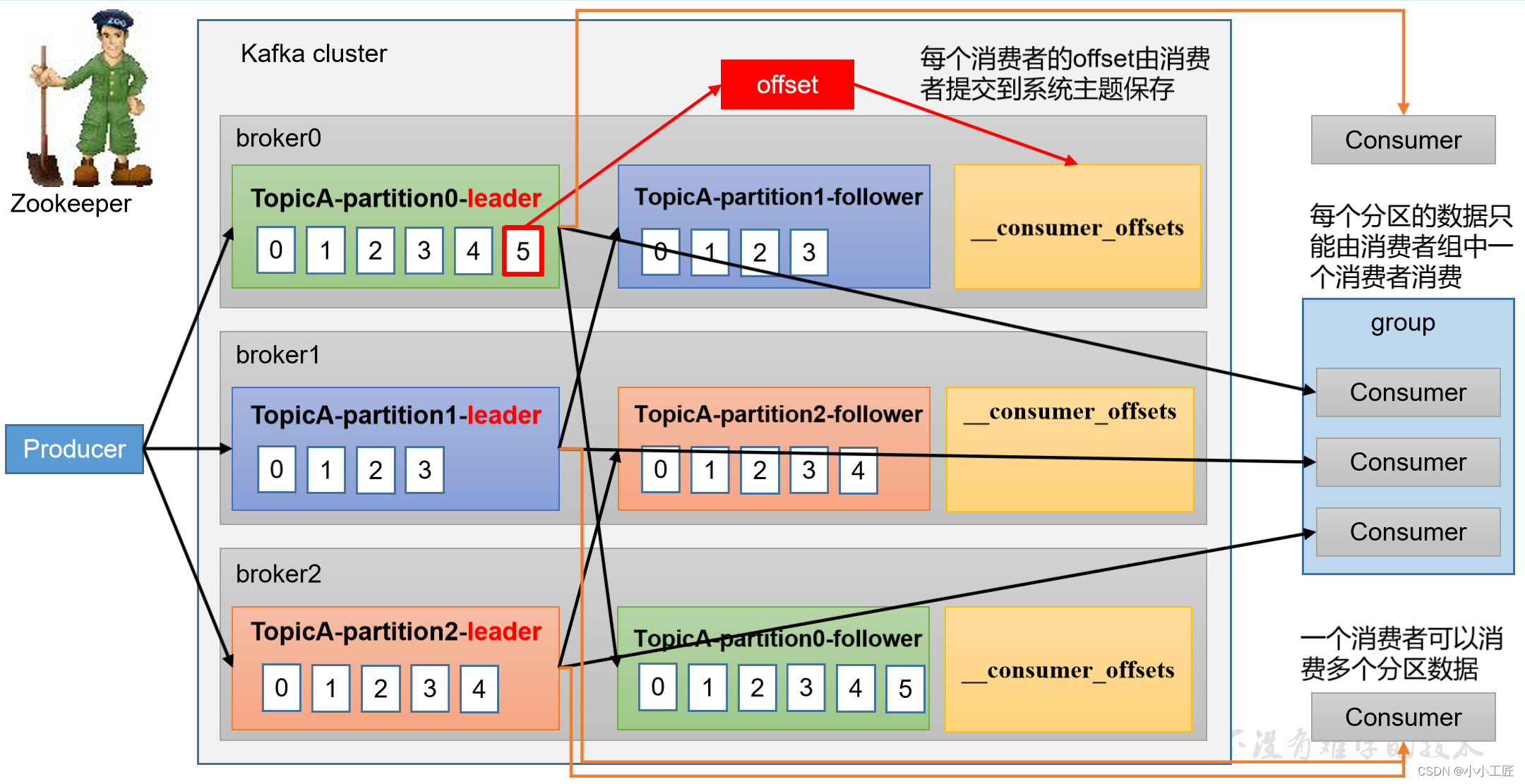
消费者组原理
Kafka消费者组(Consumer Group)是一种机制,用于协调和管理多个消费者并共同消费一个或多个Kafka主题的消息。消费者组的工作原理如下:
-
多个消费者:一个消费者组可以包含多个消费者实例,这些消费者实例协同工作以共同消费一个或多个主题的消息。
-
订阅主题:所有消费者实例都订阅相同的Kafka主题。这意味着每个消息都会被消费者组中的一个实例处理,从而实现消息的负载均衡。
-
消息分区:每个Kafka主题通常被分为多个分区,每个分区包含消息的一个子集。每个消费者实例负责消费一个或多个分区的消息。
-
协调者:消费者组中的消费者实例会选择一个协调者(Coordinator)来管理组内的消费者。协调者通常是ZooKeeper或Kafka自身的一个特殊主题。
-
偏移管理:协调者负责管理消费者组的偏移量(offset),这是消费者在主题分区中的当前位置。它会跟踪每个分区的消费进度,确保不会重复消费消息。
-
分配分区:协调者会定期重新分配分区给消费者实例,以确保负载均衡和故障恢复。如果有新消费者加入组或有消费者离开组,协调者会重新分配分区。
-
消费消息:每个消费者实例负责处理分配给它的分区中的消息。它会拉取消息,进行处理,并将偏移量提交给协调者。
