【自监督Re-ID】ICCV_2023_Oral | ISR论文阅读

Code![]() https://github.com/dcp15/ISR_%20ICCV2023_Oral
https://github.com/dcp15/ISR_%20ICCV2023_Oral
面向泛化行人再识别的身份导向自监督表征学习,清华大学
目录
导读
摘要
相关工作
DG ReID
用于ReID的合成数据
无监督表征学习
Identity-Seeking Representation Learning
结果
消融实验
导读
-
新角度:提出了从大规模无标注互联网行人视频中学习领域泛化的行人表征。
-
新方法:设计了新颖的自监督的学习框架以及可靠性引导的对比损失函数,有效学习到identity discrimination。所提方法具有出色的数据可扩展性。
-
高性能:所学表征展现出很强的域泛化能力和域迁移能力,具有很大的实际应用价值和潜力。
摘要
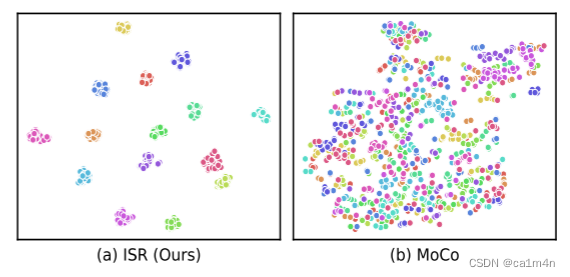
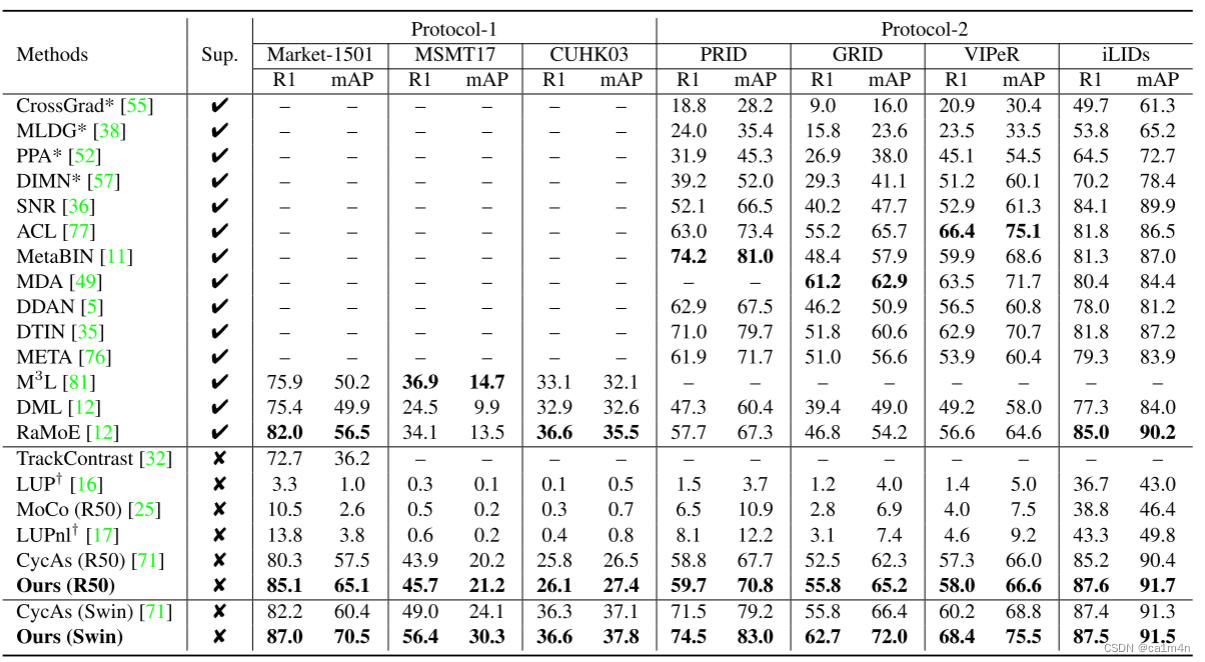
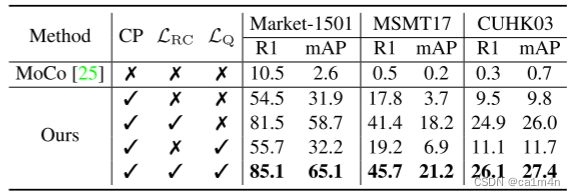
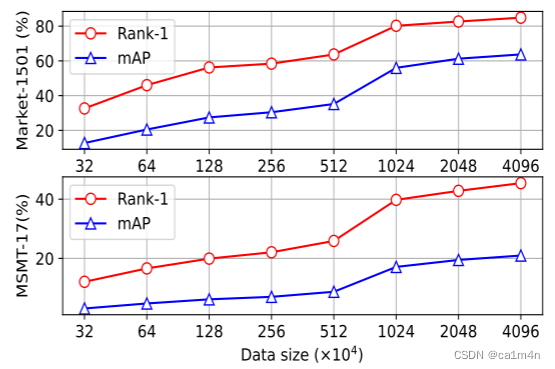
本文旨在从大规模视频中学习一种无需任何注释的域泛化(DG)行人再识别(ReID)表示。由于标注成本高,先前的DG ReID方法使用有限的标注数据进行训练,这限制了进一步发展。为了克服数据和注释的障碍,我们建议使用大规模的无监督数据进行训练。关键问题在于如何挖掘身份信息。为此,我们提出了一种ISR(Identity-seeking Self-supervised Representation learning)方法。ISR将实例关系建模当做最大权重二分匹配问题,从帧间图像构建正样本对。进一步提出了一种可靠性引导的对比损失,以抑制噪声正样本对的不利影响,确保可靠的正样本对主导学习过程。ISR的训练成本与数据大小近似呈线性关系,因此可以利用大规模数据进行训练。所学习的表示表现出很强的泛化能力。在没有人为注释和微调的情况下,ISR在Market-1501上获得了87.0%的Rank-1,在MSMT17上获得了56.4%的Rank-1,分别比最佳有监督域泛化方法高出5.0%和19.5%。
相关工作
DG ReID
领域通用的人物识别(Domain Generalizable ReID)旨在在源领域上学习一个强大的模型,并直接在未见过的目标领域上进行测试,而无需进行微调处理。因其在实际应用中的巨大潜力而受到广泛关注。DIMN设计了一个域不变映射网络来学习元学习管道下的域不变表示。MetaBIN和SNR研究了归一化层或模块,以提高模型的泛化能力。RaMoE利用目标域和多个源域之间的相关性来提高模型的泛化能力。MDA将源和目标特征分布与先前的分布对齐。这些方法是用小规模领域匮乏的标记数据进行训练的。与他们不同的是,我们的目标是从大规模领域多样的未标记数据中学习DG ReID模型。
用于ReID的合成数据
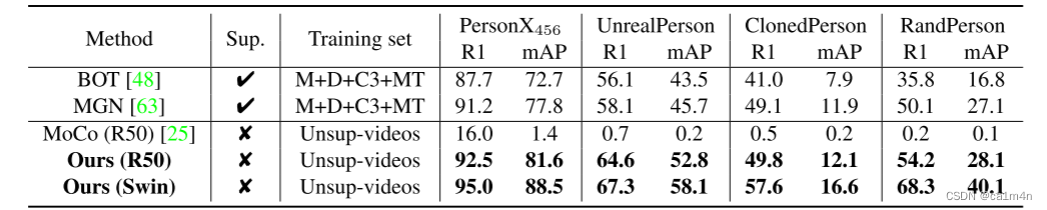
ReID模型的性能受到从真实世界收集标注数据的高昂成本的限制。为了应对这一挑战,一些方法已经转向使用合成数据(synthetic data)。值得注意的是,PersonX包含1266个ID,其中273456张图像是从各个角度拍摄的,能够探索视角对ReID系统的影响。RandPerson提供了8000个身份,其中有来自19台摄像机的228655张图像,而UnrealPerson提供了3000个身份,包括来自34台摄像机的120000张图像;ClonedPerse包括来自24台摄像机的5621个身份和887766张图像。这些合成数据集已被证明对监督学习有价值,因为它们增强了ReID模型的泛化能力。DomainMix [1] 进一步证实,在训练期间将标记的合成数据与未标记的真实世界数据相结合是DG ReID的一个有前途的方向。然而,合成数据和真实世界的数据之间仍然存在巨大的领域差距,阻碍了在合成数据上训练的模型无缝应用于真实的现实世界场景。为了弥补这种差异,我们建议使用大量未标记的真实世界数据进行训练。
[1] Wenhao Wang, Shengcai Liao, Fang Zhao, Kangkang Cui, and Ling Shao. Domainmix: Learning generalizable person re-identification without human annotations. In BMVC, 2021. 3
无监督表征学习
一些主流的无监督表征学习方法(MoCo, SimCLR, BYOL),如果被直接应用于ReID,则只能学习预训练模型,这在直接测试时显示出极低的准确性。核心原因是,它们将一张图像的两个不同视图视为正样本对,或者对图像中的掩码像素进行重建,从而实现了实例区分(instance discrimination)。这与身份区分(identity discrimination)的ReID目标所矛盾。与它们不同,我们将同一ID的帧间图像视为正样本对,来达到身份区分的目标。一项密切相关的工作是CycAs(同团队的工作)及其改进版本。大概意思是作者针对CycAs方法的弱点提出了一种新方法,通过挖掘正样本对和抑制噪声来提供更鲁棒和通用的人物再识别表示学习的解决方案。
Identity-Seeking Representation Learning
身份导向的自监督表征学习
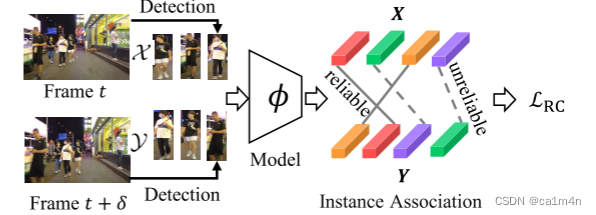
(1)构建正样本对
基于最大权二分图匹配,在邻近帧中构建跨帧正样本对。
(2)抑制噪声正样本对
计算每个正样本对的可靠性,利用可靠性来引导学习对比损失,进而抑制噪声正样本对的影响。
可靠性计算:,对比损失:
结果
消融实验
更多细节在论文