【PyTorch】单对象分割项目
对象分割是在图像中找到目标对象的边界的过程。单目标分割的重点是自动勾勒出图像中一个目标对象的边界。对象边界通常由二进制掩码定义。
通过二进制掩码,可以在图像上覆盖轮廓以勾勒出对象边界。例如以下图片描绘了胎儿的超声图像、胎儿头部的二进制掩码以及覆盖在超声图像上的胎儿头部的图像分割:

目录
准备数据集
创建自定义数据集
划分数据集
创建数据加载器
搭建模型
定义损失函数
定义优化器
训练和评估模型
准备数据集
使用胎儿头围数据集Automated measurement of fetal head circumference,在怀孕期间,超声成像用于测量胎儿头围,监测胎儿的生长。数据集包含标准平面的二维(2D)超声图像。Automated measurement of fetal head circumferenceFor more information about this dataset go to: https://hc18.grand-challenge.org/![]() https://zenodo.org/record/1322001#.XcX1jk9KhhE
https://zenodo.org/record/1322001#.XcX1jk9KhhE
import os
path2train="./data/training_set/"imgsList=[pp for pp in os.listdir(path2train) if "Annotation" not in pp]
anntsList=[pp for pp in os.listdir(path2train) if "Annotation" in pp]
print("number of images:", len(imgsList))
print("number of annotations:", len(anntsList))import numpy as np
np.random.seed(2024)
rndImgs=np.random.choice(imgsList,4)
rndImgsimport matplotlib.pylab as plt
from PIL import Image
from scipy import ndimage as ndi
from skimage.segmentation import mark_boundaries
from torchvision.transforms.functional import to_tensor, to_pil_image
import torchdef show_img_mask(img, mask):if torch.is_tensor(img):img=to_pil_image(img)mask=to_pil_image(mask)img_mask=mark_boundaries(np.array(img), np.array(mask),outline_color=(0,1,0),color=(0,1,0))plt.imshow(img_mask)for fn in rndImgs:path2img = os.path.join(path2train, fn)path2annt= path2img.replace(".png", "_Annotation.png")img = Image.open(path2img)annt_edges = Image.open(path2annt)mask = ndi.binary_fill_holes(annt_edges) plt.figure()plt.subplot(1, 3, 1) plt.imshow(img, cmap="gray")plt.subplot(1, 3, 2) plt.imshow(mask, cmap="gray")plt.subplot(1, 3, 3) show_img_mask(img, mask)



plt.figure()
plt.subplot(1, 3, 1)
plt.imshow(img, cmap="gray")
plt.axis('off')plt.subplot(1, 3, 2)
