单目3D目标检测[基于深度辅助篇]
基于深度辅助的方法
1. Pseudo-LiDAR
- Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving
- 康奈尔大学
- https://zhuanlan.zhihu.com/p/52803631

- 首先利用DRON或PSMNET从单目 (Monocular)或双目 (Stereo)图像获取对应的深度图像(depth map),然后将原图像结合深度信息得到伪雷达点云 (pseudo-LiDAR),最后用pseudo-LiDAR代替原始雷达点云,以3D point cloud和bird’s eye view的形式
- 图像对physically incoheren不友好;深度图对不同尺寸物体检测不友好:所以用伪点云
- pseudo-Lidar > FV+depth map
- 1.Image-based 3D Perception方案较差的性能:主要是由于front view这种2D图形表示,而不是之前一直纠结的不准确的depth map
- 2.雷达的优势:在三维点云中(或BEV), 卷积和池化操作的区域都是physical nearby, 不同位置的不同物体并不会混为一谈;其次,物体的尺度具备深度不变性,保持了三维空间中最原始的尺度。
- 未来工作:融合LiDAR 和 pseudo-LiDAR可能更好
- 雷达点云虽然精确并有反射强度信息,但是非常稀疏
- pseudo-LiDAR虽然不是特别精确,但是比雷达点云要密集的多,且具备RGB颜色信息
- 比传统融合Lidar和RGB(MV3D, AVOD)更好
2. PatchNet
-
Rethinking Pseudo-LiDAR Representation
-
商汤 ECCV2020
-
https://github.com/xinzhuma/patchnet.git
-
https://arxiv.org/pdf/2008.04582.pdf
-
https://blog.csdn.net/qq_16137569/article/details/123769737
-
PatchNet-vanilla
- Step1:深度估计 给定一张单目图像或双目图像对,使用独立的模型预测每个像素( u , v ) (u,v)(u,v)对应的深度值d dd。
- Step2:2D检测 使用另一个CNN生成2D目标的区域提议。
- Step3:3D数据生成 根据Step2生成的区域提议将感兴趣区域从Step1生成的深度图中抠下来,然后利用相机内参将深度值转化为3D世界坐标( x , y , z ) (x,y,z)(x,y,z)。
- Step4:3D目标检测 将Step3生成的伪点云视为激光信号,并使用PointNet预测结果。PointNet将点云视为无序点集,并通过一个集合函数f ff将点集映射到输出向量
-
PatchNet-vanilla
- 前三步和pseudo-LiDAR完全一样,第四步会有所差别。PatchNet-vanilla将M个3D点重构成N×N×3的图像块,作为PatchNet-vanilla的输入,然后可以使用一个1 × 1 1\times 11×1接收域的2D卷积层以及一个全局最大池化来实现

- 前三步和pseudo-LiDAR完全一样,第四步会有所差别。PatchNet-vanilla将M个3D点重构成N×N×3的图像块,作为PatchNet-vanilla的输入,然后可以使用一个1 × 1 1\times 11×1接收域的2D卷积层以及一个全局最大池化来实现
-
PatchNet-vanilla获得了和pseudo-LiDAR几乎一样的性能,这也证明了伪点云的数据表征形式不是必要的。
-
PatchNet-vanilla和PatchNet-AM3D,可以看到两种方法在替换数据表征方式后的性能都基本持平。说明数据表征不是影响3D检测性能的关键因素。
-
PatchNet:
- 首先训练两个CNN分别用于预测2D框和深度图,对于每个检测到的2D目标框,从深度图中抠出对应的区域,利用相机内参将深度值转换成3D空间坐标(得到Fig.3中的cropped patches)。紧接着用一个主干CNN提取这些ROI的深层特征,然后使用mask global pooling分离出前景目标特征,最后通过一个检测头来进行回归目标的3D框(x ,y ,z ,h ,w ,l ,θ )
- mask global pooling是论文提出了一种增强版global pooling方式,利用一个二值掩模(通过卡阈值的方式从深度图中获得)只对前景目标的特征进行global pooling操作,以获得更加鲁棒的特征。
3. MonoRCNN
4. D4LCN
5. CaDDN
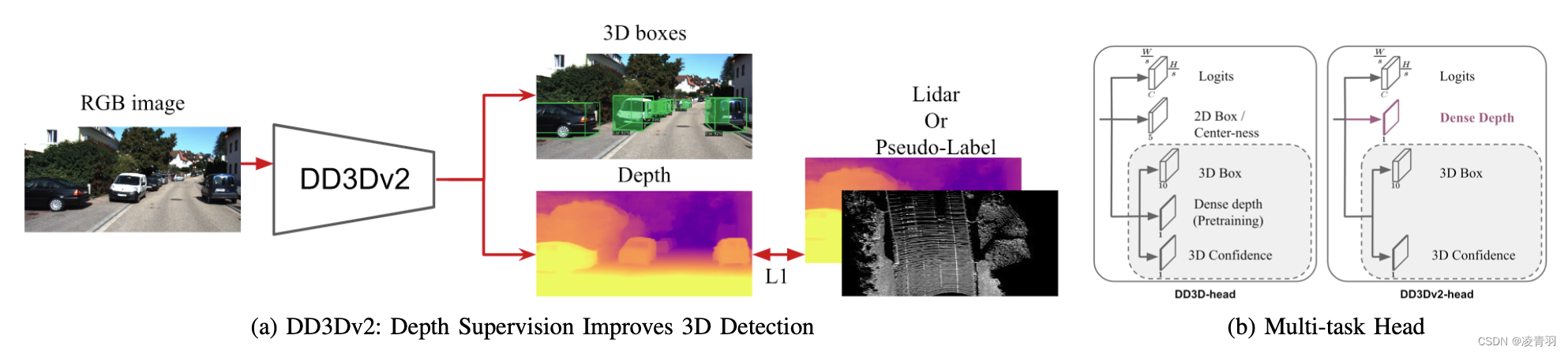
6. DD3D

- DD3D
a. 对于DD3D,以DLA-34作为backbone,按照论文中提出的实验流程训练(coco pretrain->DDAD15M pretrain->3D detection),在KITTI-3D验证集上测试得到的Car-BEV-AP分别是33.5(Easy),26.0(Mod),22.6(Hard) - PL
a. DDAD15M pretrain->KITTI-Depth finetune->pseudo-lidar based 3D detection)
7. DD3Dv2