python网络爬虫—快速入门(理论+实战)(七)
系列文章目录
(1)python网络爬虫—快速入门(理论+实战)(一)
(2)python网络爬虫—快速入门(理论+实战)(二)
(3) python网络爬虫—快速入门(理论+实战)(三)
(4)python网络爬虫—快速入门(理论+实战)(四)
(5)python网络爬虫—快速入门(理论+实战)(五)
(6)python网络爬虫—快速入门(理论+实战)(六)
序言
本人从事爬虫相关工作已8年以上,从一个小白到能够熟练使用爬虫,中间也走了些弯路,希望以自身的学习经历,让大家能够轻而易举的,快速的,掌握爬虫的相关知识并熟练的使用它,避免浪费更多的无用时间,甚至走很大的弯路。欢迎大家留言,一起交流讨论。
本节学习目标
掌握python网络爬虫如何解析json数据,通过爬取腾讯招聘网的数据示例掌握json数据的解析,加深对爬虫从分析到爬取再到解析这个过程的理解。
特别申明
本网络爬虫系列教程,只是为了记录个人对网络爬虫的学习和总结,期间所使用到的爬虫示例仅仅作为学习使用,请勿传播,请勿用于商用,请勿对目标网站造成攻击或者窃取非法数据等。
4.3 动手写网络爬虫——解析json数据(以爬取腾讯招聘网数据为例)
在前面的章节,我们学习过,爬虫基本流程的第一步就是发送请求,这就要求我们在爬取之前要弄清楚发送的这个请求的url是哪个。一般来讲,我们尽量去找响应结果是json数据格式的那个请求url,这是因为,对于json的数据解析比较简单,你只需要分析清楚返回的json数据中各个属性值的意义,然后用json库去取值就可以了。
