Java性能分析
0、问题代码:
代码问题其实很明显,但是这里主要是为了练习如何使用工具进行分析
所以最好先不要看代码,假装不知道程序逻辑,而是先通过工具去分析,再结合分析数据去看代码,从而推出问题点在哪
import java.util.ArrayList;
import java.util.List;public class PerfTest {public static void main(String[] args) {//这里随机器的配置不同,可以适当把线程数量改大一点for (int i = 0; i < 4; i++) {int index = i;new Thread(() -> {while (true) {for (int k = 0; k < 10; k++) {List<String> list = new ArrayList<>();String str = "" + index;for (int j = 0; j < 10000; j++) {str += "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"+j;}list.add(str);System.out.println(index+"_"+k);try {Thread.sleep(10);} catch (InterruptedException e) {throw new RuntimeException(e);}}try {Thread.sleep(10);} catch (InterruptedException e) {throw new RuntimeException(e);}}}).start();}}
}运行:
javac PerfTest.java
java -Xmx100m PerfTest
通过jps命令找到PerfTest进程pid
top命令观察进程cpu使用情况
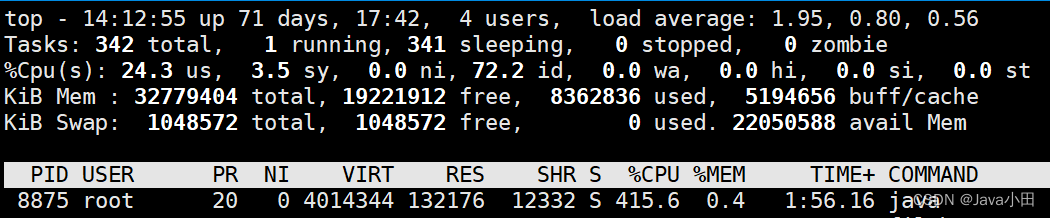
可以看到cpu使用超过400%
1、使用async-profiler进行分析
GitHub地址:https://github.com/async-profiler/async-profiler
wget https://github.com/jvm-profiling-tools/async-profiler/releases/download/v2.9/async-profiler-2.9-linux-x64.tar.gz
tar zxvf async-profiler-2.9-linux-x64.tar.gz
cd async-profiler-2.9-linux-x64