-
自动重平衡:如果消费者实例加入或退出消费者组,或者分区的分配发生变化,消费者组会自动进行重新平衡,以确保消息均匀分配。
-
提交偏移量:消费者实例可以定期或根据需要提交已处理消息的偏移量,以便在故障时恢复消费进度。
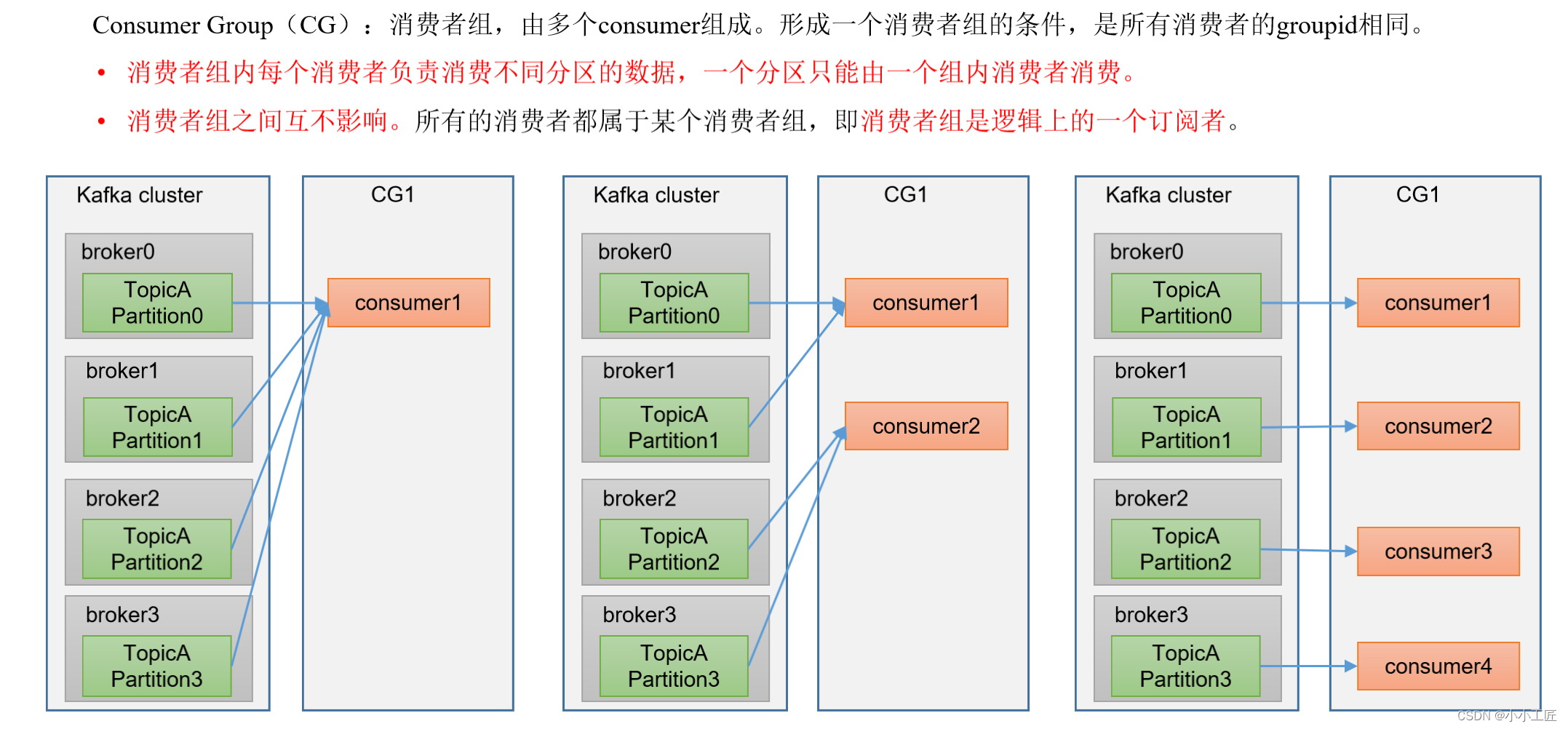
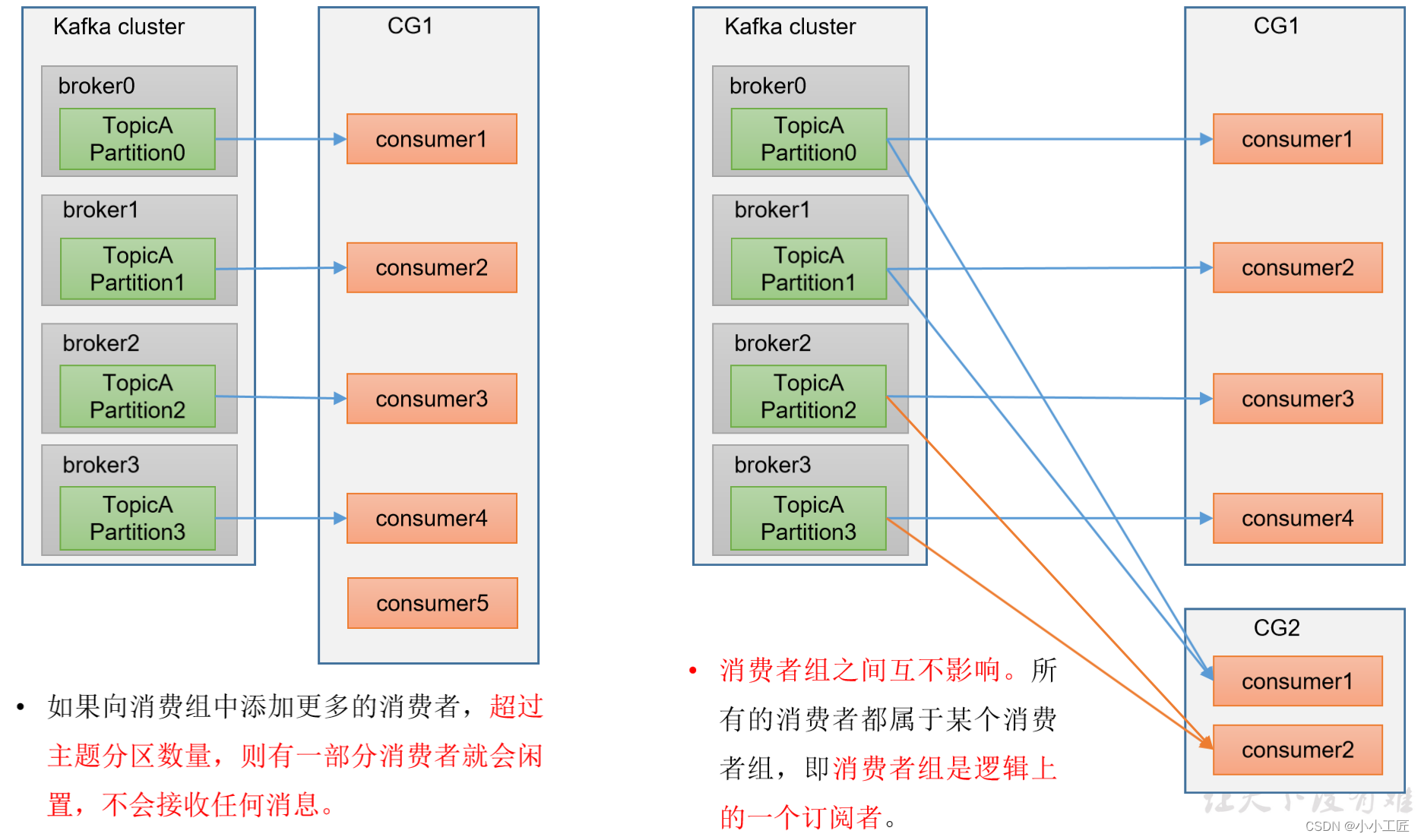
通过这种方式,Kafka消费者组能够实现高可用性、负载均衡和容错,允许多个消费者并行处理消息,并根据需求动态调整分区分配。这使得消费者组成为了处理大规模流式数据的理想工具。
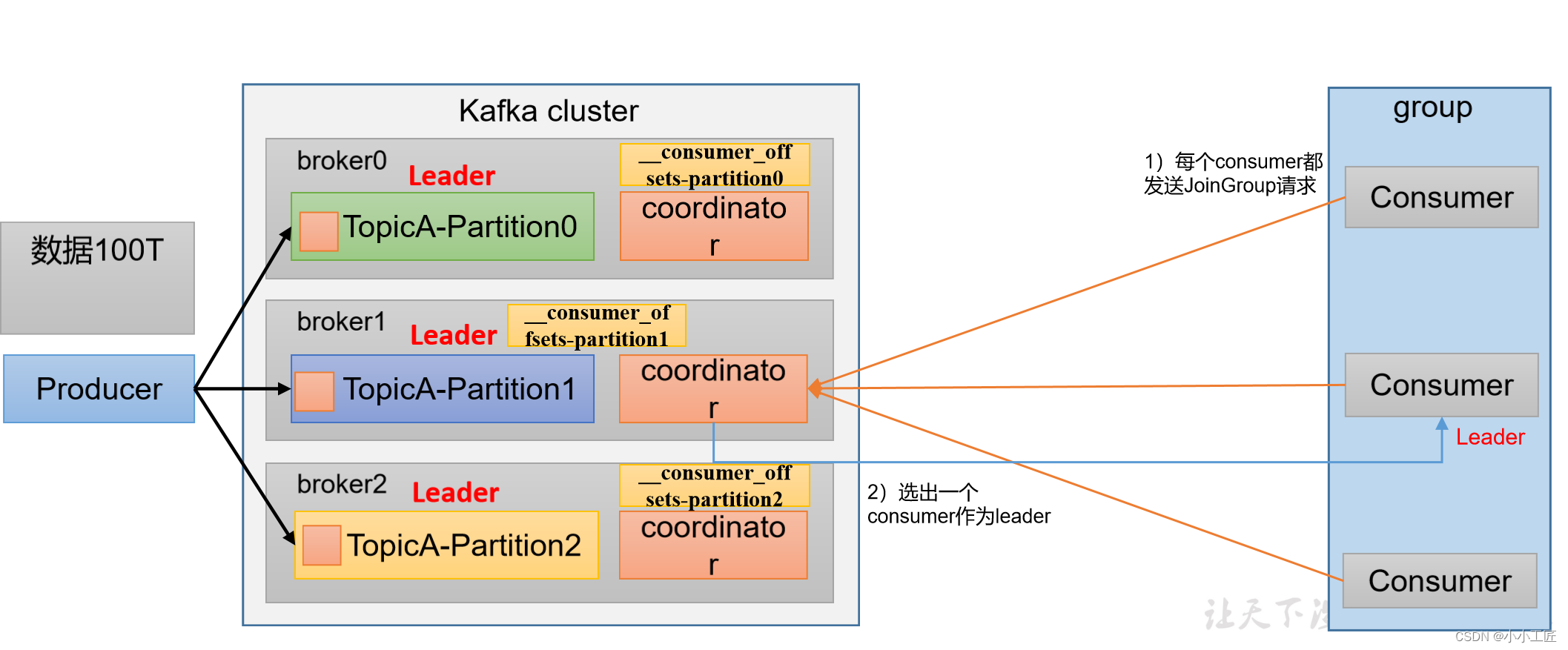
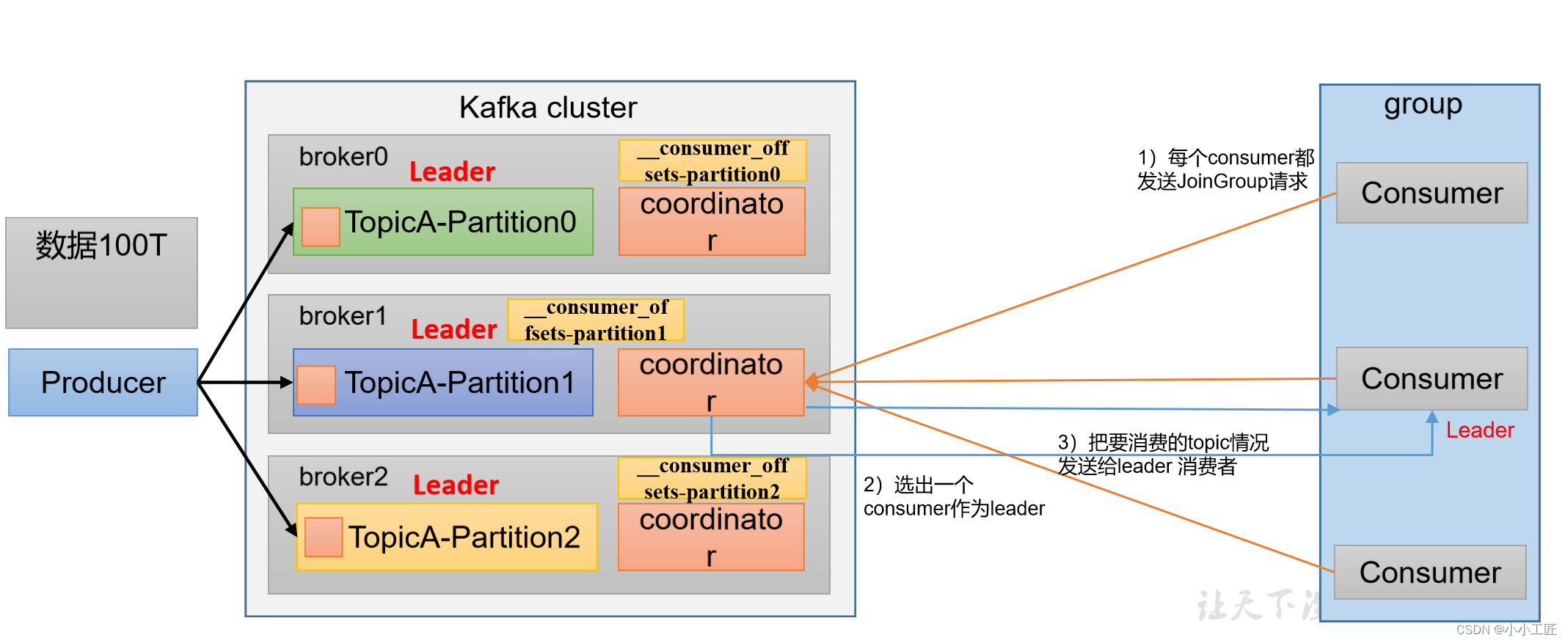
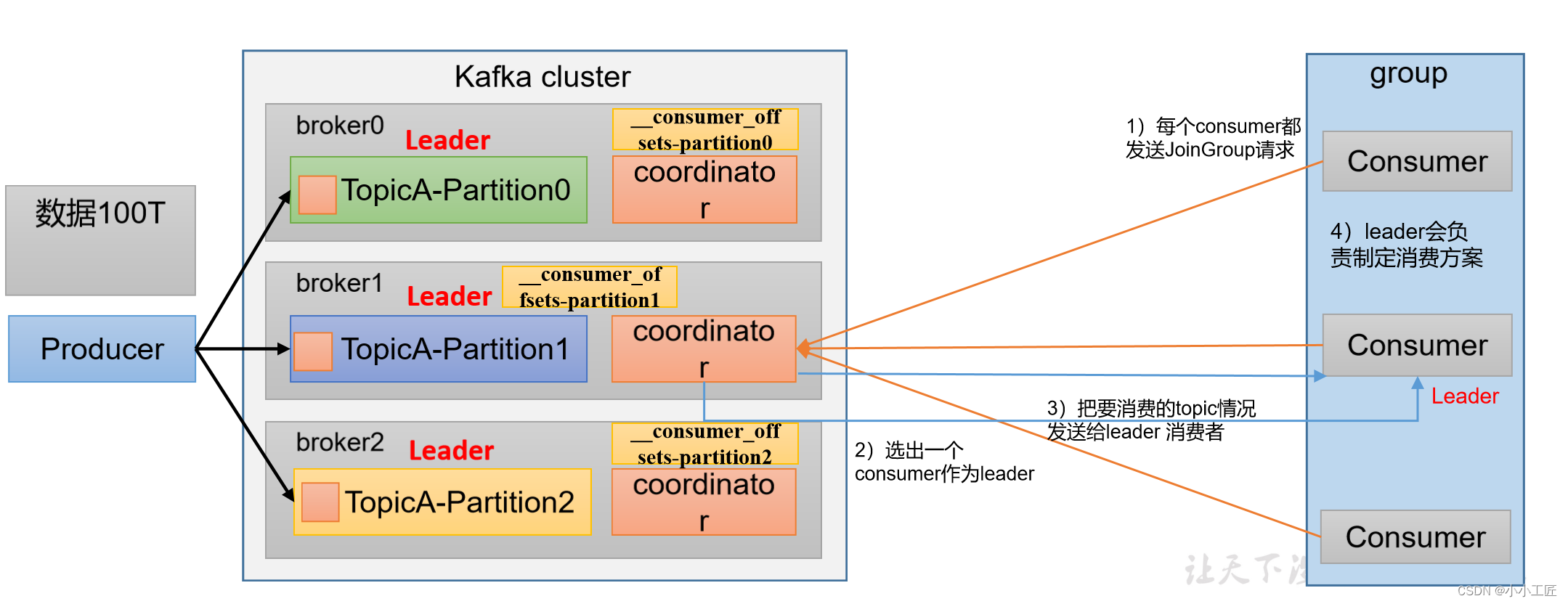
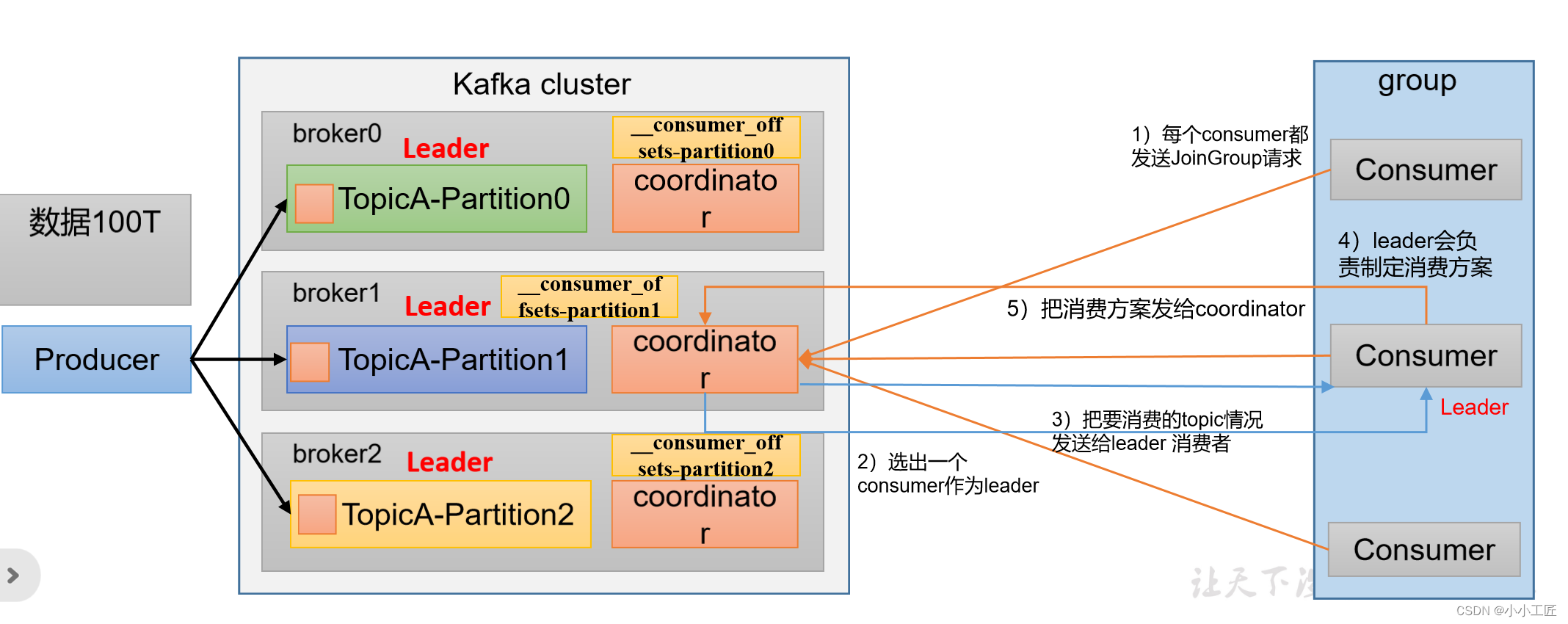
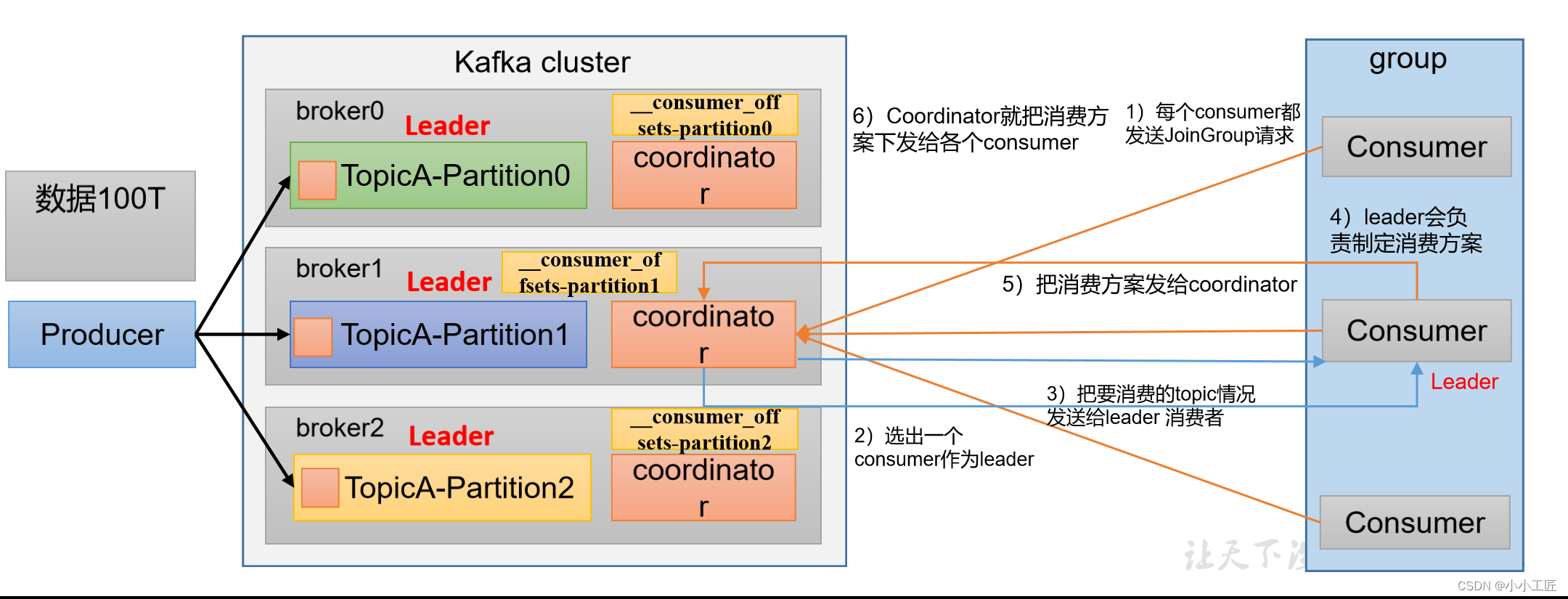
消费者组初始化流程
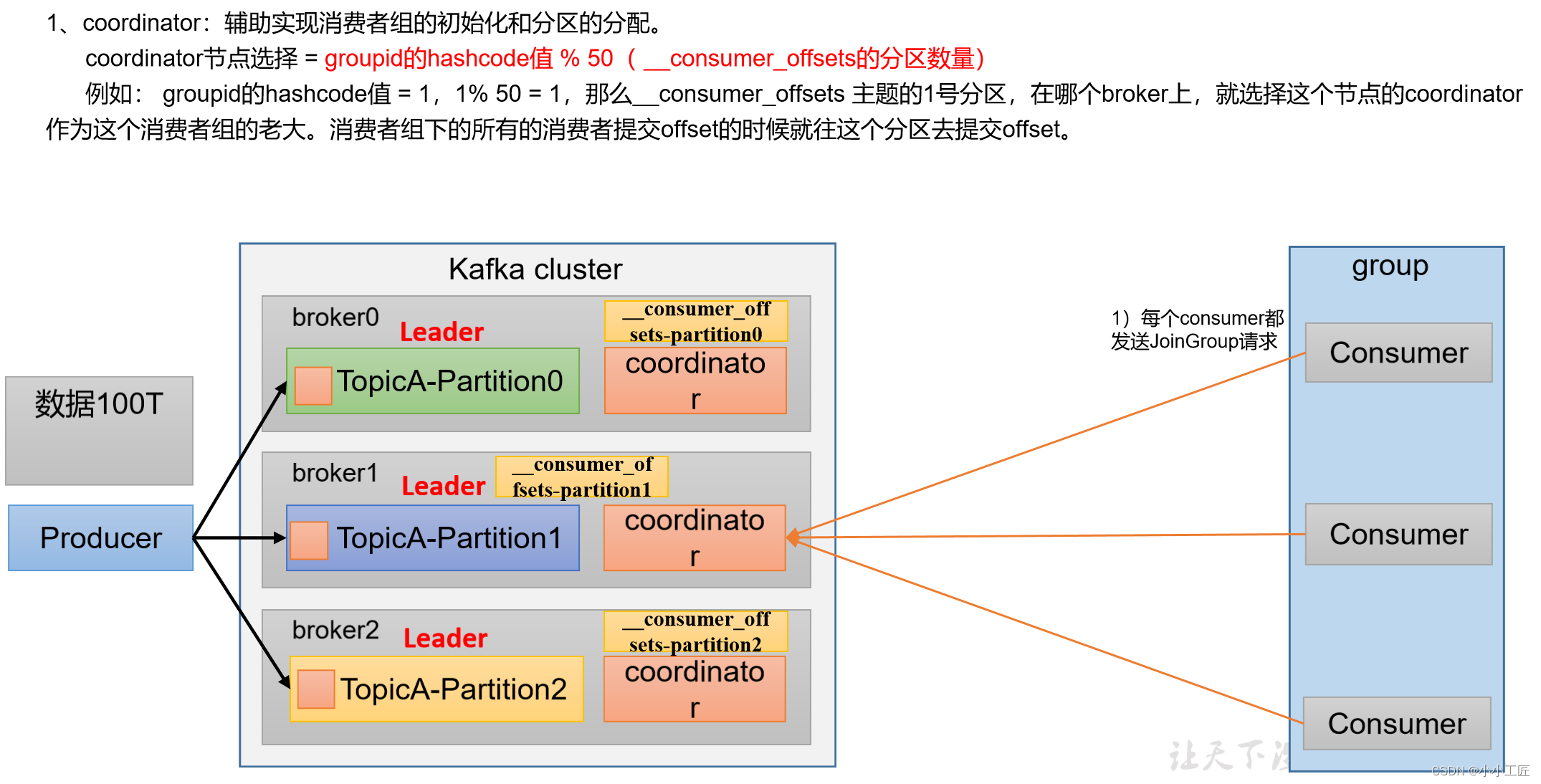
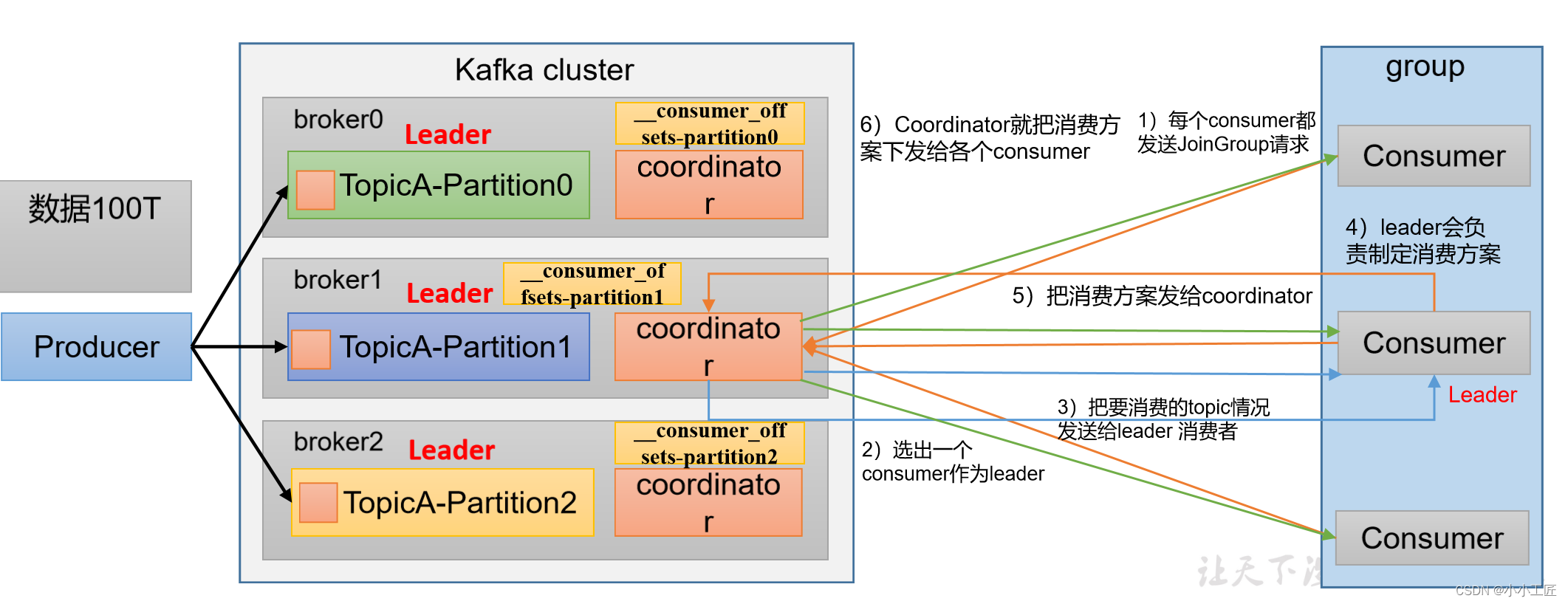
