Flink日志收集到数据库/kafka
引言
我们做项目过程中发现flink日志不同模式启动,存放位置不同,查找任务日志很不方便,具体问题如下:
- 原始flink的日志配置文件log4j-cli.properties
appender.file.append = false,取消追加,直接覆盖掉上一次提交任务的信息。这里改为true解决。 - application模式启动任务失败/取消后,无法找到错误日志,需要用命令查找对应appId
yarn application -appId <Application ID> - flink session模式重启集群,导致之前提交任务信息全部删除,开启历史服务器:
historyserver.archive.fs.dir: hdfs:///completed-jobs/,其他配置参考官方文档
这些问题虽然都找到了对应的解决办法,但是仍然很不方便。所有我决定研究flink的log配置文件,将所有log写入数据库/kafka中。
在查找资料中发现log4j2配置都是xml方式,而flink是以properties的配置方式,网上也没有properties方式配置JDBCAppender的资料。注:log4j2在低版本是不支持properties的
log4j2.properties写数据库
先看官网,这里介绍了flink conf目录下的每个配置文件的作用,这里我们针对log4j2修改,logback 这里没有涉及,可以自行查看官网配置。
我们准备收集到所有相关日志,所以这四个文件都需要配置JDBCAppender。

我这里是连接的是mysql,将mysql-connector-java-8.0.28.jar放在lib目录下,
官方支持一下四种模式,以DriverManager为示例

rootLogger.appenderRef.jdbc.ref=JDBCAppender
appender.jdbc.name=JDBCAppender
appender.jdbc.type=JDBC
appender.jdbc.tableName=flink_logs
appender.jdbc.connectionSource.type=DriverManager
appender.jdbc.connectionSource.connectionString=jdbc:mysql://ip:port/database
appender.jdbc.connectionSource.userName=root
appender.jdbc.connectionSource.password=root
appender.jdbc.columnConfigs1.type=Column
appender.jdbc.columnConfigs1.name=source
appender.jdbc.columnConfigs1.pattern=%c
appender.jdbc.columnConfigs2.type=Column
appender.jdbc.columnConfigs2.name=type
appender.jdbc.columnConfigs2.pattern=%p
appender.jdbc.columnConfigs3.type=Column
appender.jdbc.columnConfigs3.name=create_time
appender.jdbc.columnConfigs3.pattern=%d{yyyy-MM-dd HH:mm:ss,SSS}
appender.jdbc.columnConfigs4.type=Column
appender.jdbc.columnConfigs4.name=massage
appender.jdbc.columnConfigs4.pattern=%m %throwable
JDBCAppender更多详细配置
log4j2.properties写kafka
将kafka-client.jar放在lib目录下,
官方具体配置说明:
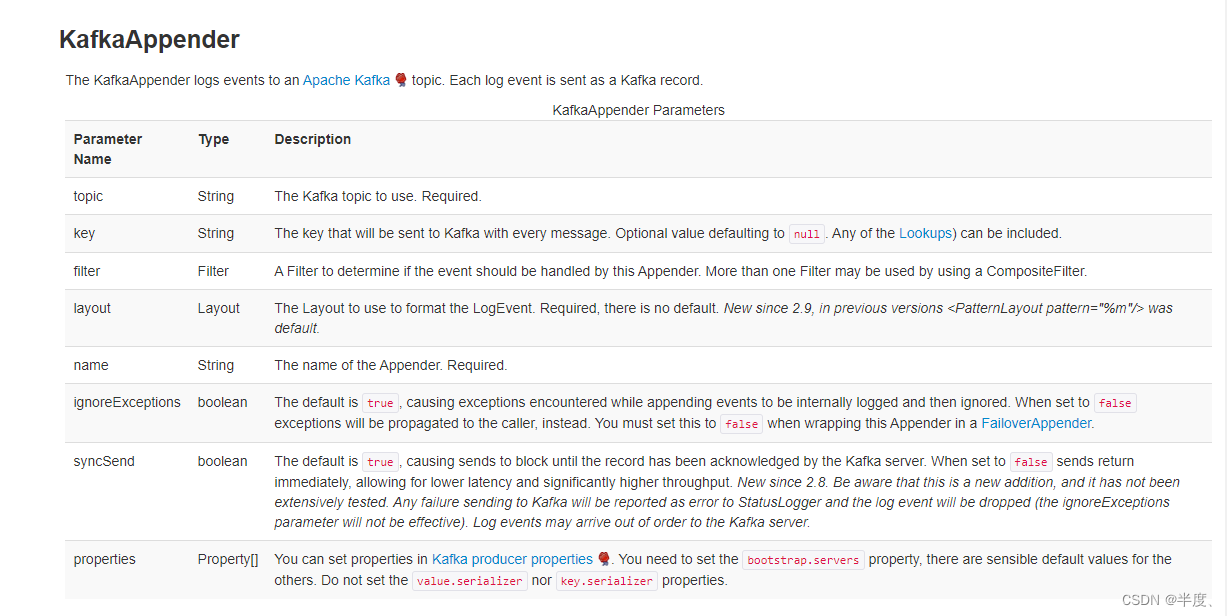
rootLogger.appenderRef.kafka.ref=KafkaAppender
appender.kafka.name=KafkaAppender
appender.kafka.type=Kafka
appender.kafka.syncSend=true
appender.kafka.ignoreExceptions=false
appender.kafka.topic=flink_log_test
appender.kafka.property.type=Property
appender.kafka.property.name=bootstrap.servers
appender.kafka.property.value=ip:9092
appender.kafka.layout.type = PatternLayout
appender.kafka.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
进阶
完成以上操作我们已经可以将日志写入mysql/kafka中了,但是我发现所有日志写入后,无法区分集群,任务分别是那些了,当然可以在配置中每一个配置文件写入不同的表,但是job任务如何区分呢?
我们可以设置环境变量或系统环境变量,让log4j从中获取自定义值
更详细内容参考官方地址