./profiler.sh -d 30 -f /tmp/flamegraph.html pid
把生成的flamegraph.html导出到本地用浏览器打开,如下图:
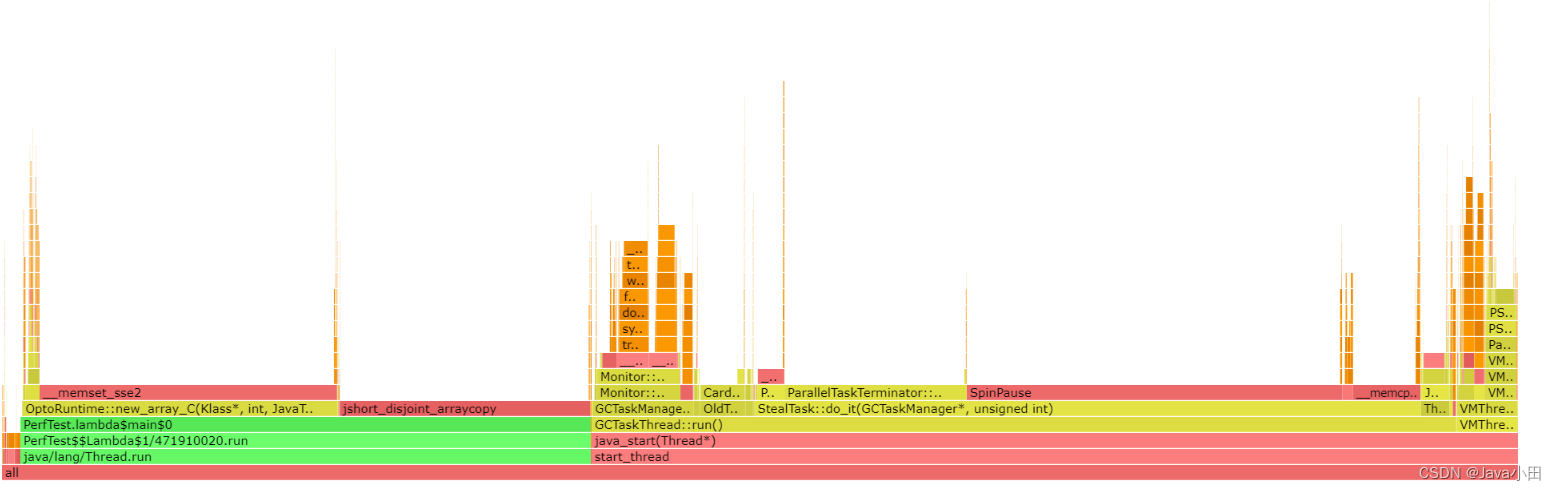
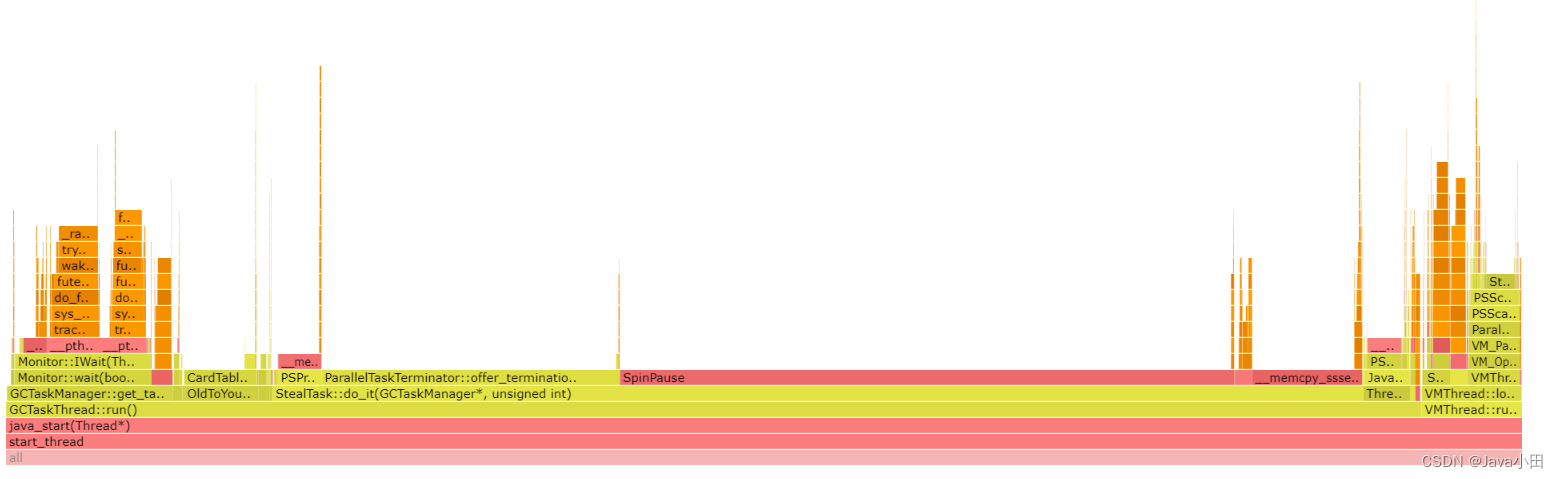
可以看出大部分cpu消耗都是在GC上
2、使用arthas分析
GitHub地址:https://github.com/alibaba/arthas
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
进入arthasshell后,使用thread命令:
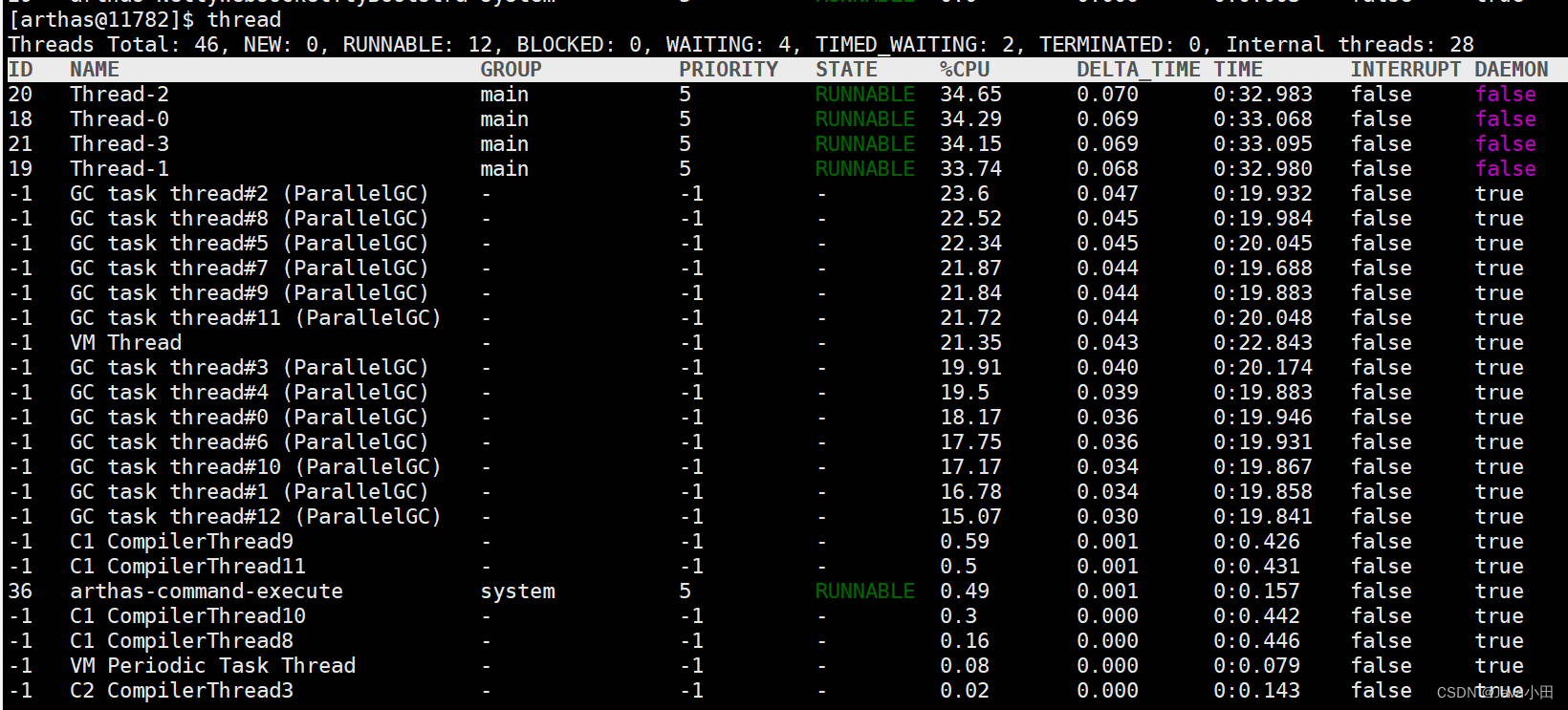
也可以看出GC线程消耗了大量的CPU
把线程数改成20之后,效果更明显
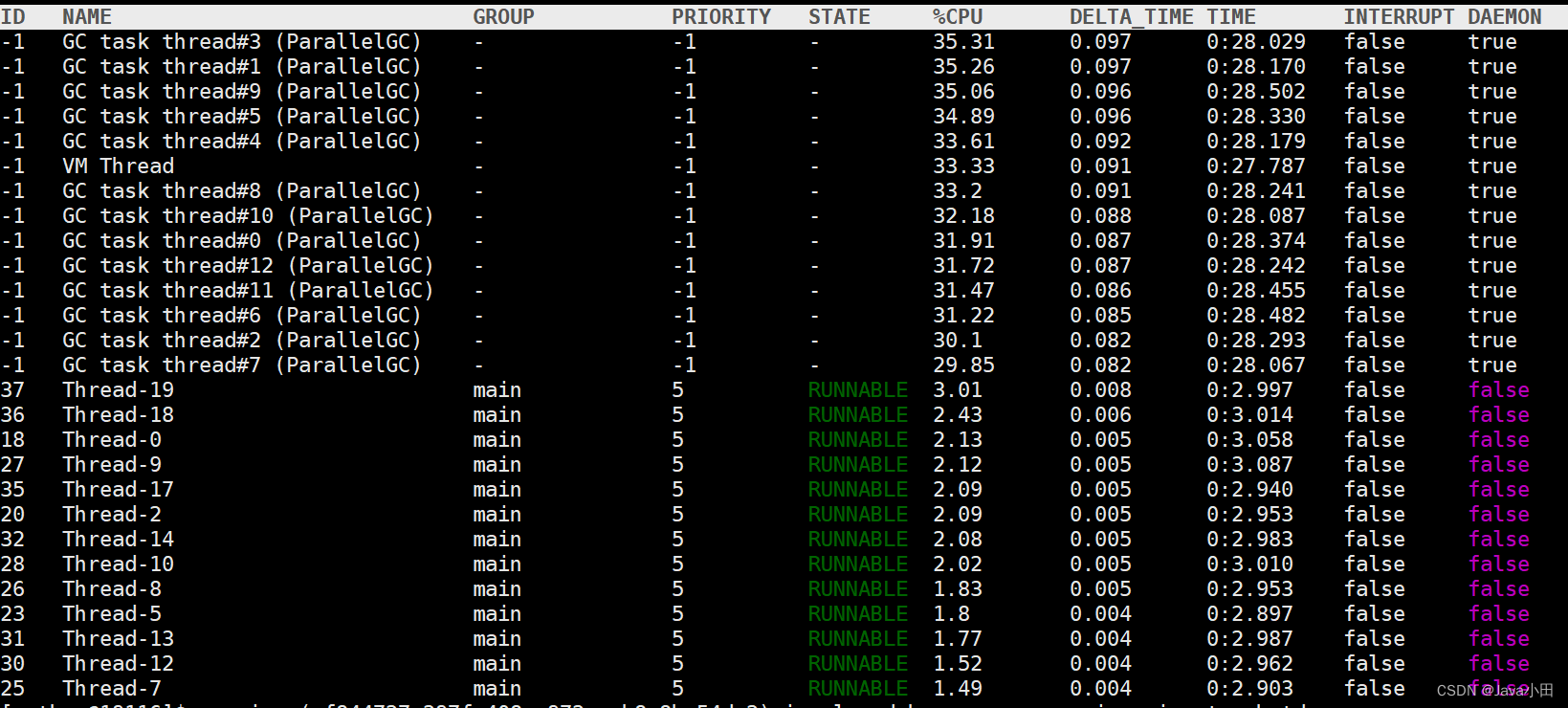
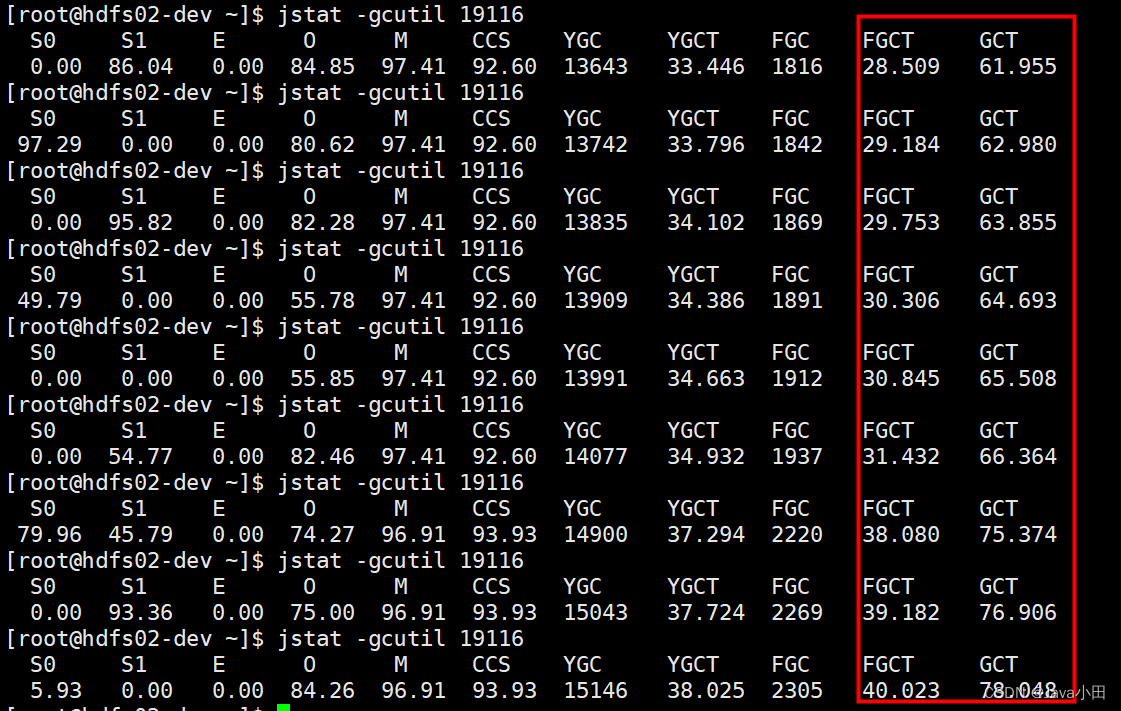
直接使用jstat -gcutil pid命令,也能看出频繁的触发gull gc
3、代码优化
这里代码问题其实已经很明显了,是一个经典的String做字符串拼接导致的性能问题,直接用String做字符串拼接会产生大量不必要的String对象,导致频繁GC。
