【虹科干货】Redis Enterprise 自动分层技术:大数据集高性能解决方案
越来越多的应用程序依赖于庞大的数据集合,而这些应用程序必须快速响应。借助自动分层,Redis Enterprise 7.2 帮助开发人员轻松创建超快的应用程序。何乐而不为?
Redis将数据存储在内存中,因此应用程序能以最快的速度检索和处理数据。然而,随着应用程序需要处理的数据越多,存储数据集所需的内存越大,所耗费的成本则更高,Redis Enterprise自动分层技术能很好地化解这个两难的局面。
一、问题:内存有限且昂贵
当应用程序访问的数据量很大,例如达到TB级时,开发人员就面临着内存有限的问题,他们一般使用基于磁盘的解决方案来在幕后支持 Redis。这样一来,开发人员就不得不在应用程序中构建整个数据管理系统,这意味着他们要把时间花在不相干的任务上。
利用 Redis Enterprise 的自动分层功能 ,开发人员可以使用固态硬盘(SSD)作为可用内存的一部分,将大容量数据库扩展到SSD中。Redis Enterprise 可以随时识别哪些数据应留在内存中,哪些数据应留在固态硬盘上,从而将吞吐量提高一倍,并将延迟减半。
因此,开发人员无需编写额外的代码或学习其他新技术。通过将动态 RAM 与高速外部存储相结合,Redis Enterprise 可以轻松高效地使用系统资源,同时还能快速访问热数据。
二、自动分层的工作原理
自动分层可自动管理数据。它会将热数据转移到 DRAM,并智能地将未使用的数据转移到 SSD。这为依赖大型数据集的应用带来了新的可能性。
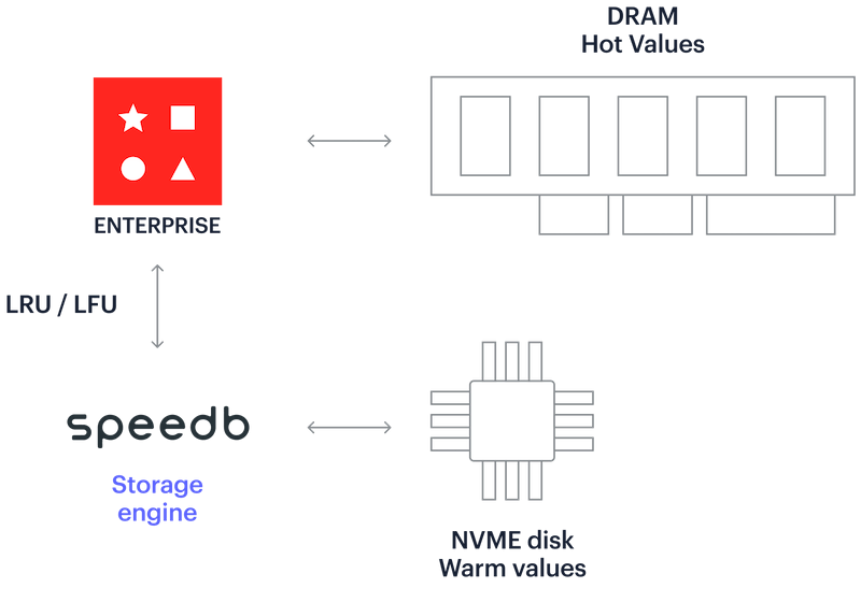
通过将访问频率较低的冷数据转移到固态硬盘,开发人员可以优化内存使用,降低与大容量内存需求相关的成本。
实际上,这可以使数据量大的应用程序运行得更快,而无需开发人员额外付出。与仅使用 DRAM 的部署相比,它还能节省高达 70% 的基础硬件设施成本。而且,由于自动分层可以高效地自动管理数据访问模式,因此您无需花费时间(计算或人工筛选)来识别热数据和冷数据。
为了增强这一功能,Redis 与创新的键值存储引擎 Speedb 建立了战略合作伙伴关系。我们将其技术整合为默认的自动分层引擎。
集成 Speedb 后,Redis Enterprise 的性能显著提升,在访问相同资源的情况下,吞吐量翻倍,延迟减半。这大大拓宽了可利用自动分层优势的用例范围。在这一改进之后,Redis Enterprise 使用自动分层的数据库规模由每个内核 5k ops/秒增至10k ops/秒。

通过自动分层使核心吞吐量加倍
三、数据案例
我们来看一个案例。
