【踩坑】hive脚本笛卡尔积严重降低查询效率问题
前一阵子查看我们公司的大数据平台的离线脚本运行情况, 结果发现有一个任务居然跑了一天多, 要知道这还只是几千万量级的表, 且这个任务是每天需要执行的
于是我把hive脚本捞出来看了下, 发现无非多join了几个复杂的子查询, 应该不至于这么久, 包括我又检查了是不是没有加上每日分区的筛选条件
在反反复复测试调整以后, 我发现问题出在这里:
隐式join的时候顺序问题会导致错误的笛卡尔积(不确定什么版本hive)
假如t1和t2关联,t2和t3关联, 但是如果写成了from t1,t3,t2比如下面这样, 就会造成t1和t3直接笛卡尔积, 再和t2笛卡尔积, 再where筛选
--
select x
from t1,t3,t2
where t1.id = t2.t1_id
and t2.id = t3.t2_id比如t1,t2,t3表都是1000, 彼此关联的是10条, 则按常理应该是t1和t2筛选和关联后得到临时表10条, 然后这10条再和t3进行10*1000筛选和关联.
但是根据explain解释执行, 貌似hive会将上面的直接1000* 1000*1000 可想而知这个效率会是怎么样
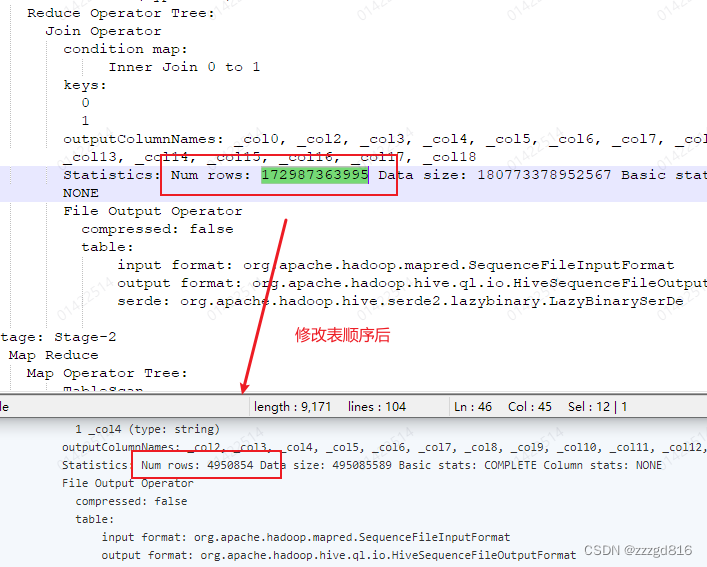
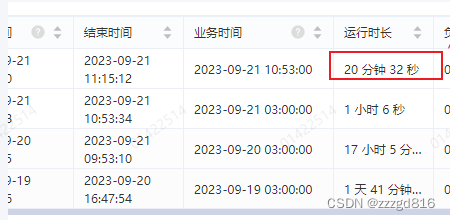
最后改为正确的顺序, 从1天多变成了二几分钟.搞定
结论
- hive这个不知道是不是bug, 也可能后续会修复, 但是保险起见最好按表的关联顺序来写
- 建议用显式join查询
- 写完hive脚本测试跑一次看看效率,不确定就explain