plt.imshow(mask, cmap="gray")
plt.axis('off') plt.subplot(1, 3, 3)
show_img_mask(img, mask)
plt.axis('off')
![]()

# conda install conda-forge/label/cf202003::albumentations
from albumentations import (HorizontalFlip,VerticalFlip, Compose,Resize,
)h,w=128,192
transform_train = Compose([ Resize(h,w), HorizontalFlip(p=0.5), VerticalFlip(p=0.5), ])transform_val = Resize(h,w)创建自定义数据集
from torch.utils.data import Dataset
from PIL import Image
from torchvision.transforms.functional import to_tensor, to_pil_imageclass fetal_dataset(Dataset):def __init__(self, path2data, transform=None): imgsList=[pp for pp in os.listdir(path2data) if "Annotation" not in pp]anntsList=[pp for pp in os.listdir(path2train) if "Annotation" in pp]self.path2imgs = [os.path.join(path2data, fn) for fn in imgsList] self.path2annts= [p2i.replace(".png", "_Annotation.png") for p2i in self.path2imgs]self.transform = transformdef __len__(self):return len(self.path2imgs)def __getitem__(self, idx):path2img = self.path2imgs[idx]image = Image.open(path2img)path2annt = self.path2annts[idx]annt_edges = Image.open(path2annt)mask = ndi.binary_fill_holes(annt_edges) image= np.array(image)mask=mask.astype("uint8") if self.transform:augmented = self.transform(image=image, mask=mask)image = augmented['image']mask = augmented['mask'] image= to_tensor(image) mask=255*to_tensor(mask) return image, mask
fetal_ds1=fetal_dataset(path2train, transform=transform_train)
fetal_ds2=fetal_dataset(path2train, transform=transform_val)
img,mask=fetal_ds1[0]
print(img.shape, img.type(),torch.max(img))
print(mask.shape, mask.type(),torch.max(mask))show_img_mask(img, mask)
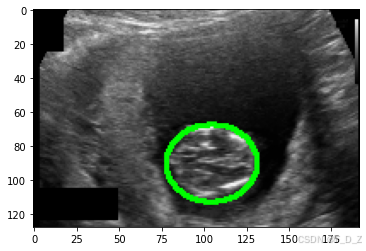
划分数据集
按照8:2的比例划分训练数据集和验证数据集
from sklearn.model_selection import ShuffleSplitsss = ShuffleSplit(n_splits=1, test_size=0.2, random_state=0)
indices=range(len(fetal_ds1))