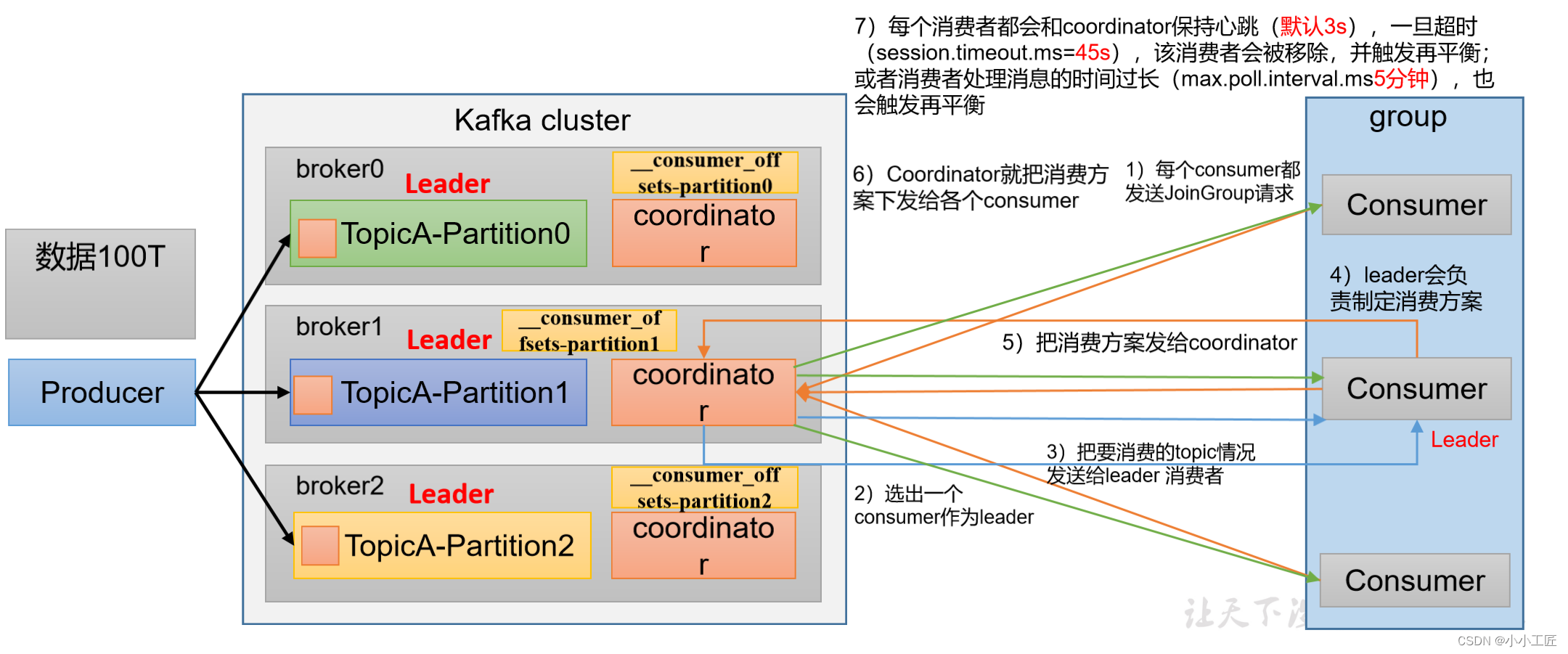
消费者组详细消费流程
Kafka消费者组的初始化流程包括一系列步骤,用于创建和配置消费者组的成员。以下是Kafka消费者组的初始化流程:
-
引入Kafka客户端库:首先,确保你的应用程序中引入了Kafka客户端库,以便能够使用Kafka相关的类和功能。
-
创建消费者配置:初始化消费者组前,需要创建一个消费者配置对象,其中包括了一些重要的属性,例如Kafka集群的地址、消费者组的ID、自动提交偏移量等。
-
创建消费者实例:使用消费者配置,创建一个或多个消费者实例。每个实例代表一个消费者组中的一个成员。实例会自动注册到Kafka broker,并与协调者建立连接。
-
订阅主题:通过消费者实例,使用
subscribe()方法订阅一个或多个Kafka主题。这告诉Kafka你希望从哪些主题中接收消息。 -
启动消费者:调用
poll()方法开始轮询消息。这将启动消费者实例并开始拉取消息。消费者组中的每个成员都会独立执行这个步骤。 -
消费消息:一旦消息被拉取,消费者实例会处理这些消息,执行你的业务逻辑。每个成员在自己的线程中处理消息。
-
提交偏移量:消费者实例可以选择手动或自动提交已处理消息的偏移量。这有助于记录每个分区中消息的处理进度。
