2.3 如何使用FlinkSQL读取写入到JDBC(MySQL)
1、JDBC SQL 连接器
FlinkSQL允许使用 JDBC连接器,向任意类型的关系型数据库读取或者写入数据
添加Maven依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version>
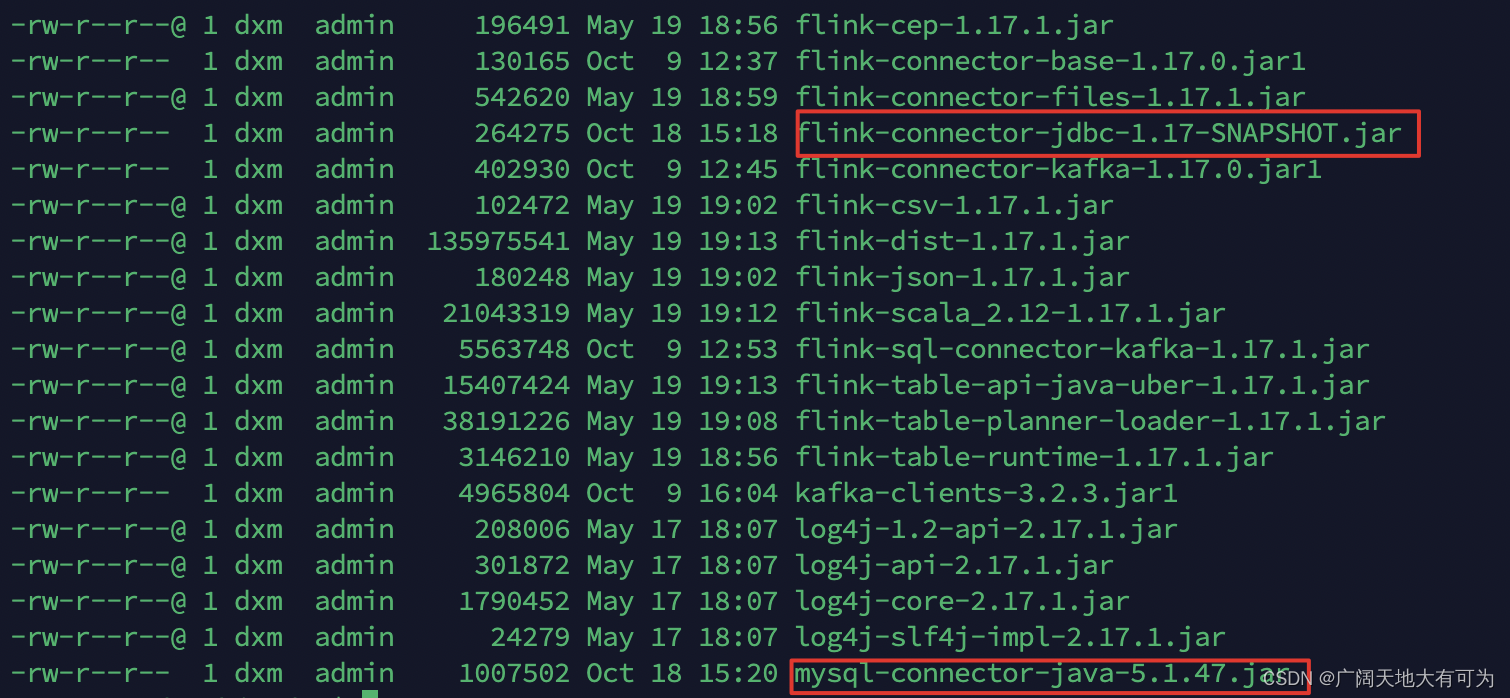
</dependency>注意:如果使用 sql-client客户端,需保证 flink-1.17.1/lib 目录下 存在相应的jar包
相关jar可以通过官网下载:JDBC SQL 连接器
2、读取 MySQL
FlinkSQL读取MySQL表时,为批式处理,在流式计算任务中,通常被做维表来使用
-- 在FlinkSQL中创建 MySQL Source 表
drop table mysql_source_table;
CREATE TABLE mysql_source_table (`id` INT,`title` STRING,`author` STRING,`price` DOUBLE,`qty` INT
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://worker01/flink','driver' = 'com.mysql.jdbc.Driver', -- 【可选】不设置时,将自动从url中推导'username' = 'xxxx','password' = 'xxxx','table-name' = 'books'
);-- 批式 sql,查看 JDBC 表中的数据
select * from mysql_source_table;运行结果:

3、写入MySQL
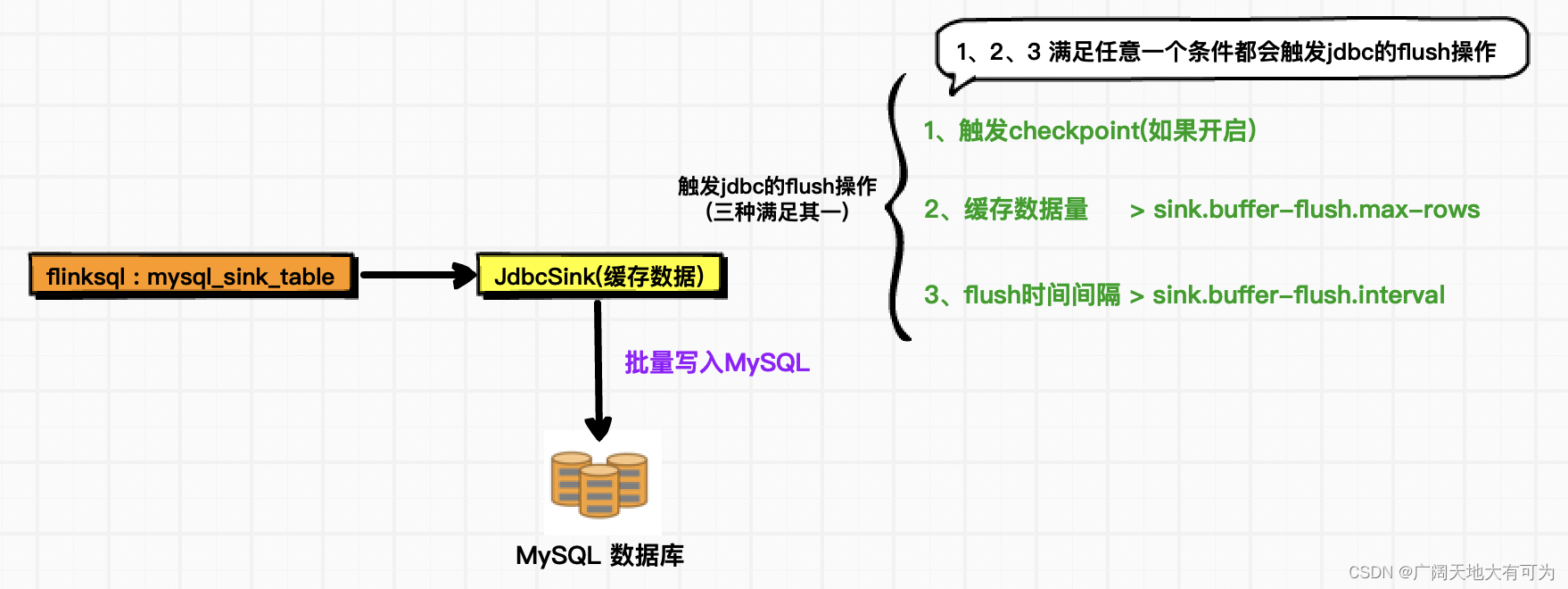
3.1 何时批量写入MySQL呢?
FlinkSQL往MySQL写入数据时,默认会在客户端缓存数据,当触发设置的阈值后,才会向服务端发送数据
开启checkpoint :
# TODO 开启checkpoint,当checkpoint后,会触发jdbc的flush操作
set execution.checkpointing.interval=300sec;设置 flush 前缓存记录的最大值 、flush 间隔时间:
-- TODO 创建sink mysql table
drop table mysql_sink_table;
CREATE TABLE mysql_sink_table (`id` INT,`title` STRING,`author` STRING,`price` DOUBLE,`qty` INT
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://worker01:3306/flink?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8','username' = 'xxxx','password' = 'xxxx','table-name' = 'books','sink.buffer-flush.max-rows' = '100', -- flush 前缓存记录的最大值,默认值为100,设置为0时,表示不缓存数据(来一条写入一条)'sink.buffer-flush.interval' = '50s' -- flush 间隔时间,超过该时间后异步线程将 flush 数据。默认为1s
);使用说明:
FLinkSQL写入MySQL时,常通过 sink.buffer-flush.max-rows、sink.buffer-flush.interval 来控制写入数据的延迟程度
当 对写入实时性要求较高时,可以将 sink.buffer-flush.max-rows = 0 ,表示到来一条数据后立即写入MySQL,但带来的后果是 长时间占有mysql连接
当 数据量大且对实时要求不高时,可根据业务需求调大配置,可使实时行和性能最优
3.2 sink mysql table 中主键的作用
