软件测试肖sir__python之ui自动化定位方法(2)
Selenium中元素定位方法
一、定位方法
要实现UI自动化,就必须学会定位web页面元素,Selenium核心
webdriver模块提供了9种定位元素方法:
定位方式 提供方法
id定位 find_element_by_id()
name定位 find_element_by_name()
class定位 find_element_by_class_name()
link定位 find_element_by_link_text()
partial link定位 find_element_by_partial_link_text()
JavaScript定位 document.getElementById(“kw”).value=“duoceshi”
tag定位 find_element_by_tag_name()
xpath定位 find_element_by_xpath()
css定位 find_element_by_css_selector()
二、定位方法详解
1、准备工作
网站:https://www.baidu.com/
打开页面元素:
方法:f12+fn 或f12 或者右键更多工具=开发者工具

元素:
百度中输入框的元素
案例
1、id定位 find_element_by_id()
send_keys(“”)输入内容
案例:
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_id('kw').send_keys("dcs") #id定位
sleep(5)
dx.close()
2、name定位 find_element_by_name()
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_name('wd').send_keys('我是name定位')
sleep(5)
dx.close()
3、class定位 find_element_by_class_name()
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_class_name("s_ipt").send_keys('我是class定位')
sleep(5)
dx.close()
4、link定位 find_element_by_link_text()
click()点击
针对a标签

from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_link_text("hao123").click()
sleep(5)
dx.close()5、partial link定位 find_element_by_partial_link_text() 模糊定位
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_partial_link_text("hao").click()
sleep(5)
dx.close()
6、JavaScript定位 document.getElementById(“kw”).value=“duoceshi”
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
js='document.getElementById("kw").value="js方法"'
dx.execute_script(js)
sleep(5)
dx.close()7、tag定位 find_element_by_tag_name()
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
inputs=dx.find_elements_by_tag_name('input')
for i in inputs:#遍历所有input标签if i.get_attribute("name")=='wd':i.send_keys("tagname定位方法")
sleep(5)
dx.close()
8、xpath定位 find_element_by_xpath()
(1)讲解xpath 路径定位方法
案例: 复制 :xpath://*[@id=“kw”]
复制 :full xpath :/html/body/div[2]/div[1]/div[5]/div/div/form/span[1]/input
xpath路径定位详解:
a.绝对路径
特点:
(1)以/ 开头,
(2)从页面根元素开始
如下图:
/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input
html标签,开始,严格按照元素在html页面中的位置和顺序向下查找
b.相对路径
特点:
a.以双斜杠//开头;
b. 不考虑元素在页面中的绝对路径和位置,只考虑是否存在符合表达式的元素即可。
c.使用标签名+节点属性定位
语法://标签名【@属性名=属性值】
//表示相对路径,从匹配选择的当前节点存在文档中的节点,而不靠考虑他们的位置
. 选取当前节点
…选取当前节点的父节点
。匹配任何元素的节点
@* 匹配任何元素节点
@选取属性
如:
//[@id=“form”]
//[@id=“result_logo”]
(1)选定标签=右键=copy xpath
(2)复制的xpath://*[@id=“kw”]
(一)xpath中的id地位
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_xpath('//*[@id="kw"]').send_keys("xpath中id定位")
sleep(5)
dx.close()
(二)xpath中的拿name定位
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_xpath('//*[@name="wd"]').send_keys("xpath中name定位")
sleep(5)
dx.close()(三)xpath中的class定位
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_xpath('//*[@class="s_ipt"]').send_keys("xpath中class定位")
sleep(5)
dx.close()
(四)xpath中的其他元素定位
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_xpath('//*[@autocomplete="off"]').send_keys("xpath中其他元素定位")
sleep(5)
dx.close()
(五)xpath中的其他组合元素定位(and)
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_xpath('//*[@autocomplete="off" and @class="s_ipt"]').send_keys("xpath中组合元素定位")
sleep(5)
dx.close()
(六)xpath中的层级定位
定义:找上一级定位或上上级定位
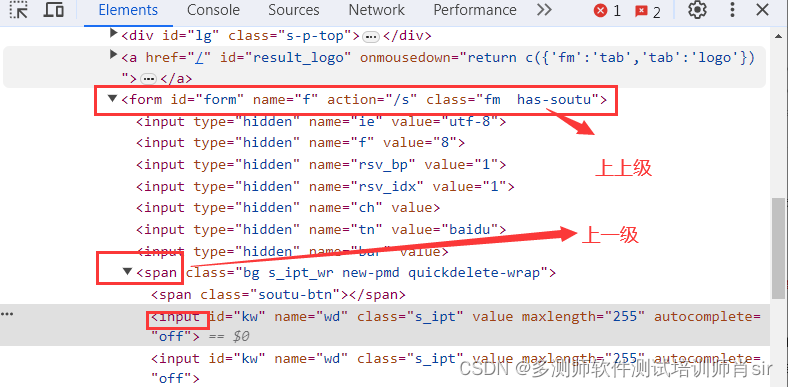
上上级xpath://[@id=“form”]
上一级xpath://[@id=“form”]/span[1]
输入框的xpath定位:
//[@id=“kw”]
或
//[@id=“form”]/span[1]/input[1]
或
//*[@id=“form”]/span/input
上一级定位:
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_xpath('//*[@id="form"]/span[1]/input[1]').send_keys("上级定位")
sleep(5)
dx.close()
上上级定位:
from selenium import webdriver
from time import sleep
dx=webdriver.Chrome()
dx.get('https://www.baidu.com/')
sleep(2)
dx.maximize_window()
sleep(2)
dx.find_element_by_xpath('//*[@id="form"]/span/input').send_keys("上上级定位")
sleep(5)
dx.close()