EMNLP 2023 录用论文公布,速看NLP各领域最新SOTA方案
EMNLP 2023 近日公布了录用论文。
开始前以防有同学不了解这个会议,先简单介绍介绍:EMNLP 是NLP 四大顶会之一,ACL大家应该都很熟吧,EMNLP就是由 ACL 下属的SIGDAT小组主办的NLP领域顶级国际会议,一年举办一次。相较于ACL,EMNLP更偏向于NLP在各个领域解决方案的学术探讨。
今年的EMNLP 2023大会将于12月6日-10日在新加坡召开,我先整理了10篇录用论文来和大家分享,帮助NLP领域的同学了解今年的技术进展以及最新的SOTA方案,发论文更有方向。
需要论文原文及代码的同学看文末
1.Unlocking Context Constraints of LLMs: Enhancing Context Efficiency of LLMs with Self-Information-Based Content Filtering
标题:解锁LLM的上下文约束:利用基于自信息的内容过滤提高LLM上下文效率
内容:由于大型语言模型(LLM)在各种任务上都取得了显著的性能,因此受到了广泛的关注。但是,它们固定的上下文长度在处理长文本或进行长时间对话时碰到了挑战。本文提出了一种称为Selective Context的方法,该方法利用自信息量来过滤掉信息量较少的内容,从而提高固定上下文长度的效率。作者在文本摘要和问答等任务上验证了该方法的有效性,实验数据源包括学术论文、新闻文章和对话记录。

2.New Intent Discovery with Pre-training and Contrastive Learning
标题:基于预训练和对比学习的新意图发现
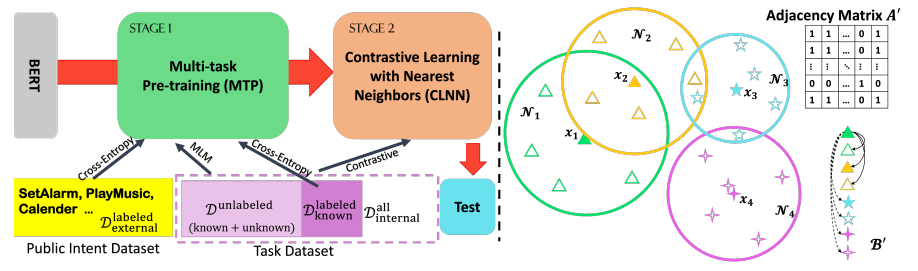
内容:在本文中,作者为新意图发现提供了两个重要研究问题的新解决方案:(1)如何学习语义表达表示,(2)如何更好地聚类表达。具体来说,作者首先提出了一个多任务预训练策略,以利用丰富的无标注数据以及外部标注数据进行表示学习。然后,作者设计了一个新的对比损失,以利用无标注数据中的自监督信号进行聚类。在三个意图识别基准测试中进行的大量实验证明,该方法无论是在无监督还是半监督场景中,都明显优于当前最先进的方法。
3.Dialogue for Prompting: a Policy-Gradient-Based Discrete Prompt Optimization for Few-shot Learning
标题:Dialogue for Prompting:基于策略梯度的少样本学习离散提示优化
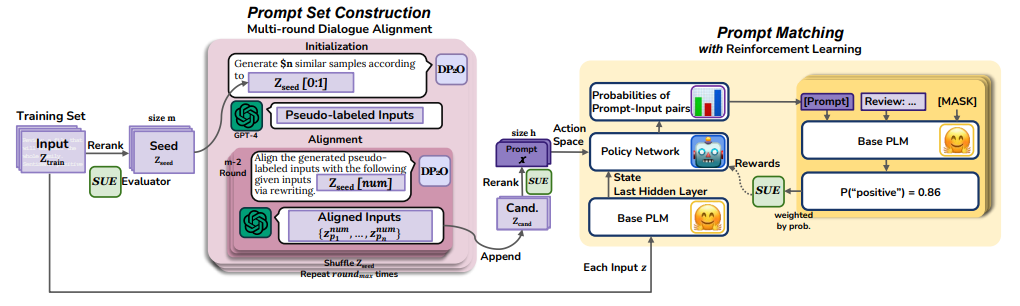
内容:论文提出了一种基于策略梯度的离散提示词优化方法DP2O。作者首先基于GPT-4设计了多轮对话setAlignment策略来生成可读性提示集。然后,提出了一个高效的提示词筛选指标来识别高质量提示词,其复杂度为线性。最后,构建了一个基于策略梯度的强化学习框架,用于最佳匹配提示词和输入。