在FLinkSQL中创建sink mysql table时,如果表中定义了主键,则连接器将以 upsert 模式工作
否则连接器将以 append 模式工作
upsert 模式:Flink 将根据主键判断插入新行或者更新已存在的行
使用这种模式时,确保MySQL中的底表定义主键和添加唯一性约束
append 模式:对MySQL库中底表做insert操作
upsert 模式:
-- TODO 创建MySQL 表
CREATE TABLE `books` (`id` int(11) NOT NULL,`title` varchar(99) DEFAULT NULL,`author` varchar(99) DEFAULT NULL,`price` double DEFAULT NULL,`qty` int(11) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- TODO 创建FLinkSQL表(sink mysql table)
drop table mysql_sink_table;
CREATE TABLE mysql_sink_table (`id` INT,`title` STRING,`author` STRING,`price` DOUBLE,`qty` INT,PRIMARY KEY (id) NOT ENFORCED -- 指定主键字段
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://worker01:3306/flink?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8','username' = 'root','password' = 'xxxx','table-name' = 'books','sink.buffer-flush.max-rows' = '0' -- 实时写入
);-- TODO 往 mysql中写入数据(相同key的数据写入后,会做upsert操作)
insert into mysql_sink_table
SELECT * FROM (VALUES(5,'A Dream in Red Mansions','y', 3.0,1)
, (6,'Journey to the West','y', 3.0,1)
, (7,'Water Margin','y', 3.0,1)
) AS books (id, title,author,price,qty);append 模式:
-- TODO 创建FLinkSQL表(sink mysql table)
drop table mysql_sink_table;
CREATE TABLE mysql_sink_table (`id` INT,`title` STRING,`author` STRING,`price` DOUBLE,`qty` INT
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://worker01:3306/flink?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8','username' = 'root','password' = 'xxx','table-name' = 'books','sink.buffer-flush.max-rows' = '0' -- 实时写入
);-- TODO 往 mysql中写入数据(相同key的数据写入后,会做操作)
insert into mysql_sink_table
SELECT * FROM (VALUES(5,'A Dream in Red Mansions','y', 3.0,1)
, (6,'Journey to the West','y', 3.0,1)
, (7,'Water Margin','y', 3.0,1)
) AS books (id, title,author,price,qty);注意:使用 append模式时,如果MySQL底表中存在主键或唯一性约束时,INSERT 插入可能会失败
insert into 失败:
