Ceph 中的写入放大

新钛云服已累计为您分享769篇技术干货


介绍

Ceph 是一个开源的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。 Ceph 独一无二地在一个统一的系统中同时提供了对象、块、和文件存储功能。 Ceph 消除了对系统单一中心节点的依赖,实现了无中心结构的设计思想。
我们知道Ceph为了保障数据的可靠性,存放数据通常是三副本策略(另有EC策略)。那么无论是data,metadata,journal都是三份。因此在应用端写入一个IO,在ceph内部实际上会额外产生许多内部IO,不同的存储后端差异很大。 Ceph提供了FileStore、KStore和BlueStore三种存储后端以供选择,那么以FileStore为例,来看看13X的写放大的来由。FileStore中ceph的数据被存放在XFS或者ZFS等本地文件系统中。这些文件系统本身又会记录日志(FS journal),以及还有它自己的元数据(FS metadata)。
在设计存储基础结构时,为了防止故障,保证一定的冗余度是非常有必要的。但是,冗余伴随着存储效率的降低,这也会增加您的成本。对于大型基础设施,每 TB 成本的差异可能会导致总存储成本显著提高。因此,Ceph 中的纠删码非常有吸引力。 纠删码类似于基于奇偶校验的 RAID 阵列。为每个对象创建许多数据块 (K) 和奇偶校验块 (M)。另一方面,副本只是创建给定对象的其他副本,类似于镜像 RAID 阵列。这通常意味着纠删码比副本具有更高的存储效率,计算公式为 k/(k+m)。 例如,以 6+2 为例,您将获得 75% 的存储效率——在记录的总 8 个区块中,有 6 个数据块。与三个副本相比,您将有 33% 的效率,总共 3 个记录的块中有 1 个数据块。

写入放大
正常来说,Ceph 都没啥问题,除了一个经常被忽视的问题:写入放大。 数据存储中的最小分配大小本质上是一段数据可以写入的最小单位。在 Pacific Ceph 之前,此值默认为 64kb。此最小分配单元会给某些工作负载带来问题,尤其是那些对小文件进行操作的工作负载。