4.CoCo: Coherence-Enhanced Machine-Generated Text Detection Under Data Limitation With Contrastive Learning
标题:CoCo:对比学习缓解数据稀缺下的机器生成文本检测与连贯性提升
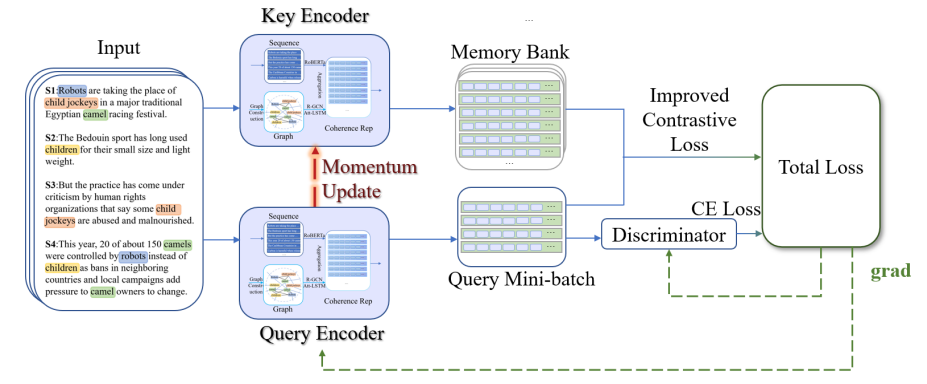
内容:在本文中,作者提出了一个名为 CoCo 的基于连贯性的对比学习模型,以在低资源场景下检测可能的 MGT。受到语言特征的区分性和持久性的启发,作者将文本表示为一个连贯性图,以捕获其实体一致性,该连贯性图进一步由预训练模型和图神经网络编码。为了应对数据缺乏的挑战,作者采用对比学习框架,并提出改进的对比损失,以在训练阶段充分利用难样本。
5.Can Language Models Understand Physical Concepts?
标题:语言模型能理解物理概念吗?
内容:作者设计了一个覆盖视觉概念和具身概念的基准测试。结果显示,随着模型规模的增大,语言模型对某些视觉概念的理解确实提高了,但对很多基本概念仍然缺乏理解。相比之下,融合视觉信息的语言模型在具身概念上表现更好。这说明视觉表示中的丰富语义信息可以帮助语言模型获得具身知识。另外,作者还提出了一种从视觉语言模型向语言模型传递具身知识的知识蒸馏方法。

6.ImageNetVC: Zero-Shot Visual Commonsense Evaluation on 1000 ImageNet Categories
标题:ImageNetVC:在1000个ImageNet类别上进行零样本视觉常识评估
内容:论文提出了ImageNetVC,这是一个针对1000个ImageNet类别设计的细粒度人工标注数据集,专门用于跨类别的零样本视觉常识评估。利用ImageNetVC,作者深入研究了非模态PLMs和VaLMs的基本视觉常识,揭示了VaLMs的缩放定律和backbone模型的影响。此外,作者还研究了影响大规模模型视觉常识的因素,为开发融合视觉常识的语言模型提供了见解。

7.Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning
标题:从信息流角度理解词内学习
内容:在本文中,作者通过信息流的视角来研究ICL的工作机制。作者发现,在示范例子中,标签词起着“锚点”的作用:(1)语义信息在浅层计算层处理过程中聚合到标签词的表达中,(2)标签词中聚合的信息为LLM的最终预测提供参考。基于这些见解,作者提出了一个锚点重新加权方法来改进ICL性能,一个示范压缩技术来加快推理,以及一个用于诊断GPT2-XL中的ICL错误的分析框架。
8.Can We Edit Factual Knowledge by In-Context Learning?