需要引入json库:
import json#将响应数据转为json
json_data=json.loads(data.text)
#根据json中的数据值结果去获取相应值
.......
为了更加清晰的理解如何解析json数据,我们这里将以爬取腾讯招聘网上的工作信息,来理解json数据的解析过程。
1.首先,打开浏览器(以谷歌浏览器为例)进入腾讯招聘网站(https://careers.tencent.com/)
2.输入“数据分析”查找工作岗位:
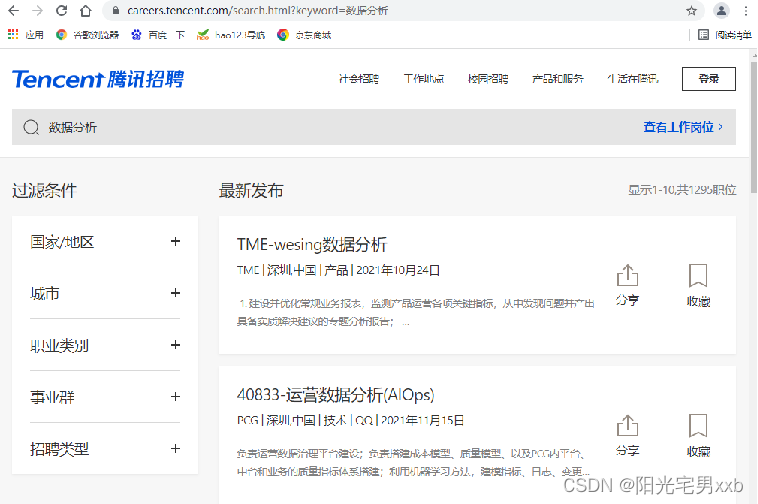 3. 按键盘上的F12按键,查看网页源码:
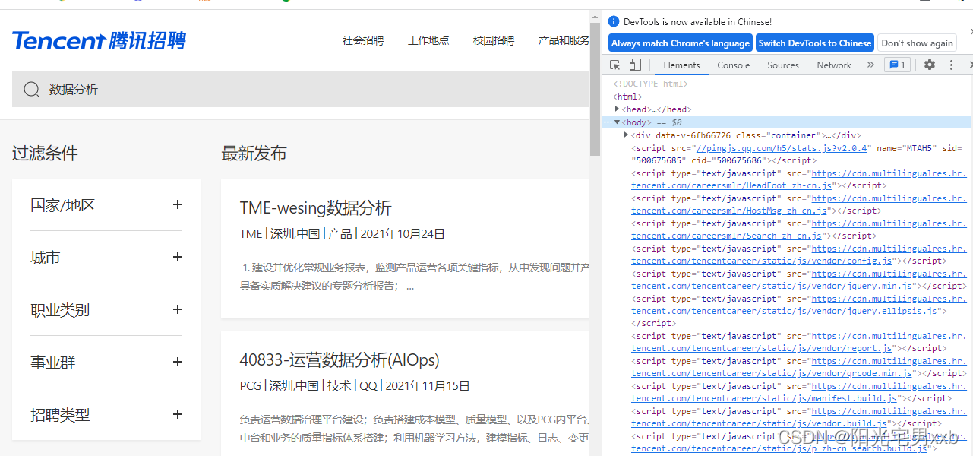
3. 按键盘上的F12按键,查看网页源码:
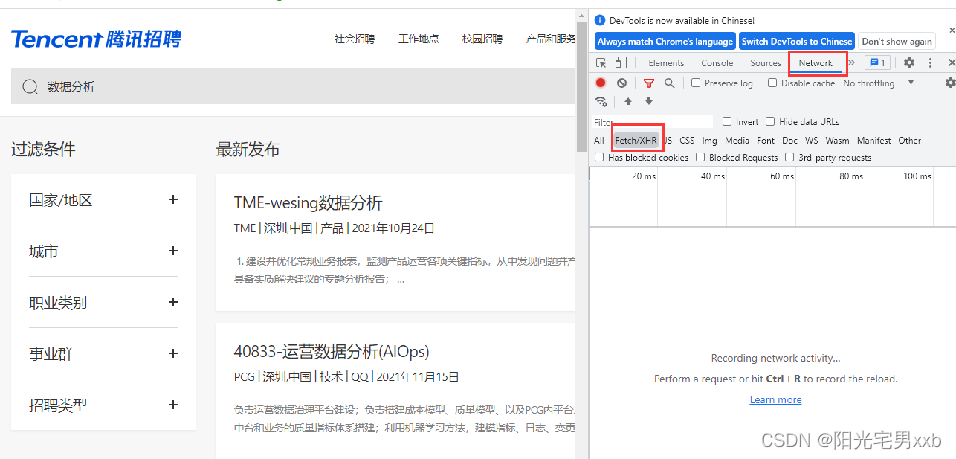
4.点击右侧源码顶部的Network,然后点击下面的Fetch/XHR:
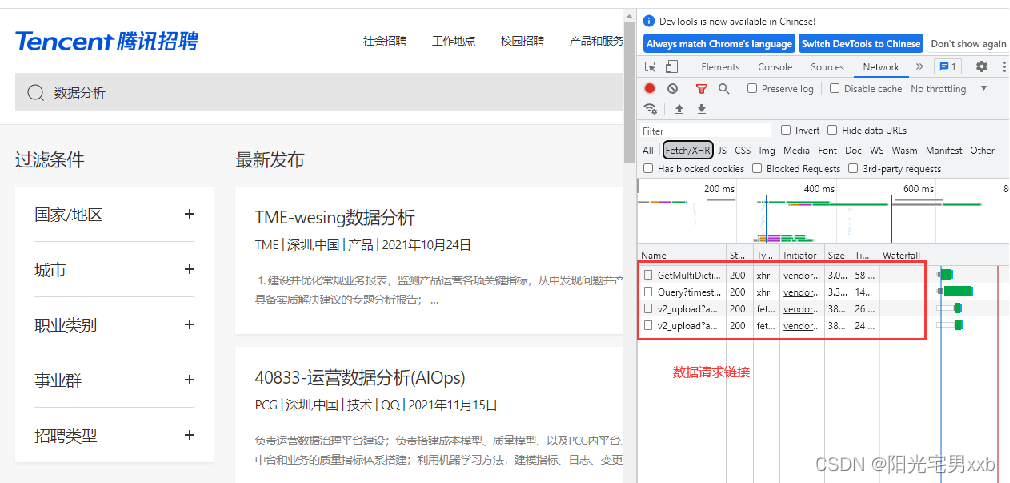
5. 点击键盘上的F5刷新页面,可以在右侧看到页面的数据请求链接信息:
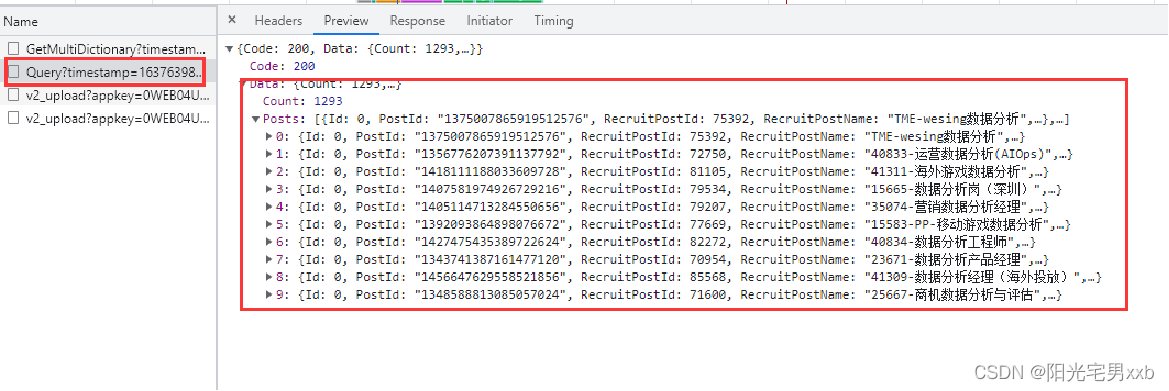