下图展示了自动分层在实际工作负载场景中的性能演变示例。蓝色条代表使用以前的存储引擎(RocksDB)的 Redis Enterprise 6.4,红色条代表使用 Speedb 的 Redis Enterprise 7.2。在基础设施方面,我们使用 I4i.8xlarge AWS 实例在 10 个分片上托管 1TB 数据库,为实现高可用性,采用总共 20 个分片,为 1,024 个客户端提供服务。
为了模拟最标准的 Redis 用例,我们在 20% DRAM 和 80% SSD 的配置上定义了两种不同的有效载荷(1KiB 和 10KiB),并提供了三种可能的使用模式:平衡读/写(1:1)、重读(1:4)和重写(4:1)。在这两种情况下,我们测量了以每秒操作数为单位的吞吐量和相应的延迟。以下图表显示了结果。
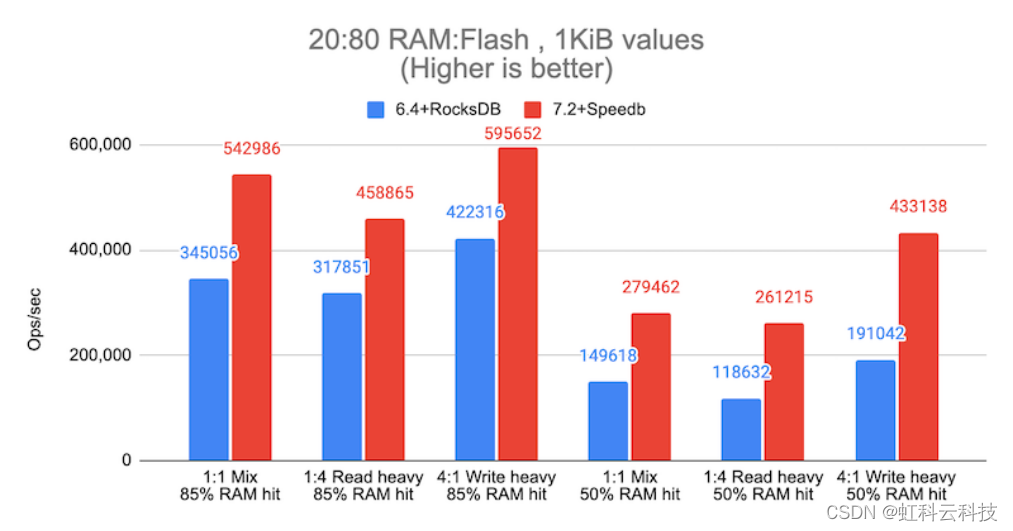
与 RS 6.4 (RocksDB) 相比,RS 7.2 (Speedb) 改进了:
-
85% 命中率时:每秒操作次数增加 1.4 倍至 1.6 倍,同时延迟降低高达 2.4 倍
-
50% 命中率时:每秒操作次数增加 1.9 倍至 2.3 倍,同时延迟降低高达 3.8 倍
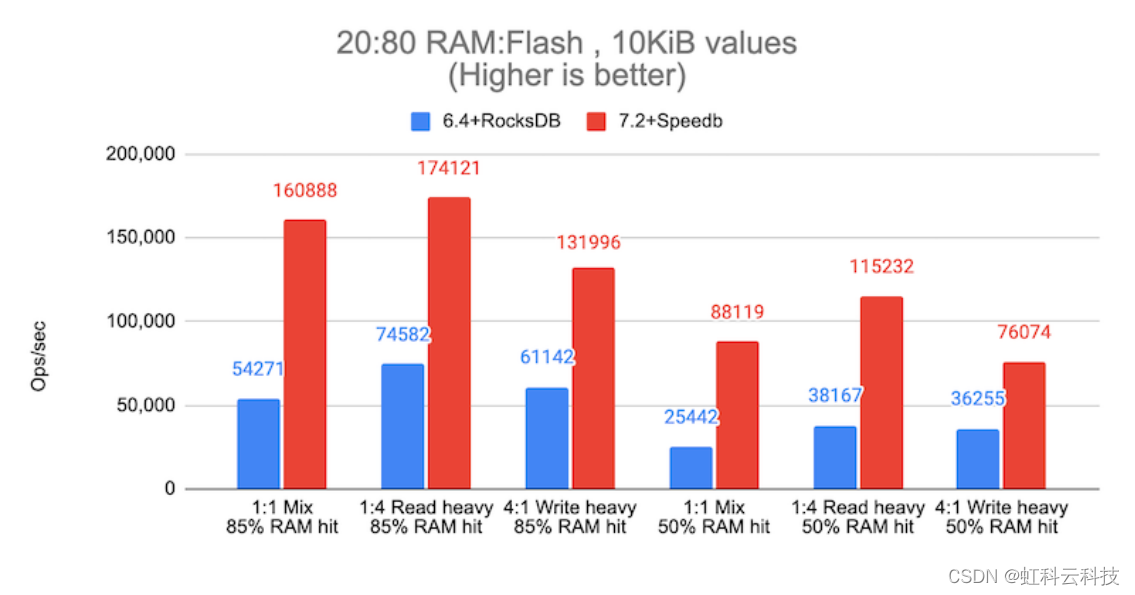
与 RS 6.4 (RocksDB) 相比,RS 7.2 (Speedb) 改进了: -
85% 命中率时:每秒操作次数增加 2.3 倍至 3.0 倍,同时延迟降低高达 3.0 倍
-
50% 命中率时:每秒操作次数增加 2.1 倍至 3.5 倍,同时延迟降低高达 3.5 倍
在所有情况下,带有 Speedb 的 Redis Enterprise 7.2 都具有更好的吞吐量,这意味着维持这种性能水平所需的应用程序速度更快,基础设施更少。
四、应用场景
自动分层尤其适用于将数据分为热数据和冷数据的情况。
1.移动银行
让我们来看看移动银行应用的例子。
如今,每个人的移动设备上都有银行应用程序。用户登录应用程序,获取余额,查看最后一笔交易,并获取其他相对较小和集中的信息。每个人都希望这一过程流畅、简单、即时。这些数据就是我们的热数据,存放在 Redis Enterprise 数据库的 DRAM 中。
用户希望获得更多信息的情况并不常见,例如旧交易记录–也许是两年前的税务数据。用户需要访问这些数据,但数据访问速度并不那么重要。这种数据集是我们的冷数据,可以保存在高速外部存储如固态硬盘中。
2.游戏行业
速度在游戏行业也很重要。例如,游戏应用对延迟有严格要求。另外,从本质上讲,游戏是一种潮流。随着时间的推移,游戏公司会积累越来越多的用户数据,并将其存储在用户资料数据库中,但并非所有用户都是活跃用户。通过自动分层,活跃用户的资料数据可以存储在 DRAM 中,而其他用户的数据则存储在 SSD 中。