标题:我们能通过词内学习编辑事实知识吗?
内容:这篇论文探究了通过词内学习编辑语言模型中的事实知识。作者进行了全面的实证研究,结果显示词内知识编辑可以在不更新参数的情况下实现知识编辑,并取得与基于梯度的方法相当的成功率。与基于梯度的方法相比,词内知识编辑具有副作用更少的优势,包括对不相关事实过度编辑更少,以及对先前知识遗忘更少。该方法也表现出很好的可扩展性。
9.Beyond Labels: Empowering Human with Natural Language Explanations through a Novel Active-Learning Architecture
标题:超越标签:通过新颖的主动学习架构用自然语言解释赋能人类
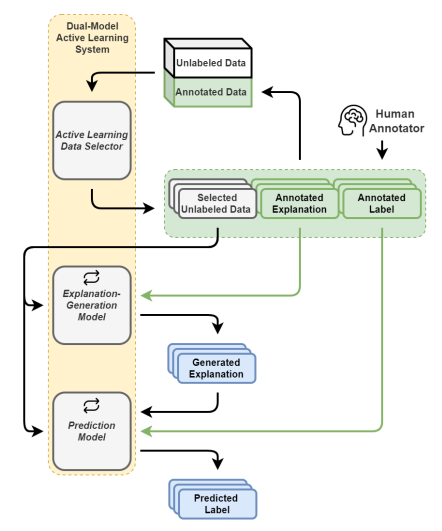
内容:这篇论文提出一个新的主动学习架构,不仅提供分类标签,还同时生成自然语言解释来协助人类用户。该架构包含解释生成模块和数据选择模块。结果显示,与仅提供标签相比,该架构生成的自然语言解释可显著提高人类的分类准确率,特别是在少样本场景下。
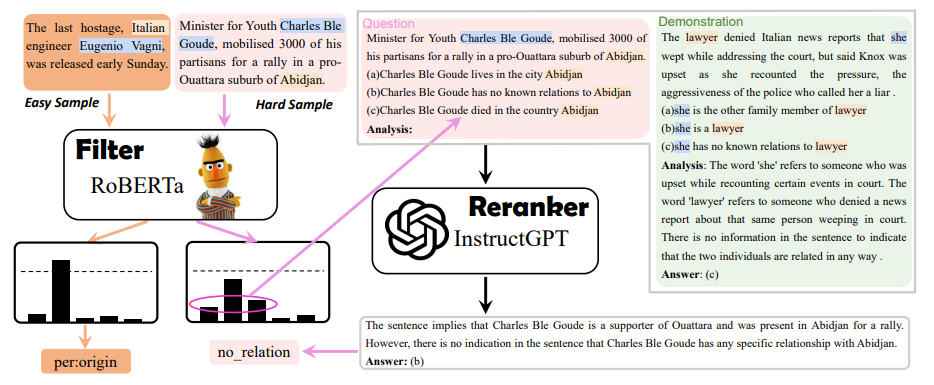
10.Large Language Model Is Not a Good Few-shotInformation Extractor but a Good Reranker for HardSamples
标题:大语言模型不是一个好的少样本信息提取器,但是一个困难样本的好重排器
内容:这篇论文研究了大语言模型在少样本信息提取任务上的表现。大语言模型本身并不是很好的少样本信息提取器,但它们擅长对难样本进行重排。因此,作者提出了一种混合方法,使用小型预训练语言模型进行过滤,然后用大语言模型重排难样本。实验表明,这种方法可以在信息提取任务上取得显著改进,而且成本可控。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“EMNLP”获取论文+代码合集
码字不易,欢迎大家点赞评论收藏!