Datax从mysql同步数据到HDFS
在实际使用Datax的时候,比较常用的是同步业务数据(mysql中的数据)到HDFS来实现数仓的创建,那么怎么实现呢?我们一步步来实现(基于Datax 3.0.0)
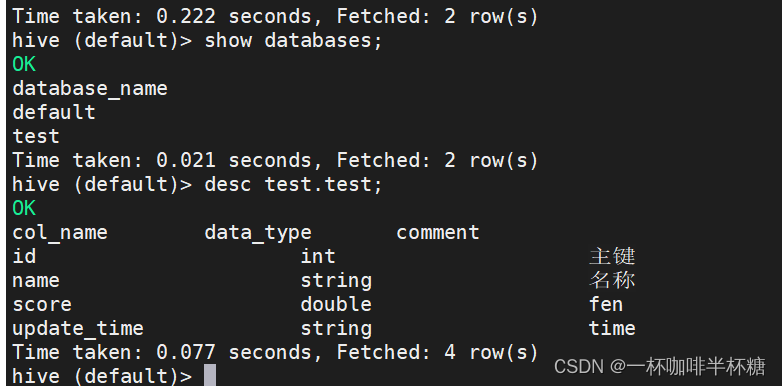
1、检查环境,需要安装完一个Datax,一个mysql,安装hadoop以及hive
2、在mysql中创建源表,并在原表中插入数据,我们的目标是把源表的mysql数据同步到HDFS中,我们当前测试表如下
源数据库:test
源表结构:
CREATE TABLE `test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
`score` decimal(10,0) DEFAULT NULL,
`update_time` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
插入数据如下

3、在datax同步之前需要在hive上创建数据库和表,否则会报错,创建语句如下,注意分隔符用\001用来避免数据中含有分隔符,ORC是最后存储hive的格式,我们创建表的时候也要是ORC格式,目前datax插入HDFS只支持用户配置为"text"或"orc"。
create database test
CREATE TABLE IF NOT EXISTS test.test(id int comment '主键',name string comment '名称', score double comment 'fen' , update_time string comment 'time') COMMENT 'Employee details' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n' STORED AS ORC ;
4、我们在安装Datax的服务器上创建json文件,我们文件创建在/opt/datax/job目录下,开发者可自定义保存文件路径
vim mysql2hdfs.json
文件内容如下(需要修改的或者重要的已标红,大家直接修改即可)
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"connection": [
{
"querySql": [
"select id,name,score,update_time from test;"
],
"jdbcUrl": [
"jdbc:mysql://node01:3306/datax"
]
}
]
}
},"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "name",
"type": "string"
},
{
"name": "score",
"type": "double"
},
{