改为使用StringBuilder就可以大大缓解了
优化后的代码:
import java.util.ArrayList;
import java.util.List;public class PerfTest2 {public static void main(String[] args) {for (int i = 0; i < 4; i++) {int index = i;new Thread(() -> {while (true) {for (int k = 0; k < 10; k++) {List<String> list = new ArrayList<>();StringBuilder str = new StringBuilder(50*10000);str.append(index);for (int j = 0; j < 10000; j++) {str.append("aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"+j);}list.add(str.toString());System.out.println(index+"_"+k);try {Thread.sleep(10);} catch (InterruptedException e) {throw new RuntimeException(e);}}try {Thread.sleep(10);} catch (InterruptedException e) {throw new RuntimeException(e);}}}).start();}}
}
再次运行:
javac PerfTest2.java
java -Xmx100m PerfTest2
可以看到一个很明显的变化就是,控制台的输出速度快了很多,而且cpu占用也没那么高了,说明优化起到了很大的效果
然后再进一步测试,把线程数从4个改为20个
发现这时候cpu也开始变高,GC也变得很频繁
猜测是因为jvm分配的内存较小,导致内存紧张,频繁触发full gc(这里也可以用工具进行内存分析,但是懒得折腾了,后面有空再补充,如果有的话0.0)
通过java -Xmx1000m PerfTest2把内存调大十倍,再观察,cpu和gc都降下来了
(这里的操作和前面类似,就不再贴命令和截图了~~)
另外这里也延申一个问题,前面有问题的程序,也把内存调大十倍观察,这时候再观察:
1、cpu还是居高不下
2、gc大大缓解
3、程序执行性能得到提升,但还是很慢
这时候也只能结合arthas或者async profiler工具定位到cpu占用高的线程,结合阅读代码进行分析了