计算机视觉: 基于隐式BRDF自编码器的文生三维技术
论文链接: MATLABER: Material-Aware Text-to-3D via LAtent BRDF auto-EncodeR
背景

得益扩散模型和大量的text - image 成对的图片, 现在文生2D的模型已经比较成熟的框架和模型,主流的技术比如说stable diffusion 和 midjourney 以及工业领域runway 等。当2D技术日渐成熟之后,开发者的眼光逐渐转向了文生3D的领域,开创性的工作由DreamFusion提出的Relying on promising Score Distillation Sampling (SDS) 一文中提出SDS_loss,简单的来说其是一种优化3D表示的技术,通过向不同的方向去渲染图片生成,使得生成的图片更加的逼近真实的图片。

在Dream Dusion工作之后,又有几项突出性的工作提出:
- Magic3D: 第一个将DreanFusion生成模型的分辨率由64 提升至512 ,其大致可以分为两个阶段,第一个阶段用NERF , 第二个阶段将模型转成Mesh的格式再给其上色。
- Fantasia3D: 同时实现了一个更好的geometry 和现实纹理的生成
- ProlificDreamer: 通过优化SDS loss ,从而实现更加逼真的纹理效果。
但是上述的几种方法中,虽然都取得了不错的效果,但是在这些工作中材质的因素却鲜有人考虑,比如说dreamFusion 只考虑了光照的反射因素。而Fantasia3D虽然使用BRDF的材质进行建模,但是其优化的过程中使用的固定的enviroment map所以导致物体非常容易与环境的光照进行耦合。 而真实理想的环境下,我们应当期望不同的材质能与不同的环境做解耦从而形成更加逼真的真实环境下的3D模型。但是由于少有的文本-材料对数据集,目前仅有一些BRDF材料数据库,因此前人的工作在对材质的因素还是止步不前。
MATLABER
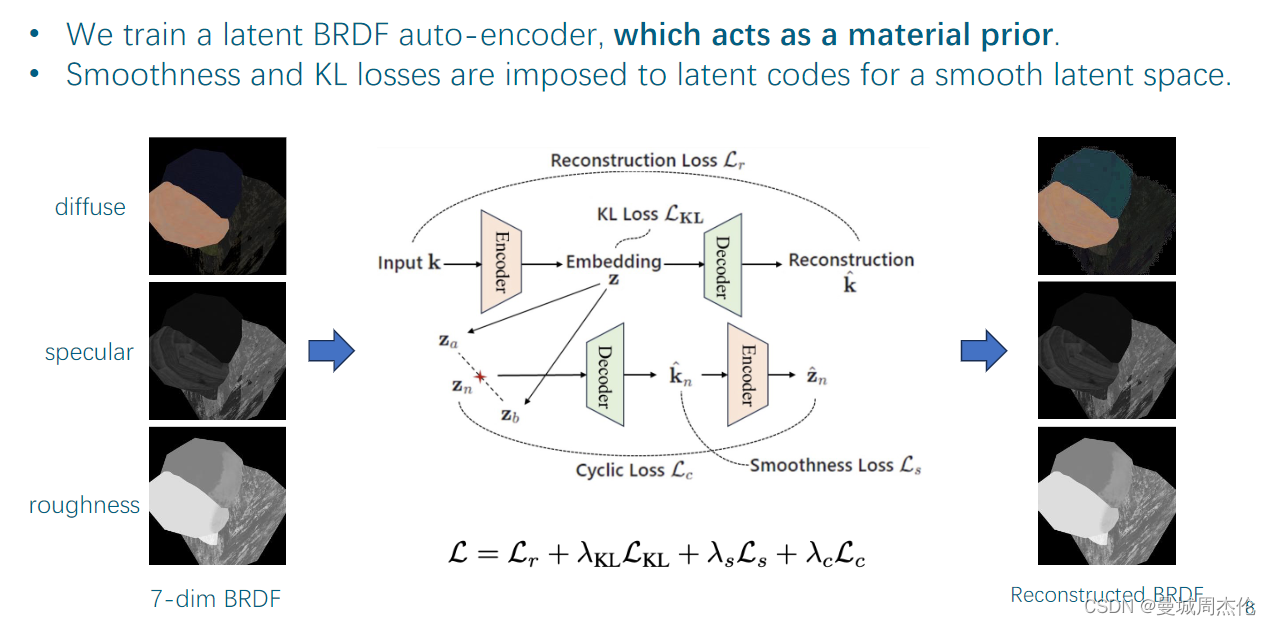
作者提出了一种隐式的BRDF自编码器去实现一个材质的prior。其工作原理大致如上图,首先作者是在前人公开的一个7维的BRDF材质的数据集上做训练,首先将数据通过一个Encoder得到一个隐式空间上的code然后再通过一个Decoder 得到了一个重建后的BRDF材质, 然后去计算重建的损失。除此之外,作者参考前人的工作通过线性插值的方法得到了一个平滑的latent space 记作Zn, 然后Zn通过一个Decoder-Encoder的结构可以恢复成Zn’ 其中添加了Cyclic Loss 和Smoothness Loss 以及初始的latent code 和 经过插值得到的smooth latent space 中间的KL散度的损失。将上述的这四个Loss通过加权平均加起来之后就是整个BRDF自编码器的损失了。可以看到经过优化后的模型恢复的BRDF的材质跟原始的材质还是比较像的。
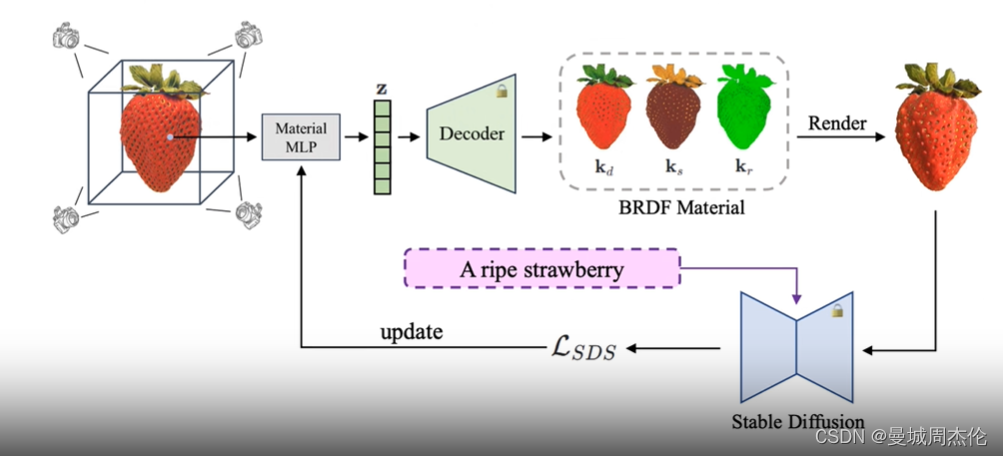
通过上一节介绍的BRDF材质的自编码器训练好后,作者就将其整合到几何建模的3D-generation model (参考Fantasia3D工作)里。其整个pipeline,如上图,材质的MLP首先去预测latnt code Z然后通过前文训练好的Decoder去重塑一个7维的BRDF材质,在通过渲染管线把图片渲染出来,再通过将图片加上SDS loss 再去进行扩散的过程,去更新材质的MLP 以及几何建模里的参数,从而实现整个Pipeline。