-
处理异常:处理消息期间可能会出现异常,你需要适当地处理这些异常,例如重试消息或记录错误日志。
-
关闭消费者:当不再需要消费者实例时,确保关闭它以释放资源。
-
自动重平衡:如果有消费者实例加入或离开消费者组,或者分区的分配发生变化,Kafka会自动进行重新平衡,以确保消息均匀分配。
这个初始化流程涵盖了Kafka消费者组的基本步骤,从配置消费者组成员到消息的处理和消费。请注意,Kafka消费者组的初始化需要注意各个配置选项以及消费者组的协调过程,以确保正常运行和负载均衡。
独立消费者案例(订阅主题)
需求:创建一个独立消费者,消费artisan主题中的数据
注意:在消费者API代码中必须配置消费者组id。
package com.artisan.pc;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;/*** @author 小工匠* @version 1.0* @mark: show me the code , change the world*/
public class CustomConsumer {public static void main(String[] args) {// 1.创建消费者的配置对象Properties properties = new Properties();// 2.给消费者配置对象添加参数properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.126.171:9092");// 配置序列化 必须properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消费者组 必须properties.put(ConsumerConfig.GROUP_ID_CONFIG, "artisan-group");// 3. 创建消费者对象KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);// 4. 订阅主题ArrayList<String> topics = new ArrayList<>();topics.add("artisan");consumer.subscribe(topics);// 5. 拉取数据打印while (true) {ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));// 6. 遍历并输出消费到的数据for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}}