"name": "update_time",
"type": "string"
}
],
"defaultFS": "hdfs://node01:8020",
"fieldDelimiter": ",",
"fileName": "test",
"fileType": "orc",
"path": "/user/hive/warehouse/test.db/test",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
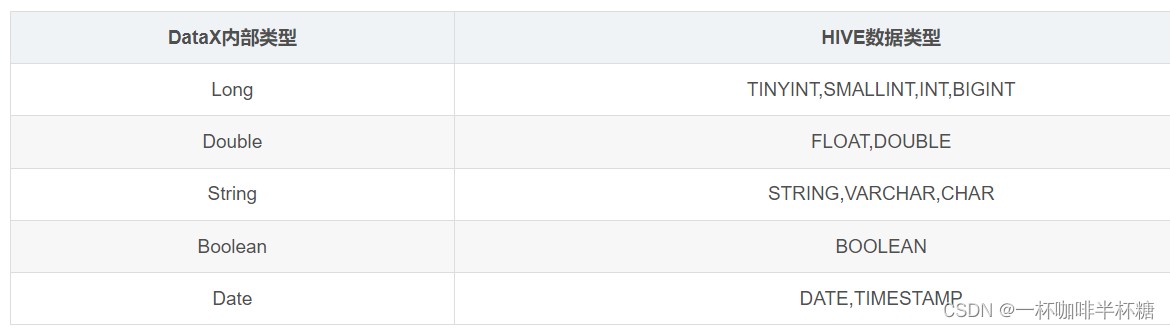
注意类型如下

标红解释如下:
jdbcUrl:数据库的jdbcurl链接
username:mysql用户名
password:mysql用户登陆密码
querySql:mysqlreader中的参数,用作自定义sql,根据sql的灵活编写实现数据的增量、全量、特定列数据的同步,注意需要sql和mysqlwriter中的column字段数量、名称、类型需要对应上
defaultFS:Hadoop hdfs文件系统namenode节点地址。格式:hdfs://ip:端口;例如:hdfs://127.0.0.1:9000
fieldDelimiter:hdfswriter写入时的字段分隔符
fileName:HdfsWriter写入时的文件名,实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名
fileType:文件的类型,目前只支持用户配置为"text"或"orc"
path:存储到Hadoop hdfs文件系统的路径信息,HdfsWriter会根据并发配置在Path目录下写入多个文件。为与hive表关联,请填写hive表在hdfs上的存储路径。例:Hive上设置的数据仓库的存储路径为:/user/hive/warehouse/ ,已建立数据库:test,表:hello;则对应的存储路径为:/user/hive/warehouse/test.db/hello
writeMode:hdfswriter写入前数据清理处理模式,有以下3种:
1) append,写入前不做任何处理,DataX hdfswriter直接使用filename写入,并保证文件名不冲突。
2)nonConflict,如果目录下有fileName前缀的文件,直接报错。
3)truncate,如果目录下有fileName前缀的文件,先删除后写入。
5、执行Datax,首先去到Datax的bin目录,然后执行
python /opt/datax/bin/datax.py /opt/datax/job/mysql2hdfs.json
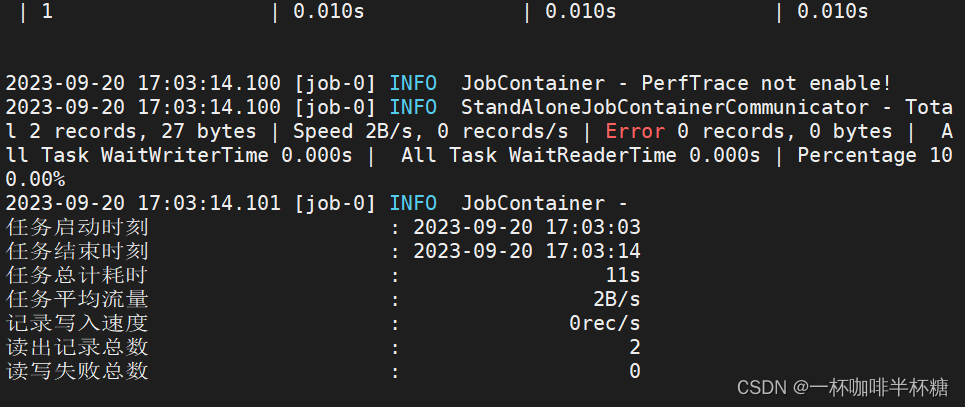
6、看到如下则证明执行成功
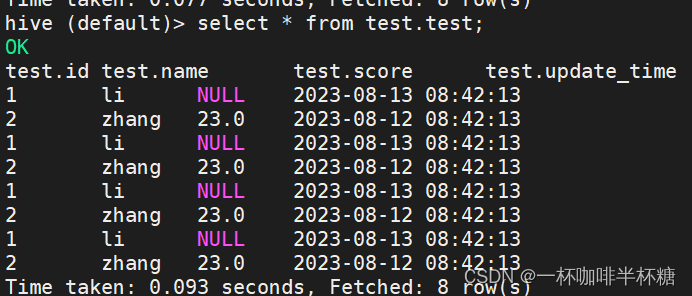
7、在hive种查询数据