浅谈MySQL索引
目录
1.索引的定义
2.索引的原理
3.Hash索引与B+ Tree索引
4.索引的分类
5.建立索引的注意事项
1.索引的定义
索引是存储引擎用于快速找到数据记录的一种数据结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
索引一般存于磁盘中,是一种以空间换时间的方案。
简单来说索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。但同时,为了这个查询速度,字典表就要多花几页纸来存储音序表。
同时,尽管索引可以大大提高查询速度,但当对表进行增加、删除、修改时,由于索引也要动态维护,索引会降低更新表的速度。
针对以上问题,一种解决方案则是需要大量更新数据时,先删除索引,再进行数据的更新。
2.索引的原理
其本质是不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机事件变为顺序的事件。也就是说,索引可以帮助我们总是用同一种查找方式来锁定数据。
简单来说,就是把数据分成页,比如第一页存储第1到第100条数据,第2页存储101到200条数据(MySQL中每一页最大为16k,存满一页就新增一页)......当需要查询第150条数据时,根据索引会最终直接分页到第2页进行查询。这样在查找数据时就能去除大多数无用的数据。
在MySQL中,基本的数据页模型如下:
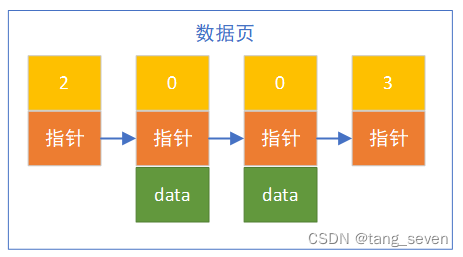
每一页数据中包括record_type(2位最小记录,3位最大,0位普通用户数据,1位为B+ tree结构中非页节点的目录项)、next_record指向下一条记录的地址、用户数据。
数据与数据之间形成单链表,从小指向大。
3.Hash索引与B+ Tree索引
MySQL的存储引擎主要使用B+ Tree和Hash两类数据结构作为索引的存储结构。
(1)Memory表(只存于内存中,断电会消失,适用于临时表)默认索引类型为Hash索引。
Hash索引把数据以hash形式组织起来,每个键只对应一个值,因此查找一条记录时,经过一次哈希计算即可找到对应的键值,速度非常快。但也由于散列进行分布,所以Hash索引不支持范围查找和排序功能。
(2)B+ Tree是innoDB和MyISAM存储引擎模式的索引类型。
B+树索引中,非叶节点仅存放目录项(即非叶子节点上仅存储键值),所有数据均存储在叶子节点,叶子结点之间组成链表(双向链表,既能左遍历又能右遍历)。如下图(图中数据页结构为简化版)所示:
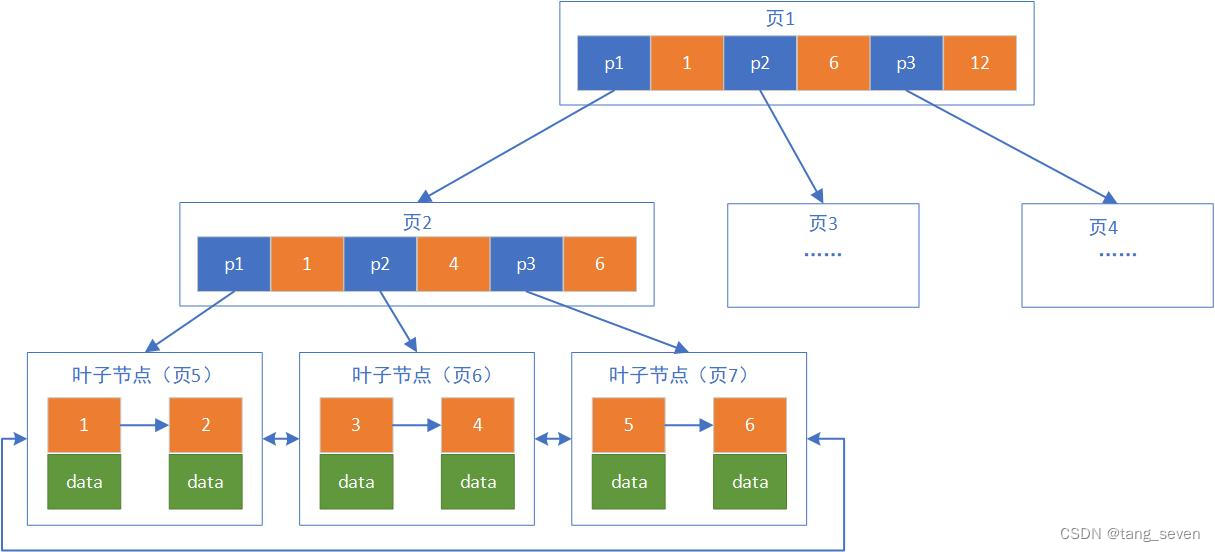
根据上图B+ Tree结构,如果需要查找id=5的数据:
- 从根节点找到页1开始查询,加载关键字1、6、12,判断1<5,5<6,根据指针p1找到页2;
- 加载关键字1、4、6,判断5>1,5>4,5<6,根据指针p2找到页6;
- 到达叶节点,在关键字链表中命中最终结果5,读取数据行;
相对于Hash索引,B+ Tree在查找单条记录时,由于需要从根节点到叶节点逐级寻找,速度较慢,更适合范围查询和排序操作。
(3)为什么使用B+ Tree
B+树是一种矮壮型的树形结构,这就意味着他的层级较小,存储的叶子节点更多,这样的话就可以大大的降低查询时检索的次数,进行IO的次数越少,从而提高查询效率。
