Flash-Attention
这是一篇硬核的优化Transformer的工作。众所周知,Transformer模型的计算量和储存复杂度是 O ( N 2 ) O(N^2) O(N2) 。尽管先前有了大量的优化工作,比如LongFormer、Sparse Transformer、Reformer等等,一定程度上减轻了Transformer的资源消耗,但对Transformer的性能有所折损,且扩展性不强,不能泛化到其它领域、以及复杂结构的叠加。
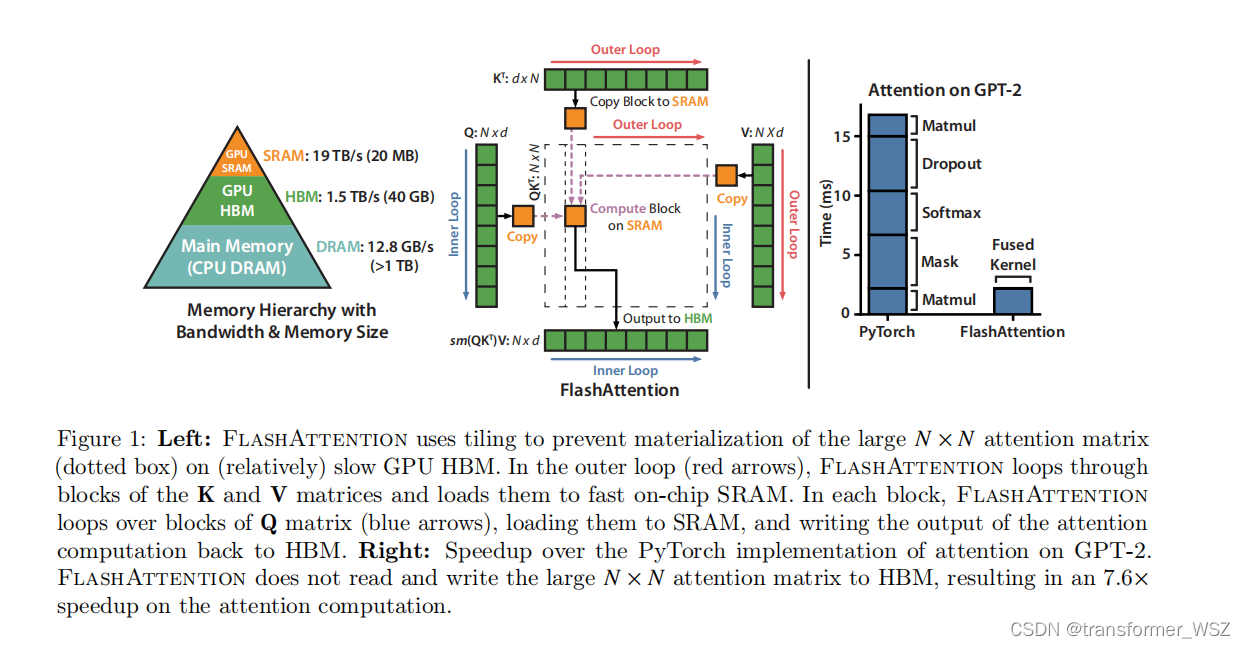
这篇工作从底层对Transformer的计算和读写进行了优化,主要有三个贡献:
- 加速了模型计算:现在GPU的计算速度已经远远超过了内存读写速度,当GPU完成计算后,内存确还在读取数据,造成GPU闲置而内存繁忙读(消费者早就消费完了,生产者还在缓慢生产)的现象,也就是内存墙问题。FlashAttention通过tiling和算子融合计算,将复杂操作放到SRAM中计算,并减少从HBM读取次数,加快了模型计算速度。而之前的工作虽然减少了Transformer的计算复杂度,却并没有减少模型计算时间。
- 节省了显存:FlashAttention通过引入全局统计量,避免实例化大注意力矩阵,减少了显存占用。
- 精确注意力:FlashAttention从底层优化了Transformer的计算,但是任务指标上没有任何折损,与普通的Transformer结果是完全等价。
现代GPU内存分级
参考
- FlashAttention:加速计算,节省显存, IO感知的精确注意力