oracle、mysql、postgresql数据库的几种表关联方法
简介
在数据开发过程中,常常需要判断几个表直接的数据包含关系,便需要使用到一些特定的关键词进行处理。在数据库中常见的几种关联关系,本文以oracle、mysql、postgresql三种做演示
创建测试数据
oracle
-- 创建表 p1
CREATE TABLE p1 (txt VARCHAR2(100),id VARCHAR2(100)
);-- 插入数据到表 p1
INSERT INTO p1 (txt, id) VALUES ('社会事业项目', '11');
INSERT INTO p1 (txt, id) VALUES ('交通项目', '12');
INSERT INTO p1 (txt, id) VALUES ('城建项目', '34');
INSERT INTO p1 (txt, id) VALUES ('城建项目', '34');
INSERT INTO p1 (txt, id) VALUES ('工业区项目', '50');
INSERT INTO p1 (txt, id) VALUES ('经济适用房项目', '60');-- 创建表 p2
CREATE TABLE p2 (txt VARCHAR2(100),id VARCHAR2(100)
);-- 插入数据到表 p2
INSERT INTO p2 (txt, id) VALUES ('社会事业项目', '11');
INSERT INTO p2 (txt, id) VALUES ('社会事业项目', '11');
INSERT INTO p2 (txt, id) VALUES ('交通项目', '12');
INSERT INTO p2 (txt, id) VALUES ('农业水利项目', '33');
INSERT INTO p2 (txt, id) VALUES ('城建项目', '34');
INSERT INTO p2 (txt, id) VALUES ('经济适用房项目', '60');postgresql/mysql
-- 创建表 p1
CREATE TABLE p1 (txt VARCHAR(100),id VARCHAR(100)
);-- 插入数据到表 p1
INSERT INTO p1 (txt, id) VALUES ('社会事业项目', '11');
INSERT INTO p1 (txt, id) VALUES ('交通项目', '12');
INSERT INTO p1 (txt, id) VALUES ('城建项目', '34');
INSERT INTO p1 (txt, id) VALUES ('城建项目', '34');
INSERT INTO p1 (txt, id) VALUES ('工业区项目', '50');
INSERT INTO p1 (txt, id) VALUES ('经济适用房项目', '60');-- 创建表 p2
CREATE TABLE p2 (txt VARCHAR(100),id VARCHAR(100)
);-- 插入数据到表 p2
INSERT INTO p2 (txt, id) VALUES ('社会事业项目', '11');
INSERT INTO p2 (txt, id) VALUES ('社会事业项目', '11');
INSERT INTO p2 (txt, id) VALUES ('交通项目', '12');
INSERT INTO p2 (txt, id) VALUES ('农业水利项目', '33');
INSERT INTO p2 (txt, id) VALUES ('城建项目', '34');
INSERT INTO p2 (txt, id) VALUES ('经济适用房项目', '60');语法
左关联
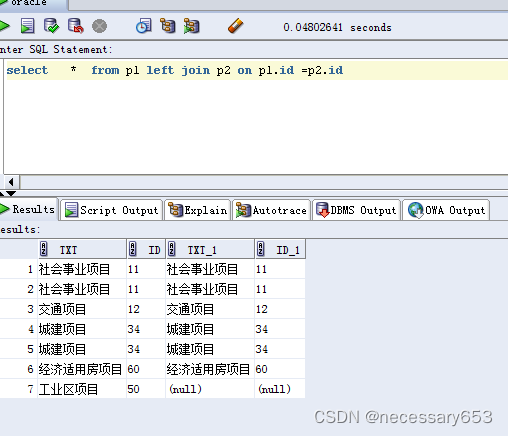
在使用left join语法时,可以看到,如果关联字段并不是唯一字段,数据并不会去重
重复数据:“社会事业项目” 两条数据行会出现数据重复
右关联
在使用right join语法时,可以看到,如果关联字段并不是唯一字段,数据并不会去重
重复数据:“社会事业项目”,“工业区项目” 两条数据行会出现数据重复

在使用right join语法时,可以看到,如果关联字段并不是唯一字段,数据并不会去重
重复数据:“社会事业项目” 两条数据行会出现数据重复
内关联(交集)

select * from p1 inner join p2 on p1.id =p2.id --等效于
select * from p1 join p2 on p1.id =p2.id 在使用inner join语法时,可以看到,如果关联字段并不是唯一字段,数据并不会去重
重复数据:“社会事业项目” 两条数据行会出现数据重复
inner是一个可选关键字

内链接的去重写法(此时exists 替换成not exists 便是补集结果)
select * from p1 where exists (select 1 from p2 where p1.id = p2.id )--使用此写法不会因为匹配表有重复匹配记录而发生笛卡尔交叉,产生重复项,但是主表的重复项不会进行去重

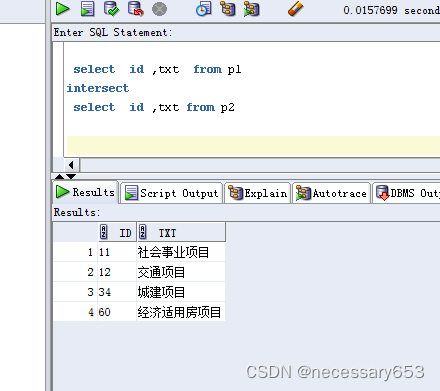
--oracle、postgresql、mysqlselect id ,txt from p1
intersectselect id ,txt from p2--使用此写法不会因为匹配表有重复匹配记录而发生笛卡尔交叉,产生重复项,但是主表的重复项也会进行去重,此写法适用于mysql、postgresql、oracle
补集
此时再加入一条数据,查看不同语法下的去重效果
对p1表增加一条测试数据
INSERT INTO p1 (txt, id) VALUES ('工业区项目', '50');
此时p1表的数据状态


补集可以使用上文提到的eixsts 写法
select * from p1 where not exists (select 1 from p2 where p1.id = p2.id )
可以使用minus
--oracle select id ,txt from p1 minus select id ,txt from p2--postgresql,mysqlselect id ,txt from p1 except select id ,txt from p2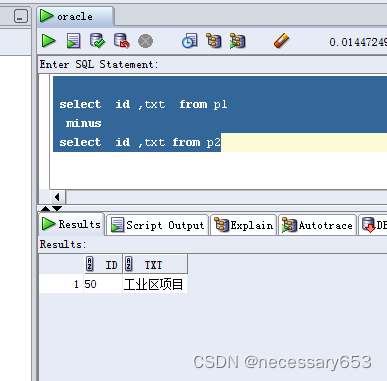
使用exits 不会对主表的重复数据进行去重,使用minus 会对结果进行去重后再展示。
并集
并集主要使用union 、union all 的语法,两者语法的区别主要在于对结果的去重处理
--oracle/postgresql/mysql
--结果去重
select id ,txt from p1
unionselect id ,txt from p2
--结果不去重select id ,txt from p1
union allselect id ,txt from p2union 结果去重效果

union all结果不去重效果