同时相比于B 树,由于B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比B树更矮胖,即查询底层节点的磁盘 I/O次数会更少。
最后,由于B+ 树叶子节点之间用链表连接了起来,有利于范围查询。
4.索引的分类
MySQL根据其物理实现方式分为聚簇索引和非聚簇索引,关键在于数据跟索引是否存储在一起。数据绑定一起的是聚簇索引,存储的数据为全量的用户数据;否则为非聚簇索引。
聚簇索引是根据主键搭建起来的B+ Tree,innodb会自动帮我们创建。其对于主键的范围查找和排序速度都非常快。非聚簇索引键为条件进行查询时,找到叶子节点的数据之后,再通过叶子节点的id,再去聚簇索引中查询一遍,才能拿到所有字段。
MySQL的默认存储引擎Innodb在进行数据插入时,数据必须要指定一个索引(主键>唯一键>rowid)存储在一起。而为了避免数据冗余存储,其他的索引的叶子节点存储的是聚簇索引的key值。所以,innodb中既有聚簇索引,又有非聚簇索引。
MySIAM存储引擎中没有聚簇索引。
而根据实现的功能,创建的索引又分为:
1)NORMAL:普通索引,MySQL中最基本的索引,任何一列上都可创建。该类索引创建时没有任何限制条件,只是为了加快查询的速度。
2)UNIQUE:唯一索引,该索引列的所有值都只能出现一次,即必须唯一。主键索引是不允许值为空的唯一索引,用于唯一标识一条记录。
3)FULLTEXT:全文索引,主要用来查找文本中的关键字,判断字段是否包含,只能在 CHAR、VARCHAR 或 TEXT 类型的列上创建。在 MySQL 中只有 MyISAM 存储引擎支持全文索引。
4)SPATIAL:空间索引,对空间数据类型的字段建立的索引,主要用于地理空间数据类型 GEOMETRY,只能在存储引擎为 MyISAM 的表中创建。
注:联合索引是基于多个字段下的以上索引。
5.建立索引的注意事项
1)除了主键(自带主键索引)和常用于group by、order by、distance等推荐建立索引的字段外,尽量选择类型小的创建索引,比如int等整数类型。其对应的索引占用空间也小,一页中放置的记录就更多,I/O损耗就更少。
2)使用字符串前缀创建索引。即需要为一个存放了很长字符串的字段需要建立索引时(该字段作为where中的查询条件),可以取该字段的前若干字符创建索引。既节省空间,又减少了字符比较的时间。
(注:基于以上规则,使用varchar类型字段建立索引时,必须根据区分度指定索引长度,区分度公式:count(distinct left(列名,索引长度))/count(*),越小越好)
比如,使用address字段建立索引,根据以下代码查询区分度,选择最小的作为索引长度:
select count(distinct left(address,6))/count(*)as s1,
count(distinct left(address,8))/count(*)as s2,
count(distinct left(address,10))/count(*)as s3
from table3)多个字段需要建立索引时,建议建立联合索引优于单值索引。
4)建立联合索引时,建议把使用最频繁的列放在联合索引的左侧(联合索引是使用多列索引的第一列(最左)构建的 B+ Tree)。
5)每张表上索引数量一般不超过6个