基于ChatGPT+词向量/词嵌入实现相似商品推荐系统
最近一个项目有个业务场景是相似商品推荐,给一个商品描述(比如 'WIENER A/B 7IN 5/LB FZN' ),系统给出商品库中最相似的TOP 5种商品,这种单纯的推荐系统用词向量就可以实现,不过,这个项目特点是商品库巨大,有19万余商品,且商品相似度高(都是肉类制品),所以希望引入ChatGPT,利用大语言模型的推理能力进一步提高推荐准确率。
讨论了一下,决定用向量相似度计算初筛+ChatGPT优选。
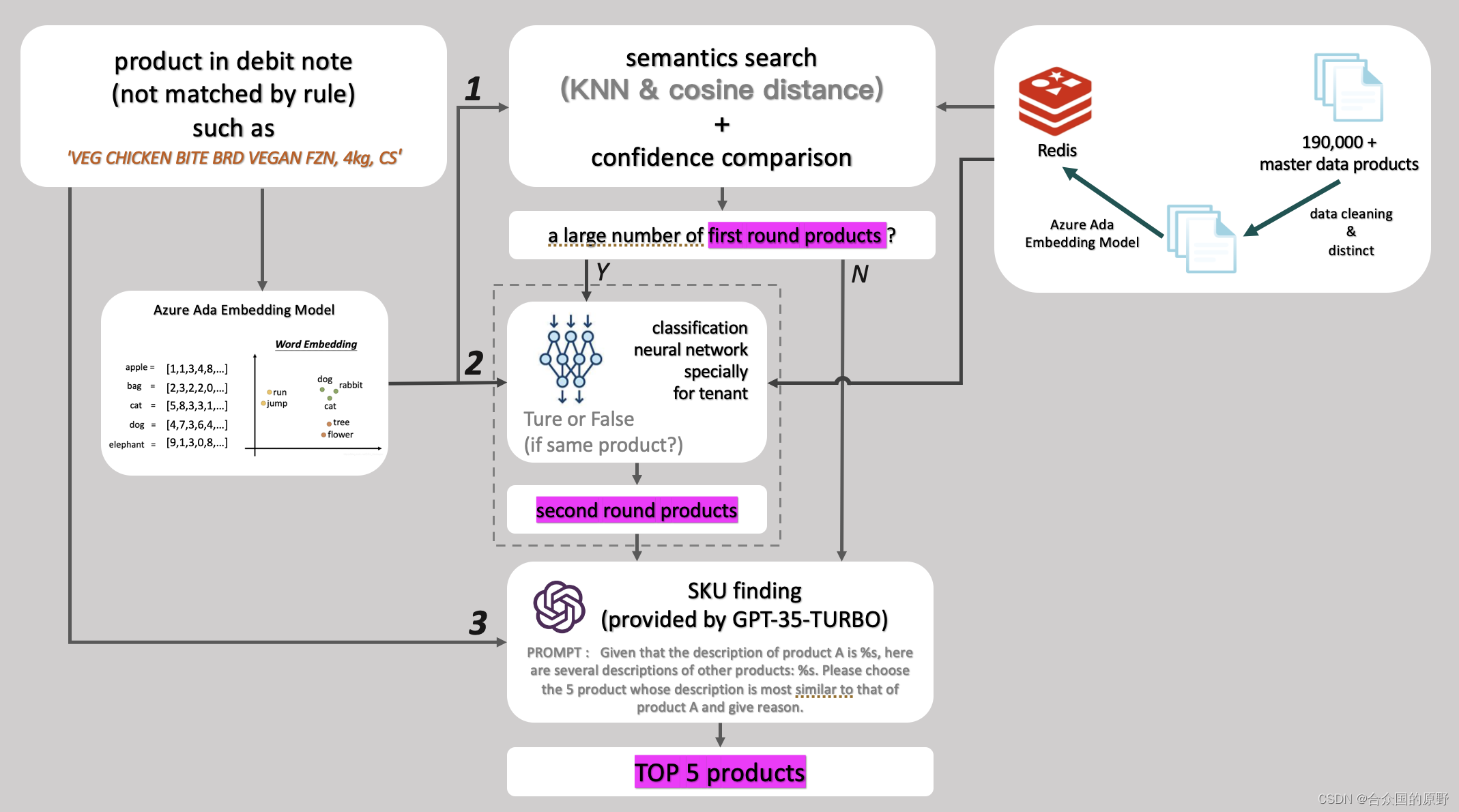
处理思路:
1. 词向量相似度计算初筛
a. embedding 如何获取?