for train_index, val_index in sss.split(indices):print(len(train_index))print("-"*10)print(len(val_index))
from torch.utils.data import Subsettrain_ds=Subset(fetal_ds1,train_index)
print(len(train_ds))
val_ds=Subset(fetal_ds2,val_index)
print(len(val_ds))
展示训练数据集示例图像
plt.figure(figsize=(5,5))
for img,mask in train_ds:show_img_mask(img,mask)break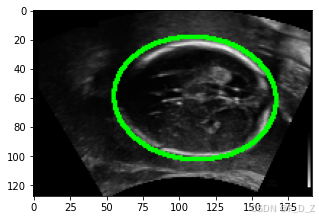
展示验证数据集示例图像
plt.figure(figsize=(5,5))
for img,mask in val_ds:show_img_mask(img,mask)break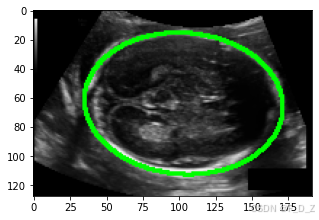
创建数据加载器
from torch.utils.data import DataLoader
train_dl = DataLoader(train_ds, batch_size=8, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=16, shuffle=False) for img_b, mask_b in train_dl:print(img_b.shape,img_b.dtype)print(mask_b.shape, mask_b.dtype)breakfor img_b, mask_b in val_dl:print(img_b.shape,img_b.dtype)print(mask_b.shape, mask_b.dtype)breaktorch.max(img_b)

![]()
搭建模型
基于编码器-解码器模型encoder–decoder model搭建分割任务模型
import torch.nn as nn
import torch.nn.functional as Fclass SegNet(nn.Module):def __init__(self, params):super(SegNet, self).__init__()C_in, H_in, W_in=params["input_shape"]init_f=params["initial_filters"] num_outputs=params["num_outputs"] self.conv1 = nn.Conv2d(C_in, init_f, kernel_size=3,stride=1,padding=1)self.conv2 = nn.Conv2d(init_f, 2*init_f, kernel_size=3,stride=1,padding=1)self.conv3 = nn.Conv2d(2*init_f, 4*init_f, kernel_size=3,padding=1)self.conv4 = nn.Conv2d(4*init_f, 8*init_f, kernel_size=3,padding=1)self.conv5 = nn.Conv2d(8*init_f, 16*init_f, kernel_size=3,padding=1)self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)self.conv_up1 = nn.Conv2d(16*init_f, 8*init_f, kernel_size=3,padding=1)self.conv_up2 = nn.Conv2d(8*init_f, 4*init_f, kernel_size=3,padding=1)self.conv_up3 = nn.Conv2d(4*init_f, 2*init_f, kernel_size=3,padding=1)self.conv_up4 = nn.Conv2d(2*init_f, init_f, kernel_size=3,padding=1)self.conv_out = nn.Conv2d(init_f, num_outputs , kernel_size=3,padding=1) def forward(self, x):x = F.relu(self.conv1(x))x = F.max_pool2d(x, 2, 2)x = F.relu(self.conv2(x))x = F.max_pool2d(x, 2, 2)x = F.relu(self.conv3(x))x = F.max_pool2d(x, 2, 2)x = F.relu(self.conv4(x))x = F.max_pool2d(x, 2, 2)x = F.relu(self.conv5(x))x=self.upsample(x)x = F.relu(self.conv_up1(x))x=self.upsample(x)x = F.relu(self.conv_up2(x))x=self.upsample(x)x = F.relu(self.conv_up3(x))x=self.upsample(x)x = F.relu(self.conv_up4(x))x = self.conv_out(x)return x params_model={"input_shape": (1,h,w),"initial_filters": 16, "num_outputs": 1,}model = SegNet(params_model)import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model=model.to(device)打印模型结构
print(model)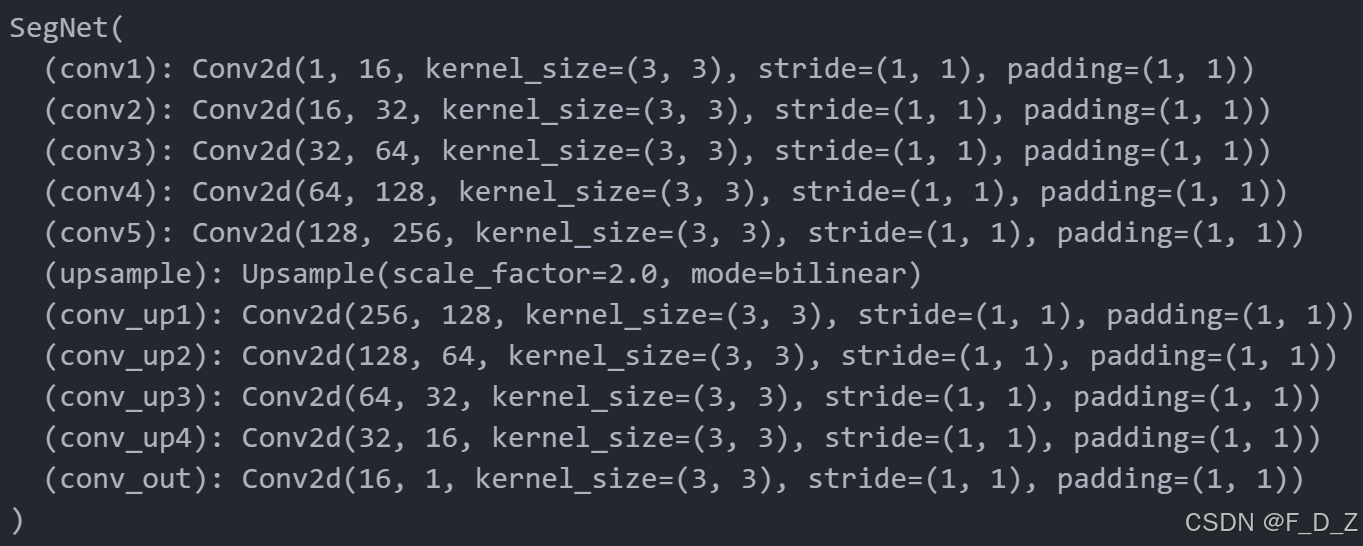
获取模型摘要
from torchsummary import summary
summary(model, input_size=(1, h, w))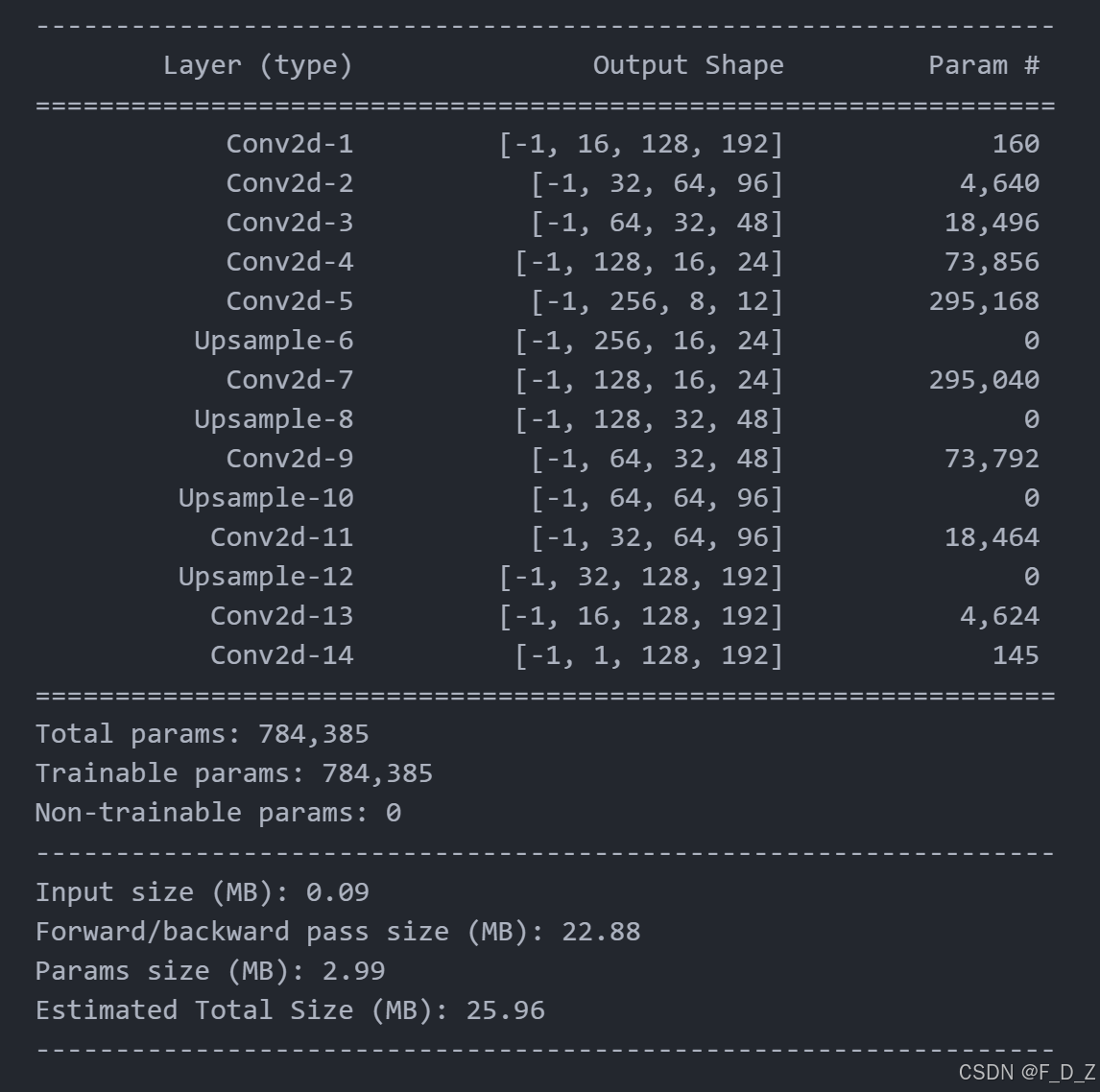
定义损失函数
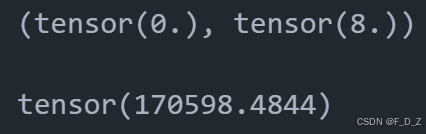
def dice_loss(pred, target, smooth = 1e-5):intersection = (pred * target).sum(dim=(2,3))union= pred.sum(dim=(2,3)) + target.sum(dim=(2,3)) dice= 2.0 * (intersection + smooth) / (union+ smooth) loss = 1.0 - dicereturn loss.sum(), dice.sum()import torch.nn.functional as Fdef loss_func(pred, target):bce = F.binary_cross_entropy_with_logits(pred, target, reduction='sum')pred= torch.sigmoid(pred)dlv, _ = dice_loss(pred, target)loss = bce + dlvreturn lossfor img_v,mask_v in val_dl:mask_v= mask_v[8:]breakfor img_t,mask_t in train_dl:breakprint(dice_loss(mask_v,mask_v))
loss_func(mask_v,torch.zeros_like(mask_v))
import torchvisiondef metrics_batch(pred, target):pred= torch.sigmoid(pred)_, metric=dice_loss(pred, target)return metricdef loss_batch(loss_func, output, target, opt=None): loss = loss_func(output, target)with torch.no_grad():pred= torch.sigmoid(output)_, metric_b=dice_loss(pred, target)if opt is not None:opt.zero_grad()loss.backward()opt.step()return loss.item(), metric_b定义优化器