6.依次点击各个请求链接进行分析,查找哪个请求链接获取的数据是我们所需要的,我们可以看到请求的结果是一个json格式的:
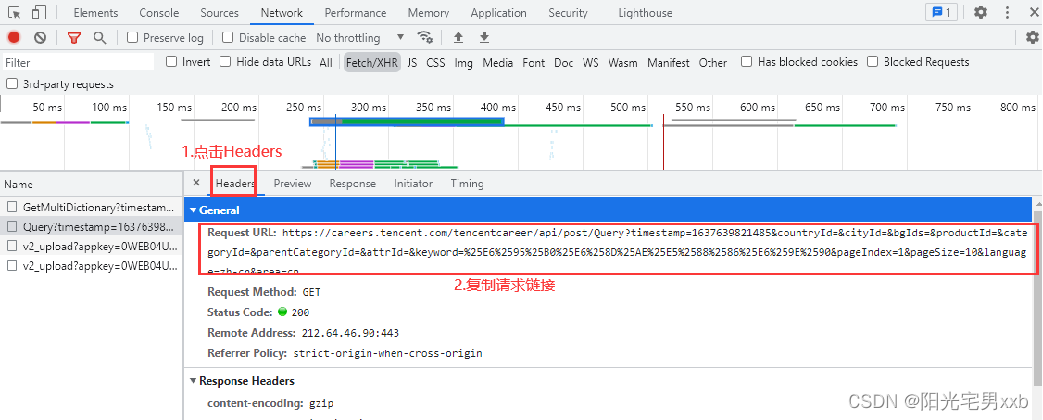
7.找到想要的请求链接后,点击Headers,复制请求链接:
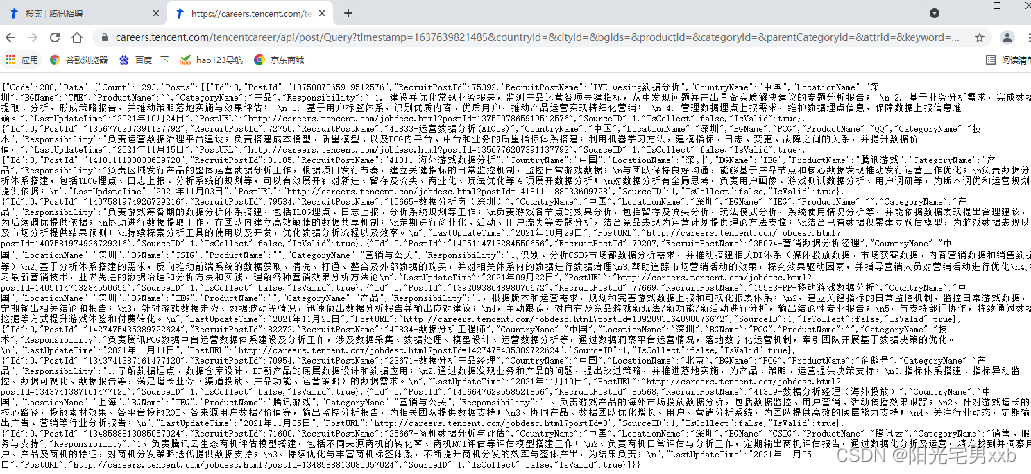
8.把请求链接复制到浏览器上打开,可以看到是json格式的,分析链接中的参数:
9.一般可以通过参数名称推断出各个参数的含义,或者通过修改相应的参数值,删除个别参数等方式查看数据的变化,结合原网页上的数据,通过对比来推测参数的含义,如:我们推测pageSize应该为获取的数据量大小,我们尝试将它的值修改为5,然后对比下数据变化和原网页上的数据。
10.pageSize修改为5后,可观察到,获取了前5条数据,因此可确定pageSize为每次获取的数据条数。
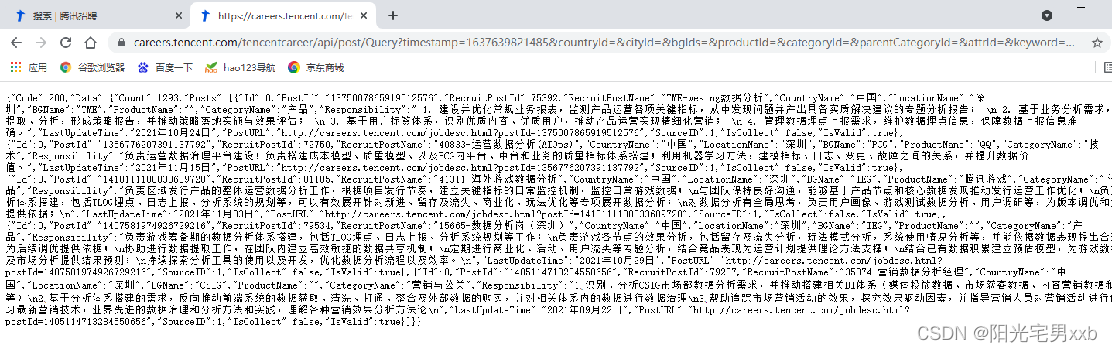
11.通过上述方法依次确定pageIndex是当前的页码数,keyword是是查询的关键词,pageSize是每次获取的数据量大小,pageIndex是页码。
12.参数确定后,我们只要修改相应的参数就能够爬取到所有的招聘数据了。
接下来就可以编写爬取程序,对数据进行获取和解析了。
#根据返回的json中的数据结构,提取想要的数据jobs = json_data['Data']['Posts'] #经过分析,所有的数据都在Data下的Posts数组中for job in jobs:try:name = job["RecruitPostName"] #岗位名称Location = job["LocationName"]#工作地点work = job["Responsibility"].replace("\r\n","").replace("\n","") # 去除换行符 #工作内容update = job["LastUpdateTime"] #更新时间postUrl = job["PostURL"] #详情页网址#输出解析到的电影信息print(name,Location,work,update,postUrl)except:print(job)#万一解析出错,则输出电影信息,以便于检查是否是程序问题
如果要实现多页爬取,或者更换招聘的关键词,那么就可以通过循环,不断变换请求url中的pageIndex的值以及keyword值。
完整的程序代码,可以在评论区留言或私信:
: https://download.csdn.net/download/c1007857613/87370864
总结
本节主要介绍了python网络爬虫如何解析json数据,通过爬取腾讯招聘网的数据示例掌握json数据的解析,加深对爬虫从分析到爬取再到解析这个过程的理解
如对本章节有疑问,或者需要相应的学习资料的,欢迎评论留言!!!
【前一篇】:python网络爬虫—快速入门(理论+实战)(六)