案例
4% 存储效率示例如下图:
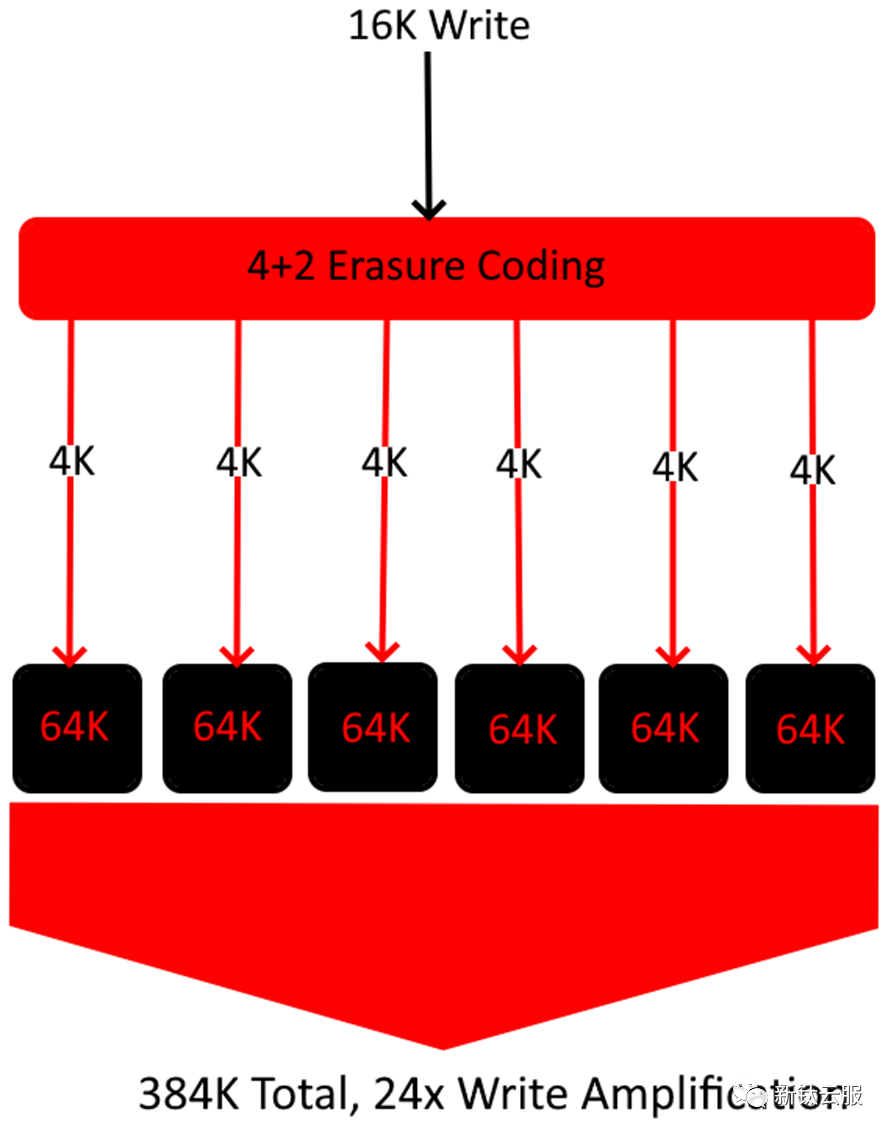
为了更直观一点,让我们考虑一个传入写入为 16kb 的 4+2 纠删码池。 在上面的示例中,单个 16K 写入最终会放大 24 倍的大小,因为每个块至少需要以 64K 的速度写入磁盘。这导致此特定对象的总存储效率为 ~4%。如果您的工作负载主要由 16K 对象组成,那么这可能会很快抵消您的 EC 配置文件提供的任何优势。下面是使用相同文件大小的 3 副本示例。
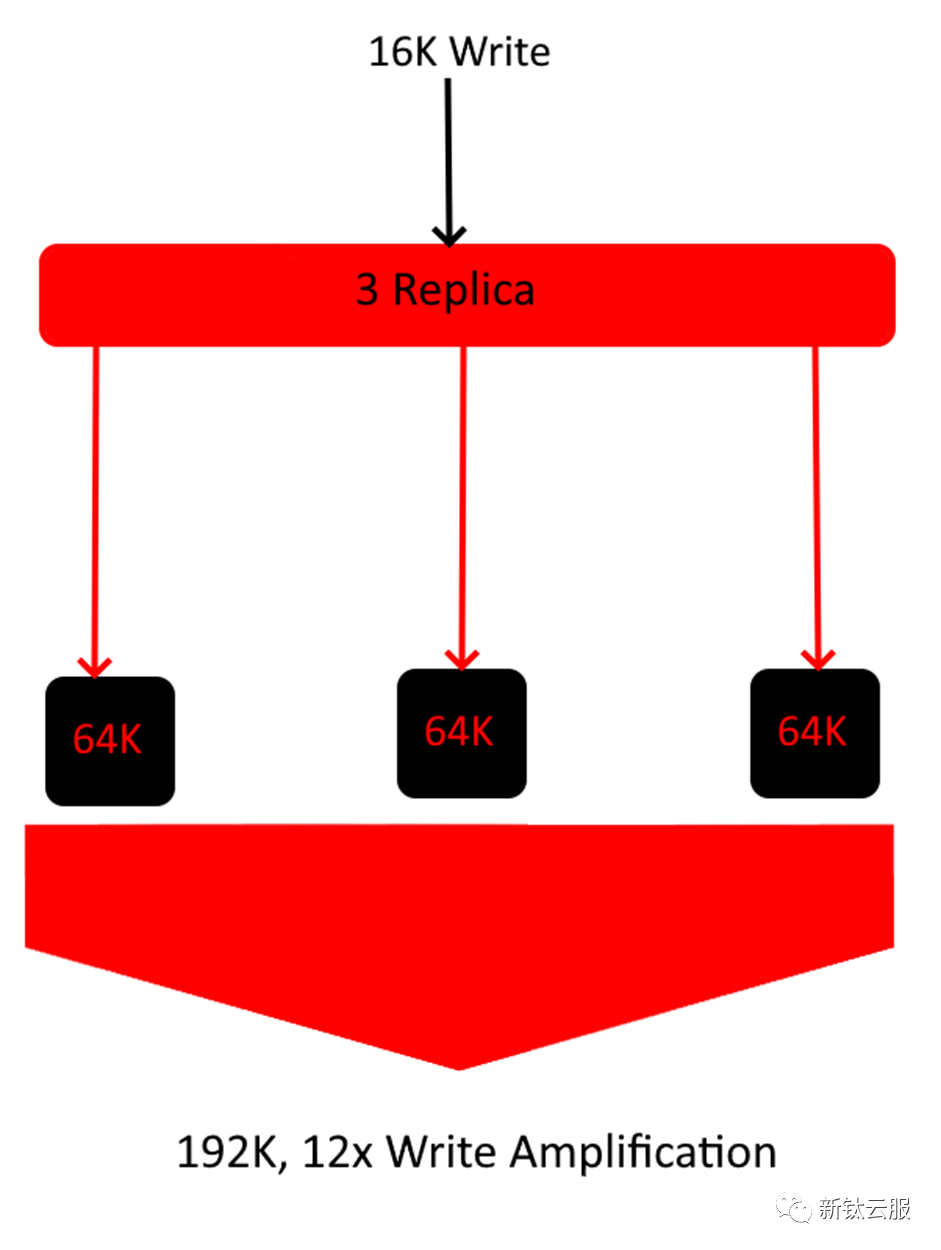
如上图所示,在此特定工作负载中,3 Replica 实际上比 4+2 纠删码池的存储效率更高。这表明规则总是有例外。从理论上讲,当存储效率是最高优先级时,应使用纠删码,但根据您的数据集,这可能会发生巨大变化。

写入放大重要的用例
当然,即使按照小文件工作负载标准,16K 文件也很小,单单一篇文章的大小就 100K 左右。另外,一些可能存在写入放大问题的场景是:
AI training 人工智能训练
audio editing 音频编辑
log storing/aggregation 日志存储/聚合
scientific computing 科学计算

结论
了解数据和工作负载是确定 Ceph 集群构建的关键部分。了解整个数据的平均文件大小将使您能够避免这种极高的写入放大。 当然,这并不总是这样的。通常,在单个集群中往往会存在各种大小的文件。在这种情况下,只需确定数据的位置即可。例如,如果单个目录树拥有大部分小文件,则可以将副本池固定到该特定树,而具有较大文件大小的其余数据仍保留在纠删码上。 如前所述,当您的最小分配大小太大时,写入放大会更加普遍,这就是为什么较新版本的 Ceph(如 Pacific 和 Quincy)默认为 4K 而不是 64K 的原因。在较新的集群或最小分配大小修改的 Octopus 集群中,写入放大的问题要小得多,因此,我们在后续的集群部署前,需要认真考虑一下。
推荐阅读


推荐视频