from torch import optim
opt = optim.Adam(model.parameters(), lr=3e-4)from torch.optim.lr_scheduler import ReduceLROnPlateau
lr_scheduler = ReduceLROnPlateau(opt, mode='min',factor=0.5, patience=20,verbose=1)def get_lr(opt):for param_group in opt.param_groups:return param_group['lr']current_lr=get_lr(opt)
print('current lr={}'.format(current_lr))![]()
训练和评估模型
def loss_epoch(model,loss_func,dataset_dl,sanity_check=False,opt=None):running_loss=0.0running_metric=0.0len_data=len(dataset_dl.dataset)for xb, yb in dataset_dl:xb=xb.to(device)yb=yb.to(device)output=model(xb)loss_b, metric_b=loss_batch(loss_func, output, yb, opt)running_loss += loss_bif metric_b is not None:running_metric+=metric_bif sanity_check is True:breakloss=running_loss/float(len_data)metric=running_metric/float(len_data)return loss, metricimport copy
def train_val(model, params):num_epochs=params["num_epochs"]loss_func=params["loss_func"]opt=params["optimizer"]train_dl=params["train_dl"]val_dl=params["val_dl"]sanity_check=params["sanity_check"]lr_scheduler=params["lr_scheduler"]path2weights=params["path2weights"]loss_history={"train": [],"val": []}metric_history={"train": [],"val": []} best_model_wts = copy.deepcopy(model.state_dict())best_loss=float('inf') for epoch in range(num_epochs):current_lr=get_lr(opt)print('Epoch {}/{}, current lr={}'.format(epoch, num_epochs - 1, current_lr)) model.train()train_loss, train_metric=loss_epoch(model,loss_func,train_dl,sanity_check,opt)loss_history["train"].append(train_loss)metric_history["train"].append(train_metric)model.eval()with torch.no_grad():val_loss, val_metric=loss_epoch(model,loss_func,val_dl,sanity_check)loss_history["val"].append(val_loss)metric_history["val"].append(val_metric) if val_loss < best_loss:best_loss = val_lossbest_model_wts = copy.deepcopy(model.state_dict())torch.save(model.state_dict(), path2weights)print("Copied best model weights!")lr_scheduler.step(val_loss)if current_lr != get_lr(opt):print("Loading best model weights!")model.load_state_dict(best_model_wts) print("train loss: %.6f, dice: %.2f" %(train_loss,100*train_metric))print("val loss: %.6f, dice: %.2f" %(val_loss,100*val_metric))print("-"*10) model.load_state_dict(best_model_wts)return model, loss_history, metric_history
opt = optim.Adam(model.parameters(), lr=3e-4)# 定义学习率调度器,当验证集上的损失不再下降时,将学习率降低为原来的0.5倍,等待20个epoch后再次降低学习率
lr_scheduler = ReduceLROnPlateau(opt, mode='min',factor=0.5, patience=20,verbose=1)path2models= "./models/"# 判断path2models路径是否存在,如果不存在则创建该路径
if not os.path.exists(path2models):os.mkdir(path2models)params_train={"num_epochs": 100,"optimizer": opt,"loss_func": loss_func,"train_dl": train_dl,"val_dl": val_dl,"sanity_check": False,"lr_scheduler": lr_scheduler,"path2weights": path2models+"weights.pt",
}model,loss_hist,metric_hist=train_val(model,params_train)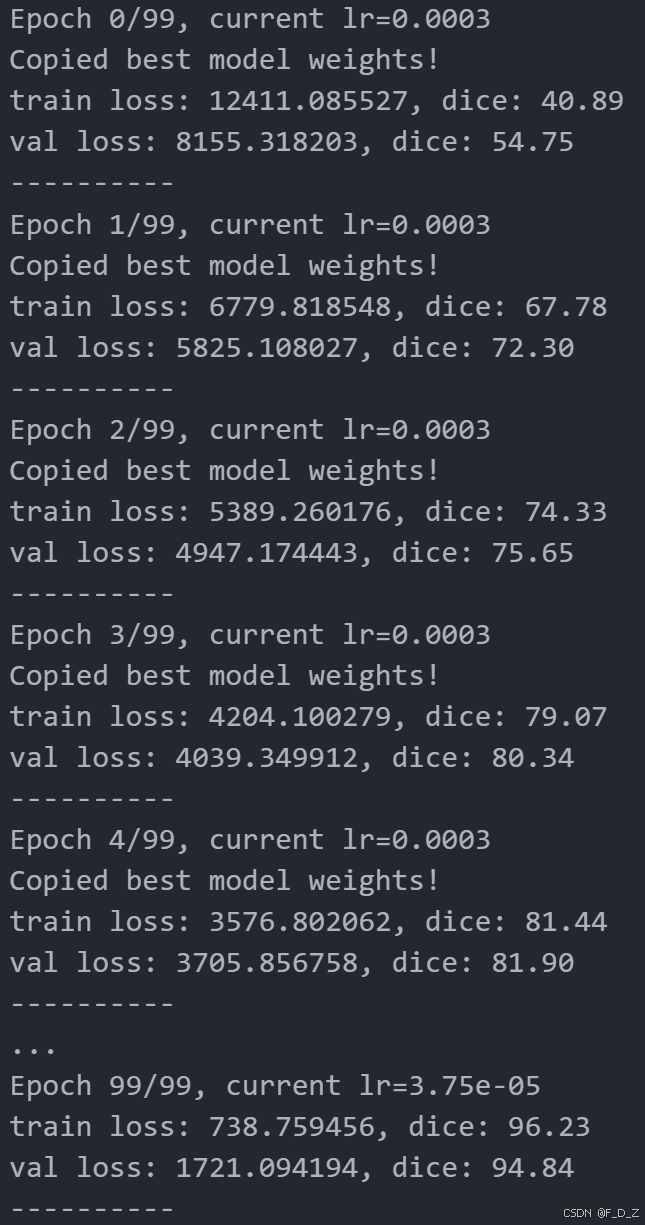
打印训练验证损失
num_epochs=params_train["num_epochs"]plt.title("Train-Val Loss")
plt.plot(range(1,num_epochs+1),loss_hist["train"],label="train")
plt.plot(range(1,num_epochs+1),loss_hist["val"],label="val")
plt.ylabel("Loss")
plt.xlabel("Training Epochs")
plt.legend()
plt.show() 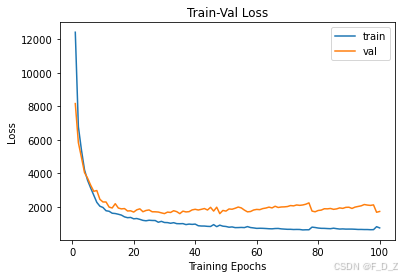
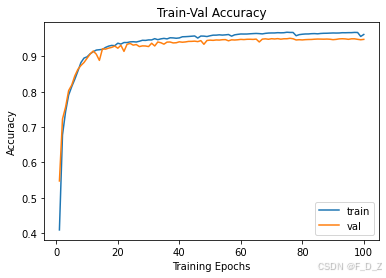
打印训练验证精度
# plot accuracy progress
plt.title("Train-Val Accuracy")
plt.plot(range(1,num_epochs+1),metric_hist["train"],label="train")
plt.plot(range(1,num_epochs+1),metric_hist["val"],label="val")
plt.ylabel("Accuracy")
plt.xlabel("Training Epochs")
plt.legend()
plt.show()