}① 在IDEA中执行消费者程序
② 服务器上中创建kafka生产者,并输入数据

③ 在IDEA中观察接收到的数据
ConsumerRecord(topic = artisan, partition = 2, leaderEpoch = 0, offset = 34, CreateTime = 1698630425187, serialized key size = -1, serialized value size = 13, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = first message)
ConsumerRecord(topic = artisan, partition = 2, leaderEpoch = 0, offset = 35, CreateTime = 1698630429909, serialized key size = -1, serialized value size = 15, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = seconde message)消费者重要参数
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 向Kafka集群建立初始连接用到的host/port列表。 |
| key.deserializer | 指定接收消息的key的反序列化类型。需要写全类名。 |
| value.deserializer | 指定接收消息的value的反序列化类型。需要写全类名。 |
| group.id | 标记消费者所属的消费者组。 |
| enable.auto.commit | 默认值为true,消费者会自动周期性地向服务器提交偏移量。 |
| auto.commit.interval.ms | 若enable.auto.commit=true,表示消费者提交偏移量的频率,默认为5秒。 |
| auto.offset.reset | 当Kafka中没有初始偏移量或当前偏移量在服务器中不存在时的处理方式。可选值包括"earliest"、“latest”、“none”、 |
| offsets.topic.num.partitions | __consumer_offsets的分区数,默认是50个分区。 |
| heartbeat.interval.ms | Kafka消费者和coordinator之间的心跳时间,默认为3秒。必须小于session.timeout.ms,也不应该高于session.timeout.ms的1/3。 |