直接调用微软Azure Ada Embedding api,质量高,价格低,并且可以直接获取句子embedding。
b. 19万商品embedding如何存储并检索?
使用Redis存储,Redis可以做内存KNN,并有版本对向量计算做了优化(似乎叫STACK)。
c. 商品描述中包含大量缩写,歧义问题严重,直接获取embedding质量很低,如何解决?
使用ChatGPT扩展语义,类似以下prompt:
已知下面是关于一种百货产品的描述,描述中可能包含缩写,请推测是何种品类的商品,给出三种可能:WIENER A/B 7IN 5/LB FZN,并将答案按以下格式输出[答案1:xx,答案2:xx,答案3:xx]
以上prompt喂给ChatGPT,可以得到以下输出:
根据描述,这种百货产品可能是一种冷冻肉制品,下面是三种可能的商品:\n\n1. 热狗:根据描述中出现的\"WIENER\"这个词,可能是指热狗,这是一种由碎肉、淀粉、香料等原料制成的肉制品,通常是热狗面包的主要馅料之一。n2. 香肠:由于描述中出现了7IN和5/LB这两个词,可能是指长度为7英寸,每磅5个的香肠,这是一种由碎肉、淀粉、香料等原料制成的肉制品,通常是早餐的主食之一。\n3. 火腿肠:这是一种由肉类和淀粉等原料制成的肉制品,通常是热狗的替代品,由于描述中没有具体指明该产品的形状,因此这也是一种可能的商品。\n\n[答案1:热狗,答案2:香肠,答案3:火腿肠]
可以看到回答中的语义比原有描述 'WIENER A/B 7IN 5/LB FZN' 清晰了很多,试验下来推荐准确率比直接用原有描述高了很多,但是回答中仍然包含很多“废话”——介词/连词/符号其实都没有什么语义在里面,最后比较下来,直接用三种可能的商品名(比如'[答案1:熏肠,答案2:烤肠,答案3:火腿]')生成embedding来计算相似度是效果最好的。
2.ChatGPT优选
a. 为什么优选?
词向量相似度这种方法,对某个起到决定性作用关键词的判断能力是不足的,比如下面两种商品
'WIENER A/B 7IN 5/LB FZN CS'
'WIENER A/B 7IN 5/LB FZN EA'
毫无疑问,这两个描述的向量相似度是极高的,但这实际不是同种商品,因为他们的销售规格不同,CS是按箱销售,EA是按件销售,如果用户输入的描述中带有CS,必然是希望模糊检索按箱销售的商品。如果让人来检索,肯定是能判断这点的,现在就让ChatGPT来替代人完成这步优选,让GPT从相似度得到的TOP N件商品中,选出5件最靠谱的商品。
我们观察了正确商品在相似度排名结果中的分布情况,大部分在TOP5中,小部份在TOP6 - TOP20中,正确商品分布在TOP20之外的情况并不多,因此,我们将TOP N中的N设定为20。
b. 优选prompt
使用类似如下prompt,ChatGPT会格式化返回将它认为与给定描述最相似的5种商品的id。
It is known that the description of product A is '%s'. Now there are %s products with serial numbers starting from 0. Their descriptions are: '%s'. Abbreviations may be included in the above descriptions, please select %s product numbers that are most likely to be the same product as Product A, and strictly output the product serial numbers in the following template [xx, xx, xx, ...]
3. 其他
可以看到流程图上,除了上述两个主要步骤,还有两步,分别是相似度阈值筛选和二分类模型。我们在实践中不是直接取相似度TOP20商品进入下一步,而是给定一个相似度阈值,比如0.8,将所有相似度高于0.8的商品选出来,这导致三种结果——进入下一步的商品很少/适中/很多,前两种情况没什么影响,直接填进prompt喂给GPT择优就行,但如果是第三种情况,那GPT的推理能力会大大下降——GPT从20件商品中选5件商品比从100件商品中选5件商品要靠谱,因此为这种情况加入一个分类模型缩减备选商品规模。