为了解决材质与环境解耦的一些问题,在训练的过程中,作者提出了几个trick:
- 使用了多个环境地图,人为的去创造多个反应光从而使得模型泛化能力增强
- 训练过程中,不断的旋转环境光,使其模型多光照角度的解耦能力增加
- SDS 损失去自适应的针对不同材质的变化
- 添加材质损失的正则项,使得生成的BRDF材质更加的平滑
下面是几个demo,可以看到整个模型生成的3D模型对环境光的解耦能力还是十分真实的。

除此之外,由于材质的latent code 是一个十分平滑的空间,所以整个模型还可以通过对atent code 进行线性插值的方法去改变最终生成的结果,下面是几个例子可以将材质由黄金变成银,也可以将颜色进行改变。

整体来说,作者提出的模型基于几个trick相比于前人的工作效果还是很好的。作者在原文中从四个方面(1.3维物体和真实的物体是否能对齐 2. 外观是否真实 3. 外观是否细节 4. 材质与环境光的解耦能力)也做了量化对比实验,可以看到作者提出的模型相比于之前的模型在后面三个维度都是最高的。 Algnment 的不足,作者解释是因为stable diffusion不足导致的,是clip model因为其对文本的理解能力相比于Magic3D模型使用的text-iamge-diffusion model 更差,所以导致对齐的能力相比于Magic3D模型更差。

未来工作
- 针对形状和外观能力对齐能力的优化
- 更大的BRDF的数据库
- 生成的模型与环境更好的解耦能力
- 基于SDS loss的优化
- 3D物体拓展到世界场景