Simple RNN、LSTM、GRU序列模型原理
一。循环神经网络RNN
用于处理序列数据的神经网络就叫循环神经网络。序列数据说直白点就是随时间变化的数据,循环神经网络它能够根据这种数据推出下文结果。RNN是通过嵌含前一时刻的状态信息实行训练的。 RNN神经网络有3个变种,分别为Simple RNN、LSTM、GRU。


1)Simple RNN:短期记忆
Simple RNN是将上一次输出状态与这一次的输入拼接起来进行下一次训练,一直这样下去。Simple RNN只适合短期记忆,也就是Simple RNN输入的序列不能太长,这是由于随着网络层数增加梯度消失导致的,说直白点就是Simple RNN会丢失前一部分的信息。


"""Simple RNN实现IMDB电影评论分类
实现:
1.加载数据、数据预处理
2.补白
3.搭建RNN模型
4.训练、评估
"""
"""
1.加载数据、数据预处理
①加载数据:得到训练集、测试集
"""
vocabulary = 10000#设置评论常用词汇10000个单词
start_char = 1#一句话的开始
oov_char = 2#不在10000个词中的单词用OOV表示
index_from = 3#从3开始算一句话开始
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=vocabulary,start_char=start_char, oov_char=oov_char, index_from=index_from)#得到训练集与测试集
"""
②数据预处理:第1步,x_train是值,找不到键,必须将x_train变为键;第2步,由键找到单词
"""
word_index = imdb.get_word_index()#加载大词典
inverted_word_index = dict([(i + index_from, word) for (word, i) in word_index.items()])# 将大词典键与值互换位置
#正式转换数据
inverted_word_index[start_char] = "[START]"
inverted_word_index[oov_char] = "[OOV]"
# " ".join(inverted_word_index[i] for i in x_train[0])#打印第一句话
"""
2.补白:避免句子长短不一
"""
word_num = 250
x_train = pad_sequences(x_train, maxlen=word_num)
x_test = pad_sequences(x_test, maxlen=word_num)
x_train.shape
"""
3.搭建RNN模型
"""
embed_dim = 32
state_dim = 32
rnn = Sequential([Embedding(input_dim=vocabulary,output_dim=embed_dim,input_length=word_num),#Embedding的作用是降维,每次输入input_length=250词每次,将每个词拉成output_dim=32,最终高250变成了32达到了降维。一共有10000词等输入SimpleRNN(state_dim, return_sequences=False),#输出的状态向量为state_dim,return_sequences=False表示只需要最后一个状态向量Dense(1,activation='sigmoid')#Dense表示全连接层,1表示结果输出一个数就可以,activation='sigmoid'表示激活函数为sigmoid
])
"""
4.训练、评估
"""
①训练
rnn.compile(loss="binary_crossentropy",optimizer="rmsprop",metrics=["accuracy"])#loss损失函数用交叉熵表示,optimizer优化器,metrics准确率
rnn.fit(x_train, y_train,batch_size=128,epochs=5,validation_data=(x_test, y_test))#训练,validation_data为测试集
"""
②评估
"""
score, acc = rnn.evaluate(x_test, y_test, batch_size=128)2) LSTM:长短期记忆
Simple RNN的缺点是随着序列的增长会丢失一部分前面的信息,而LSTM为了弥补这一缺陷,加入了传输带①,能够在一定程度上缓解前面序列信息的遗忘,LSTM大致可以分为5个部分,介绍如下:

①传输带:记为向量C,过去的信息就是通过这个传输带送到下一时刻,它不会损失太多信息,就是通过这条传送带来避免梯度消失的问题;
②遗忘门:门是用来控制是否让信息通过的,遗忘门顾名思义就是让一部分信息通过,一部分信息不通过。





③输入门④新值同理操作,处理完更新传输带





还是以电影分类为例,只需将
SimpleRNN(state_dim, return_sequences=False)改为
LSTM(state_dim, return_sequences=False)即可。
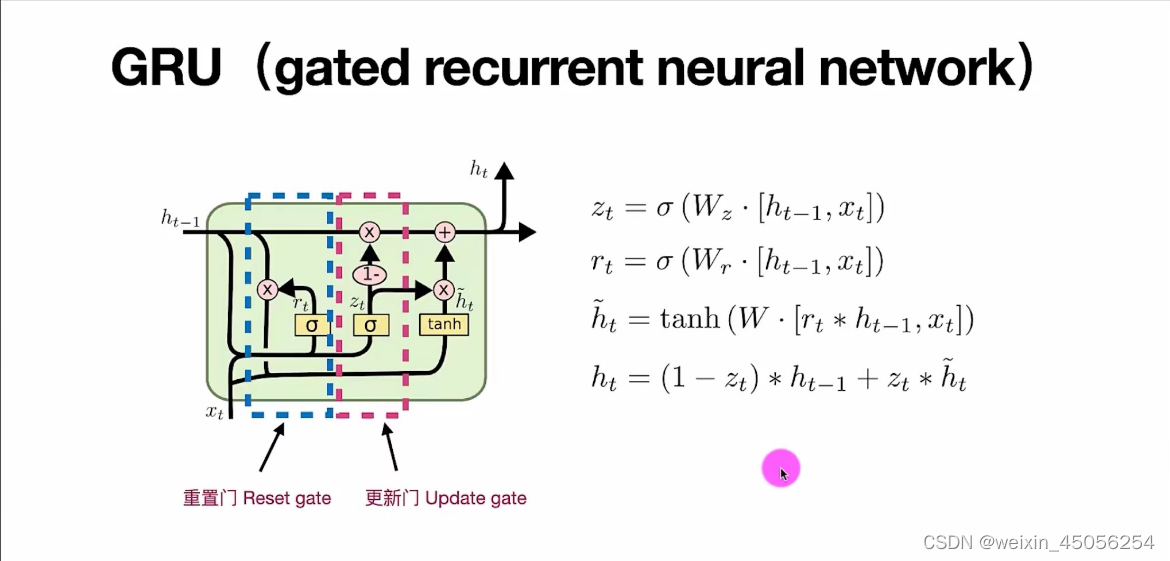
3)GRU:
图解如下: