通过解读yolov5_gpu_optimization学习如何使用onnx_surgon
onnx实战一: 解析yolov5 gpu的onnx优化案例:
这是一个英伟达的仓库, 这个仓库的做法就是通过用gs对onnx进行修改减少算子然后最后使用TensorRT插件实现算子, 左边是优化过的, 右边是原版的。 通过这个案例理解原版的onnx的导出流程然后我们看英伟达是怎么拿gs来优化这个onnx
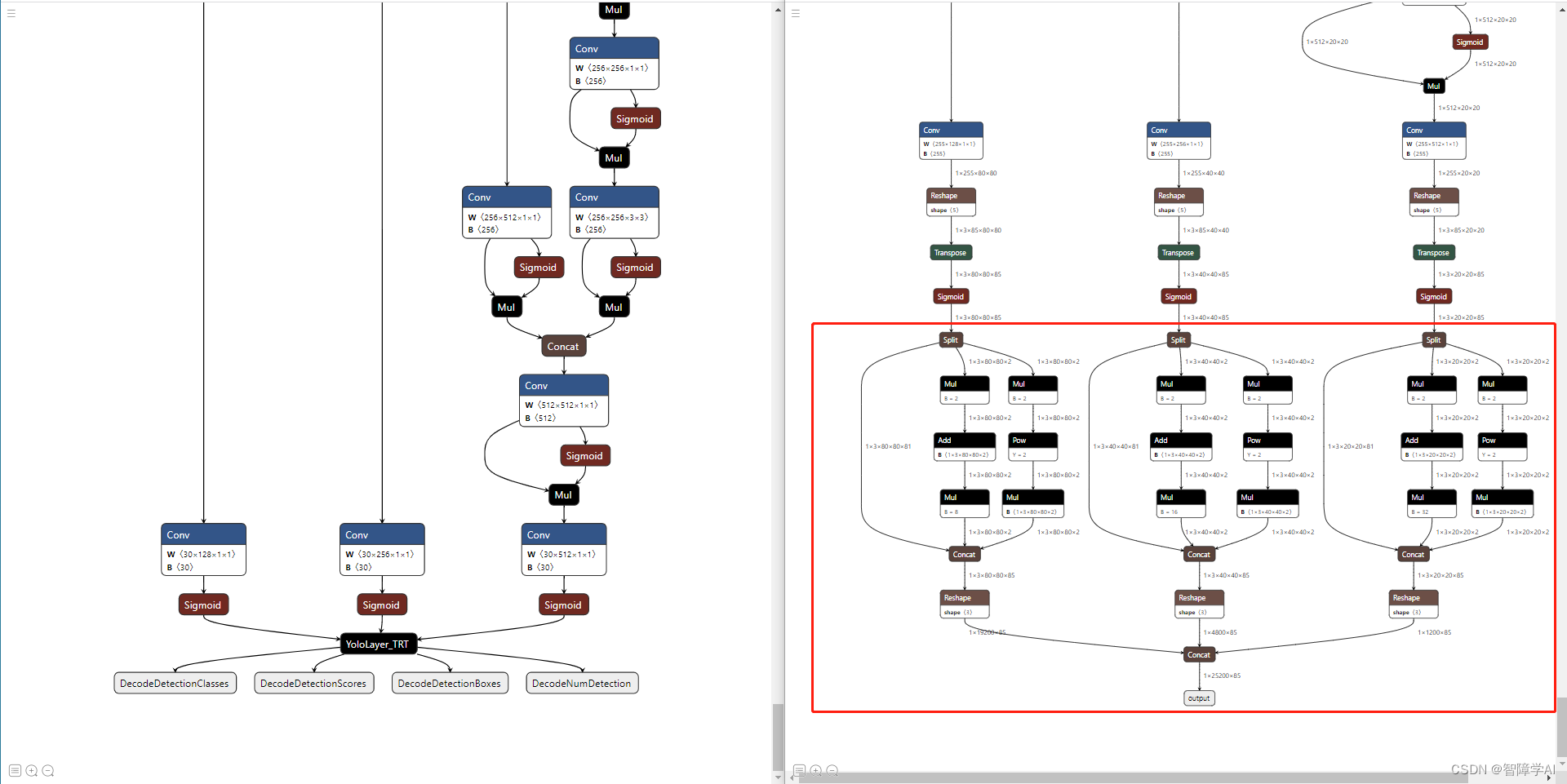
原版的export_onnx函数
先看torch.onnx.export函数的参数解释:
-
model: 要导出的PyTorch模型, 在工程中这里输入的是训练好的pt文件
-
im: 这里对应torch.onnx.export的args, 这个是用作模型输入的示例张量。这帮助ONNX确定输入的形状和类型。
-
f: 输出ONNX模型的文件名或文件对象, 用来指定导出模型的路径和文件名。
-
verbose (默认为
False): 如果设置为True,则会打印出模型导出时的详细日志。 -
opset_version: 导出的ONNX模型的操作集版本。不同的版本可能支持不同的操作。
-
training:
torch.onnx.TrainingMode.TRAINING: 表示模型处于训练模式。torch.onnx.TrainingMode.EVAL: 表示模型处于评估模式。
-
do_constant_folding (默认为
True): 当设置为True,导出过程中会尝试简化模型,将常量子图折叠为一个常量节点。 -
input_names: 为模型的输入提供名称, 参数规定是数组
-
output_names: 为模型的输出提供名称, 参数规定是数组
-
dynamic_axes: 为模型的输入/输出定义动态轴。对于那些维度在推理时可能会发生变化的情况(例如,批处理大小),此参数允许指定哪些轴是动态的。这里images是输入, 本来是1x3x640x640, 这里通过指定把0, 2, 3维度变成了动态轴的输入, 第二个维度是3这个还是固定的。如果使用动态, 可以输入任意数量和任意大小的图片而不是规定的单张640x640
'images': 对应的张量名称。0: 'batch': 表示第0个维度(即批处理维度)是动态的,并命名为’batch’。2: 'height': 表示第2个维度(即图像的高度)是动态的。3: 'width': 表示第3个维度(即图像的宽度)是动态的。
'output': 对应的张量名称。0: 'batch': 表示第0个维度(即批处理维度)是动态的。1: 'anchors': 表示第1个维度是动态的。
- dynamic (没有在给定的函数调用中明确给出,但可以从上下文推断):
True: 如果你想让某些轴动态,你可以设置此参数为True。False: 表示不使用动态轴。
导出了onnx之后开始做onnxsim
-
model_onnx, check = onnxsim.simplify(...):使用onnxsim的simplify方法简化模型。它返回简化后的onnx模型和一个布尔值check,表示简化是否成功。 -
在对动态输入的onnx导出的时候,
dynamic_input_shape=dynamic是不够的,还要把输入给他,让onnxsim更加谨慎的优化onnx, 确保满足我们给他的输出,所以这里多了一个input_shapes={'images': list(im.shape)} if dynamic else None
def export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):# YOLOv5 ONNX exporttry:check_requirements(('onnx',))import onnxLOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')f = file.with_suffix('.onnx')torch.onnx.export(model,im,f,verbose=False,opset_version=opset,training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,do_constant_folding=not train,input_names=['images'],output_names=['output'],dynamic_axes={'images': {0: 'batch',2: 'height',3: 'width'}, # shape(1,3,640,640)'output': {0: 'batch',1: 'anchors'} # shape(1,25200,85)} if dynamic else None)# Checksmodel_onnx = onnx.load(f) # load onnx modelonnx.checker.check_model(model_onnx) # check onnx model# Metadatad = {'stride': int(max(model.stride)), 'names': model.names}for k, v in d.items():meta = model_onnx.metadata_props.add()meta.key, meta.value = k, str(v)onnx.save(model_onnx, f)# Simplifyif simplify:try:check_requirements(('onnx-simplifier',))import onnxsimLOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')model_onnx, check = onnxsim.simplify(model_onnx,dynamic_input_shape=dynamic,input_shapes={'images': list(im.shape)} if dynamic else None)assert check, 'assert check failed'onnx.save(model_onnx, f)except Exception as e:LOGGER.info(f'{prefix} simplifier failure: {e}')LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')return fexcept Exception as e:LOGGER.info(f'{prefix} export failure: {e}')
更改过的export_onnx函数
- 首先是把onnx的输出由一个改成了3个, 然后指定动态输出, 因为有多个输出,全部都把他们的batch, width, height指定为动态的,满足不同的输入输出。 不过这边的问题是看起来是只改了最后的输出,但是前面在yolo.py的地方已经把sigmoid后面的计算都干掉了, 因为后面的计算映射了一堆的算子导致了在计算图太冗余
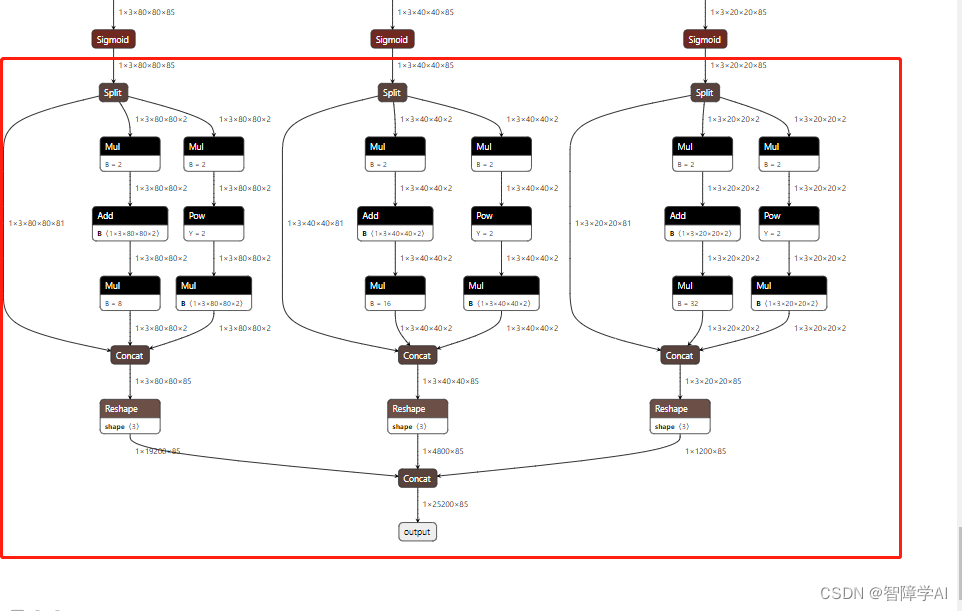
这一坨全部不要了就保留sigmoid就可以了,然后就是直接硬编码t就是int32
diff --git a/models/yolo.py b/models/yolo.py
index 02660e6..c810745 100644
--- a/models/yolo.py
+++ b/models/yolo.py
@@ -55,29 +55,15 @@ class Detect(nn.Module):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # conv
- bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
- x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
-
- if not self.training: # inference
- if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
- self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
-
- y = x[i].sigmoid()
- if self.inplace:
- y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
- y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
- else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
- xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
- xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
- wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
- y = torch.cat((xy, wh, conf), 4)
- z.append(y.view(bs, -1, self.no))
-
- return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
+ y = x[i].sigmoid()
+ z.append(y)
+ return zdef _make_grid(self, nx=20, ny=20, i=0):d = self.anchors[i].device
- t = self.anchors[i].dtype
+ # t = self.anchors[i].dtype
+ # TODO(tylerz) hard-code data type to int
+ t = torch.int32shape = 1, self.na, ny, nx, 2 # grid shapey, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
--
2.36.0
-
onnxsim这里跟之前是一样的, 也是直接onnxsim, 如果动态的要给输出给onnxsim然后让它更加的谨慎,满足需求
-
这后面的重点是增加了用onnx-surgon来更改onnx, 先把整个onnx导入进来,然后使用然后用Variable做模型的输出, 这里做四个模型输出, 分别是
DecodeNumDetection,DecodeDetectionBoxes,DecodeDetectionScores,DecodeDetectionClasses -
然后设置一个attrs, gs设置的attrs使用字典的格式弄的。这里设置max_stride, num_classes, anchors, prenms_score_threshold四个属性,这些属性的操作会在TensorRT中实现的
-
decode_plugin是中间的节点,这个节点上面是inputs, 下面是四个不同的decodes, 这里就是把这个nodes做出来了
-
然后在整体的网络上添加这个节点,然后再把输出改成这个节点的输出保持一致,在计算图中把其他的节点claenup()清洁掉, 最后导出
def export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):# YOLOv5 ONNX export# try:check_requirements(('onnx',))import onnxLOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')f = file.with_suffix('.onnx')print(train)torch.onnx.export(model,im,f,verbose=False,opset_version=opset,training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,do_constant_folding=not train,input_names=['images'],output_names=['p3', 'p4', 'p5'],dynamic_axes={'images': {0: 'batch',2: 'height',3: 'width'}, # shape(1,3,640,640)'p3': {0: 'batch',2: 'height',3: 'width'}, # shape(1,25200,4)'p4': {0: 'batch',2: 'height',3: 'width'},'p5': {0: 'batch',2: 'height',3: 'width'}} if dynamic else None)# Checksmodel_onnx = onnx.load(f) # load onnx modelonnx.checker.check_model(model_onnx) # check onnx model# Simplifyif simplify:# try:check_requirements(('onnx-simplifier',))import onnxsimLOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')model_onnx, check = onnxsim.simplify(model_onnx,dynamic_input_shape=dynamic,input_shapes={'images': list(im.shape)} if dynamic else None)assert check, 'assert check failed'onnx.save(model_onnx, f)# except Exception as e:# LOGGER.info(f'{prefix} simplifier failure: {e}')# add yolov5_decoding:import onnx_graphsurgeon as onnx_gsimport numpy as npyolo_graph = onnx_gs.import_onnx(model_onnx)p3 = yolo_graph.outputs[0]p4 = yolo_graph.outputs[1]p5 = yolo_graph.outputs[2]decode_out_0 = onnx_gs.Variable("DecodeNumDetection",dtype=np.int32)decode_out_1 = onnx_gs.Variable("DecodeDetectionBoxes",dtype=np.float32)decode_out_2 = onnx_gs.Variable("DecodeDetectionScores",dtype=np.float32)decode_out_3 = onnx_gs.Variable("DecodeDetectionClasses",dtype=np.int32)decode_attrs = dict()decode_attrs["max_stride"] = int(max(model.stride))decode_attrs["num_classes"] = model.model[-1].ncdecode_attrs["anchors"] = [float(v) for v in [10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326]]decode_attrs["prenms_score_threshold"] = 0.25decode_plugin = onnx_gs.Node(op="YoloLayer_TRT",name="YoloLayer",inputs=[p3, p4, p5],outputs=[decode_out_0, decode_out_1, decode_out_2, decode_out_3],attrs=decode_attrs)yolo_graph.nodes.append(decode_plugin)yolo_graph.outputs = decode_plugin.outputsyolo_graph.cleanup().toposort()model_onnx = onnx_gs.export_onnx(yolo_graph)d = {'stride': int(max(model.stride)), 'names': model.names}for k, v in d.items():meta = model_onnx.metadata_props.add()meta.key, meta.value = k, str(v)onnx.save(model_onnx, f)LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')return f# except Exception as e:# LOGGER.info(f'{prefix} export failure: {e}')