| session.timeout.ms | Kafka消费者和coordinator之间连接超时时间,默认为45秒。超过该值,消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认为5分钟。超过该值,消费者被移除,消费者组执行再平衡。 |
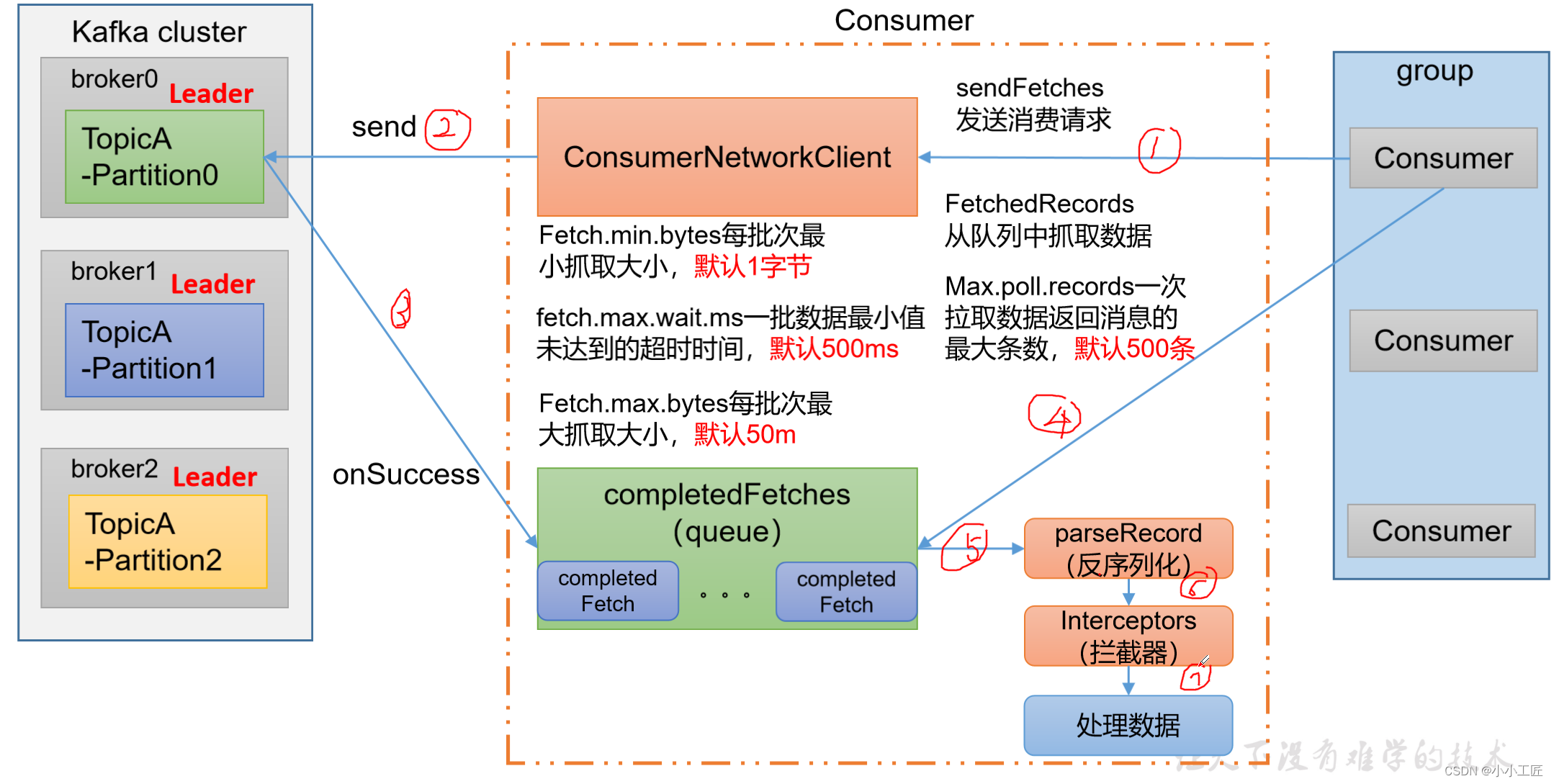
| fetch.min.bytes | 消费者获取服务器端一批消息最小的字节数,默认为1个字节。 |
| fetch.max.wait.ms | 默认为500毫秒。如果没有从服务器端获取到一批数据的最小字节数,等待时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认为52428800(50兆字节)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值,仍然可以拉取回这批数据,这不是一个绝对最大值,一批次的大小受message.max.bytes(broker配置)或max.message.bytes(topic配置)影响。 |
| max.poll.records | 一次poll拉取数据返回消息的最大条数,默认为500条。 |
